Что такое функция активации Leaky ReLU?
Leaky ReLU (Leaky Rectified Linear Unit, «дырявый» выпрямленный линейный блок) — одна из самых востребованных функций активации в глубоких нейронных сетях. Как и обычный ReLU, она пропускает положительные значения без изменений, но отрицательные входы не обнуляет, а умножает на небольшой коэффициент наклона alpha. Благодаря этому даже при отрицательных пре-активациях сохраняется небольшой градиент, что помогает избежать проблемы «умирающего ReLU», когда нейроны застревают на нуле и перестают обучаться.
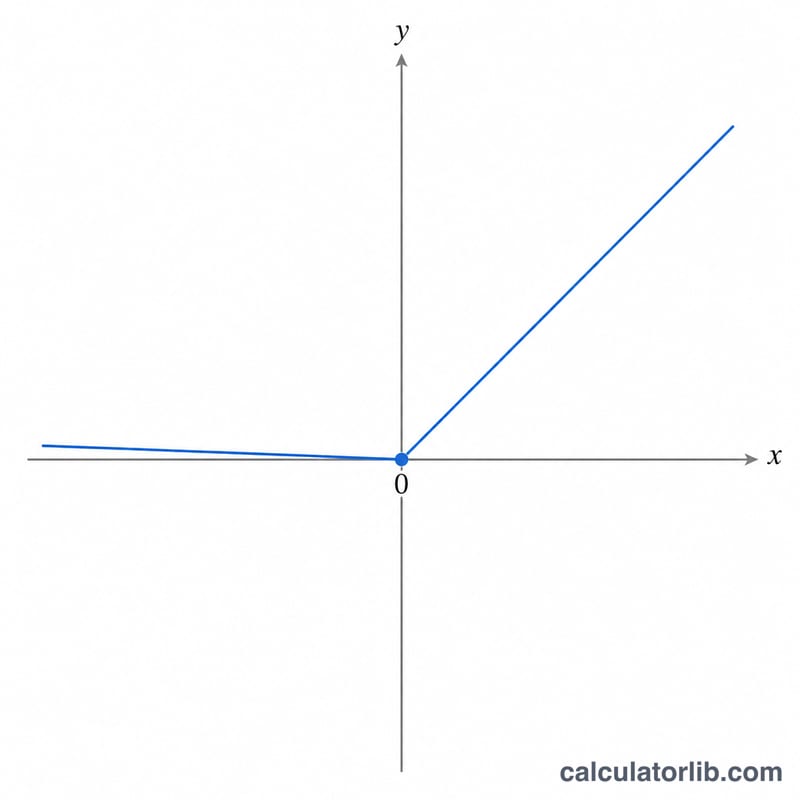
Формула
Для входного значения \(x\) и наклона утечки \(\alpha\) выход вычисляется так:
$$f(\text{x}) = \begin{cases} \text{x} & \text{if } \text{x} > 0 \\[0.5em] \alpha \cdot \text{x} & \text{if } \text{x} \le 0 \end{cases}$$По умолчанию коэффициент утечки \(\alpha = 0{,}01\). Стоит отметить два частных случая: при \(\alpha = 0\) функция превращается в стандартный ReLU (\(\max(0, x)\)), а при \(\alpha = 1\) вырождается в прямую тождества \(f(x) = x\).
Как пользоваться калькулятором
Введите начальное значение \(x\), шаг между точками, количество генерируемых точек и наклон утечки \(\alpha\). Инструмент строит последовательность
$$x_i = \text{Initial x} + i \cdot \text{Step}, \quad i = 0, 1, \dots, \text{Count} - 1$$вычисляет \(f\) в каждой точке и выводит пары \((x, f(x))\) вместе с графиком кривой. Также можно указать единственное значение \(x\), чтобы получить прямой расчёт \(f(x)\).
Разбор примера
При \(\alpha = 0{,}01\): в точке \(x = -4\) вход неположительный, поэтому \(f = 0{,}01 \times (-4) = -0{,}04\). При \(x = 0\) получаем \(f = 0\). В точке \(x = 3\) вход положительный, значит \(f = 3\). С настройками по умолчанию (\(\text{startX} = -4\), \(\text{stepX} = 0{,}05\), \(\text{count} = 101\)) перебор идёт от \(x = -4\) (\(f = -0{,}04\)) до \(x = +1{,}0\) (\(f = 1{,}0\)), пересекая ноль на 81-й точке (\(i = 80\)).
Частые вопросы
Чем Leaky ReLU отличается от ReLU? ReLU выдаёт ровно 0 для всех отрицательных входов, а Leaky ReLU возвращает \(\alpha \cdot x\) — небольшое отрицательное число, сохраняя градиент.
Какое значение alpha выбрать? Чаще всего используют значение по умолчанию 0,01. В вариантах вроде Parametric ReLU значение \(\alpha\) обучается прямо во время тренировки сети.
Может ли alpha быть отрицательным? С математической точки зрения — да, но это нетипично и не рекомендуется для обычных сетей.