¿Qué es la función de activación Leaky ReLU?
La Leaky ReLU (del inglés Leaky Rectified Linear Unit, unidad lineal rectificada con fuga) es una de las funciones de activación más utilizadas en las redes neuronales profundas. Al igual que la ReLU estándar, deja pasar tal cual los valores de entrada positivos, pero en lugar de aplastar a cero los valores negativos les asigna una pequeña pendiente no nula, \(\alpha\). De este modo mantiene un gradiente pequeño para las preactivaciones negativas y ayuda a evitar el problema de la «ReLU muerta» (dying ReLU), en el que las neuronas se quedan atascadas devolviendo cero y dejan de aprender.
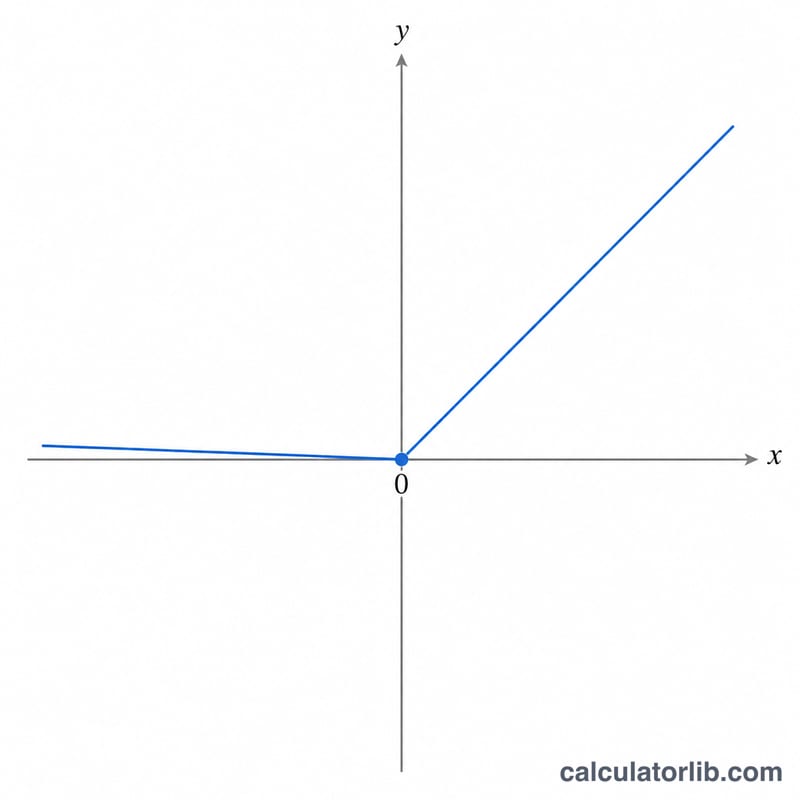
La fórmula
Para una entrada \(x\) y una pendiente de fuga \(\alpha\), la salida es:
$$f(\text{x}) = \begin{cases} \text{x} & \text{if } \text{x} > 0 \\[0.5em] \alpha \cdot \text{x} & \text{if } \text{x} \le 0 \end{cases}$$El valor de fuga por defecto es \(\alpha = 0{,}01\). Conviene tener presentes dos casos especiales: con \(\alpha = 0\) se recupera la ReLU estándar (\(\max(0, x)\)), y con \(\alpha = 1\) la función se reduce a la recta identidad \(f(x) = x\).
Cómo usar esta calculadora
Introduce el valor inicial de \(x\), el tamaño del paso entre puntos, el número de puntos que quieres generar y la pendiente de fuga \(\alpha\). La herramienta construye la secuencia
$$x_i = \text{Initial x} + i \cdot \text{Step}, \quad i = 0, 1, \dots, \text{Count} - 1$$evalúa \(f\) en cada punto y muestra los pares \((x, f(x))\) junto con la gráfica de la curva. También puedes escribir un único valor de \(x\) para obtener una evaluación directa de \(f(x)\).
Ejemplo resuelto
Con \(\alpha = 0{,}01\): en \(x = -4\) la entrada no es positiva, así que \(f = 0{,}01 \times (-4) = -0{,}04\). En \(x = 0\), \(f = 0\). En \(x = 3\) la entrada es positiva, por lo que \(f = 3\). Usando los valores por defecto (\(\text{startX} = -4\), \(\text{stepX} = 0{,}05\), \(\text{count} = 101\)), el recorrido va desde \(x = -4\) (\(f = -0{,}04\)) hasta \(x = +1{,}0\) (\(f = 1{,}0\)), cruzando el cero en el punto número 81 (\(i = 80\)).
Preguntas frecuentes
¿En qué se diferencia la Leaky ReLU de la ReLU? La ReLU devuelve exactamente 0 para todas las entradas negativas; la Leaky ReLU devuelve \(\alpha \cdot x\), un valor negativo pequeño, conservando así un gradiente.
¿Qué valor de alpha conviene usar? 0,01 es el valor por defecto habitual. Variantes como la ReLU paramétrica (PReLU) aprenden \(\alpha\) durante el entrenamiento.
¿Puede alpha ser negativo? Matemáticamente sí, pero es algo inusual y no se recomienda en redes estándar.