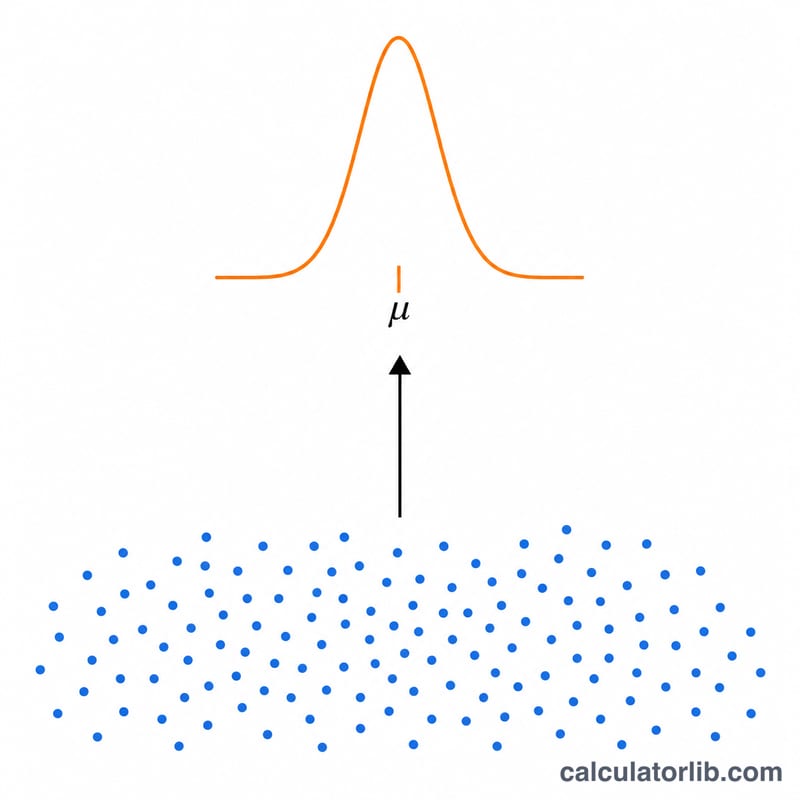
평균의 표준오차란?
평균의 표준오차(SEM, Standard Error of the Mean)는 표본 평균이 실제 모집단 평균에서 얼마나 벗어날 수 있는지를 나타내는 값입니다. 표준편차가 개별 데이터들이 얼마나 흩어져 있는지를 보여 준다면, 표준오차는 우리가 구한 평균값이 얼마나 정밀한 추정치인지를 알려 줍니다. 표본 크기가 클수록 표준오차는 작아지며, 이는 곧 표본 평균이 모집단 평균을 더 믿을 만하게 추정하고 있다는 뜻입니다.
계산기 사용법
표본 표준편차(s)와 표본 크기(n)를 입력하면 결과가 바로 나타납니다. 계산기는 표준편차를 표본 크기의 제곱근으로 나누어 값을 구합니다. 만약 원자료(raw data)만 가지고 있다면 먼저 표준편차를 구한 뒤, 그 값과 관측 개수를 함께 입력하면 됩니다.
공식 설명
공식은 다음과 같습니다.
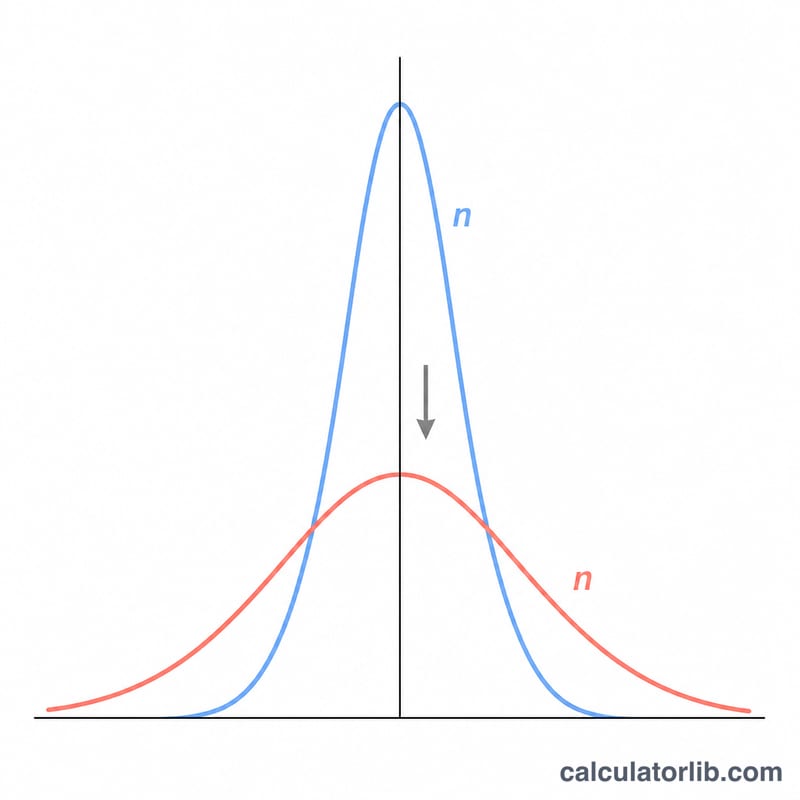
$$\text{SEM} = \frac{\text{Std. Dev. (s)}}{\sqrt{\text{Sample Size (n)}}}$$여기서 \(s\)는 표본 표준편차, \(n\)은 관측값의 개수입니다. n이 제곱근 안에 들어가기 때문에, 표본 크기를 4배로 늘려도 표준오차는 절반으로밖에 줄지 않습니다. 연구를 설계할 때 기억해 두면 유용한 경험 법칙입니다.
