什么是均值的标准误差?
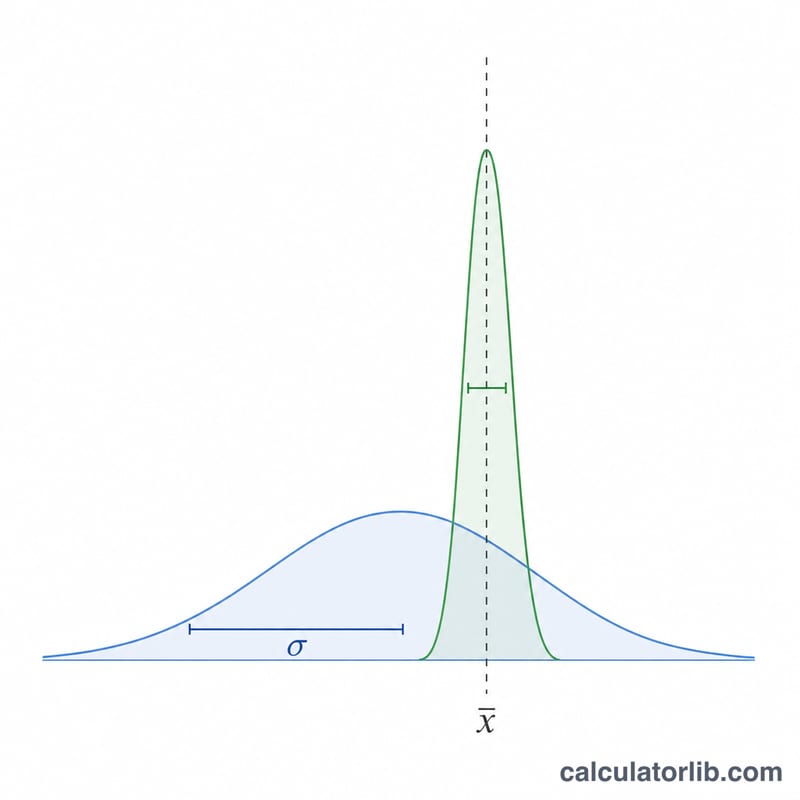
均值的标准误差(英文缩写 SEM 或 SE,中文常称"标准误")用来衡量样本均值与真实总体均值之间可能存在多大的偏差。标准差描述的是单个数据点的离散程度,而标准误反映的则是你对均值这一估计值的精确度。样本量越大,标准误越小,也就意味着你得到的均值估计越可靠。
如何使用本计算器
只需输入两个数值:样本标准差(s)和样本量(n)。计算器会用标准差除以样本量的平方根,得出均值的标准误差。这是一条通用的统计学公式,适用于各个领域——生物学、金融、心理学、工程学等等都能用到。
公式解析
计算公式为 $$\text{SE} = \frac{\text{Standard Deviation }(s)}{\sqrt{\text{Sample Size }(n)}}$$ 其中,s 表示样本标准差,n 表示观测值的数量。由于 \(n\) 位于平方根之下,因此若想把标准误缩小一半,就必须把样本量扩大到原来的四倍——这一点在设计研究方案时非常有参考价值。

实例演算
假设某个样本的标准差为 15,包含 25 个观测值。那么标准误为 $$15 \div \sqrt{25} = 15 \div 5 = 3$$ 也就是说,样本均值与真实总体均值之间的估计偏差大约在 3 个单位以内(即一个标准误的范围)。
常见问题
标准差和标准误有什么区别? 标准差衡量的是各个数据点之间的离散程度;而标准误衡量的是样本均值这一估计值的精确程度。
样本量越大,标准误就越小吗? 是的。随着 \(n\) 增大,\(\sqrt{n}\) 也随之增大,标准误便会缩小,从而让均值的估计更加精确。
可以改用总体标准差吗? 如果你已知真实的总体标准差(σ),那么可以用 \(\text{SE} = \sigma / \sqrt{n}\) 来计算。不过在大多数情况下,我们手头只有样本标准差 \(s\)。