Что такое стандартная ошибка среднего?
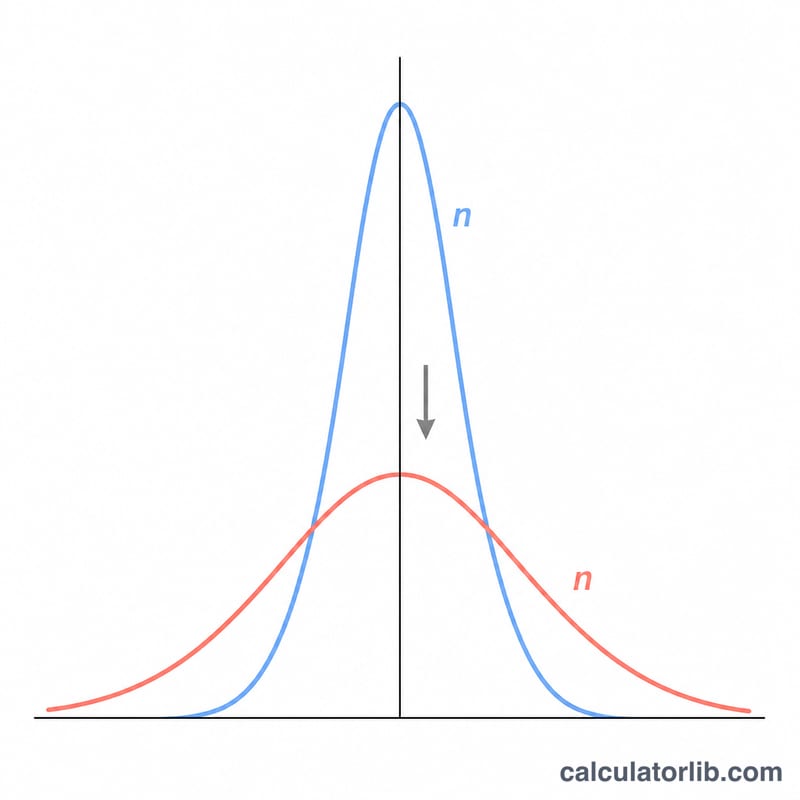
Стандартная ошибка среднего (SEM) показывает, насколько среднее значение по выборке может отклоняться от истинного среднего по всей генеральной совокупности. Если стандартное отклонение описывает разброс отдельных наблюдений, то SEM характеризует точность вашей оценки среднего. Чем больше выборка, тем меньше стандартная ошибка — а значит, выборочное среднее точнее отражает реальное среднее по совокупности.
Как пользоваться калькулятором
Введите выборочное стандартное отклонение (s) и объём выборки (n) — результат появится сразу. Калькулятор делит стандартное отклонение на квадратный корень из объёма выборки. Если у вас есть только «сырые» данные, сначала вычислите стандартное отклонение, а затем впишите его сюда вместе с количеством наблюдений.
Разбор формулы
Формула выглядит так: $$\text{SEM} = \frac{\text{Std. Dev. (s)}}{\sqrt{\text{Sample Size (n)}}}$$ Здесь s — выборочное стандартное отклонение, а n — количество наблюдений. Поскольку \(n\) стоит под корнем, увеличение выборки в четыре раза уменьшает стандартную ошибку лишь вдвое — это полезное правило при планировании исследований.
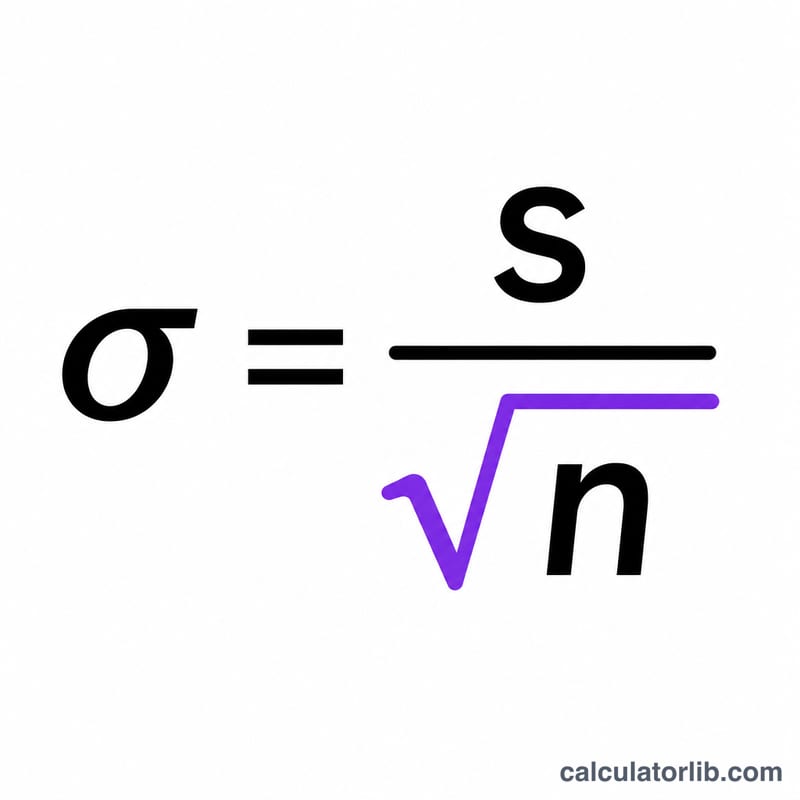
Пример расчёта
Допустим, выборка из 25 измерений имеет стандартное отклонение 15. Тогда $$\text{SEM} = \frac{15}{\sqrt{25}} = \frac{15}{5} = 3$$ То есть среднее по выборке оценивается со стандартной ошибкой в 3 единицы. Привычный 95%-й доверительный интервал в этом случае составит примерно среднее \(\pm\, 1{,}96 \times 3\).
Частые вопросы
SEM и стандартное отклонение — это одно и то же? Нет. Стандартное отклонение измеряет разброс самих данных, а SEM — изменчивость выборочного среднего как оценки среднего по генеральной совокупности.
Почему SEM уменьшается с ростом выборки? Усреднение большего числа наблюдений снижает случайную ошибку, поэтому среднее становится более устойчивой оценкой.
А если я знаю только стандартное отклонение генеральной совокупности? Его тоже можно подставить вместо \(s\) — формула остаётся прежней: \(s / \sqrt{n}\).