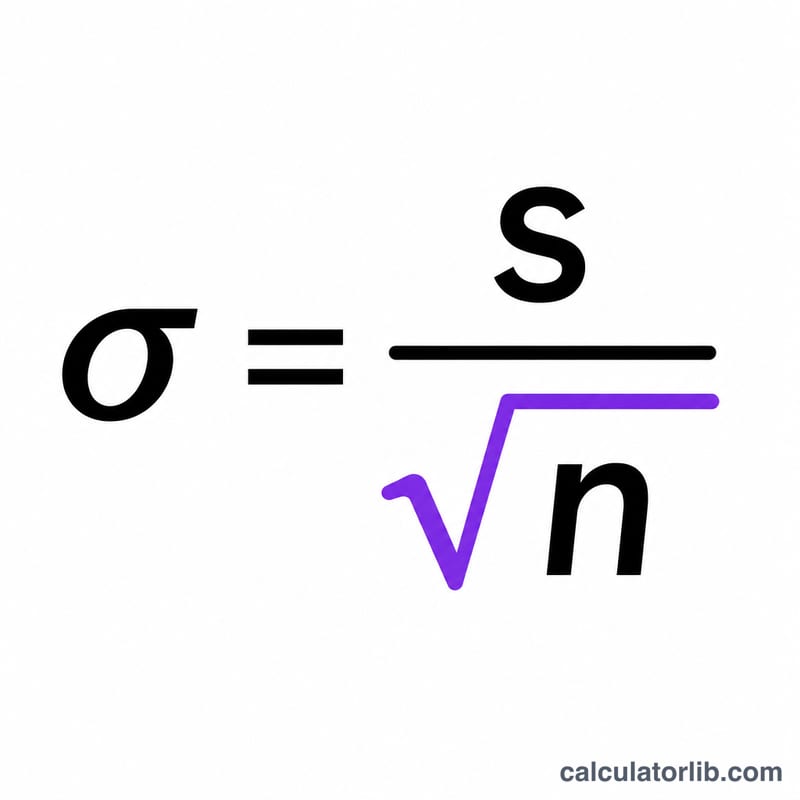
예제로 살펴보기
측정값 25개로 이루어진 표본의 표준편차가 15라고 가정해 봅시다. SEM은 다음과 같습니다.
$$\text{SEM} = \frac{15}{\sqrt{25}} = \frac{15}{5} = 3$$즉, 표본 평균은 3 단위의 표준오차로 추정됩니다. 흔히 사용하는 95% 신뢰구간은 대략 \(\text{평균} \pm 1.96 \times 3\) 으로 계산할 수 있습니다.
자주 묻는 질문
SEM과 표준편차는 같은 건가요? 아닙니다. 표준편차는 개별 데이터 사이의 변동성을 나타내고, SEM은 표본 평균이 모집단 평균을 추정할 때 가지는 변동성을 나타냅니다.
왜 표본이 커지면 SEM이 작아지나요? 더 많은 관측값을 평균 내면 무작위 오차가 줄어들어, 평균이 더 안정적인 추정치가 되기 때문입니다.
모집단 표준편차만 알고 있다면 어떻게 하나요? 그 값을 s 대신 그대로 사용하면 됩니다. 공식은 여전히 \(s / \sqrt{n}\) 입니다.