Qu'est-ce que la fonction d'activation Leaky ReLU ?
La Leaky ReLU (de l'anglais Leaky Rectified Linear Unit, soit « unité linéaire rectifiée avec fuite ») est une fonction d'activation très répandue dans les réseaux de neurones profonds. Comme la ReLU classique, elle laisse passer tels quels les signaux positifs ; mais au lieu d'écraser les entrées négatives à zéro, elle leur applique une légère pente non nulle, notée alpha. Un petit gradient continue ainsi de circuler pour les pré-activations négatives, ce qui permet d'éviter le problème du « ReLU mourant » (dying ReLU), où des neurones restent bloqués à zéro et cessent d'apprendre.
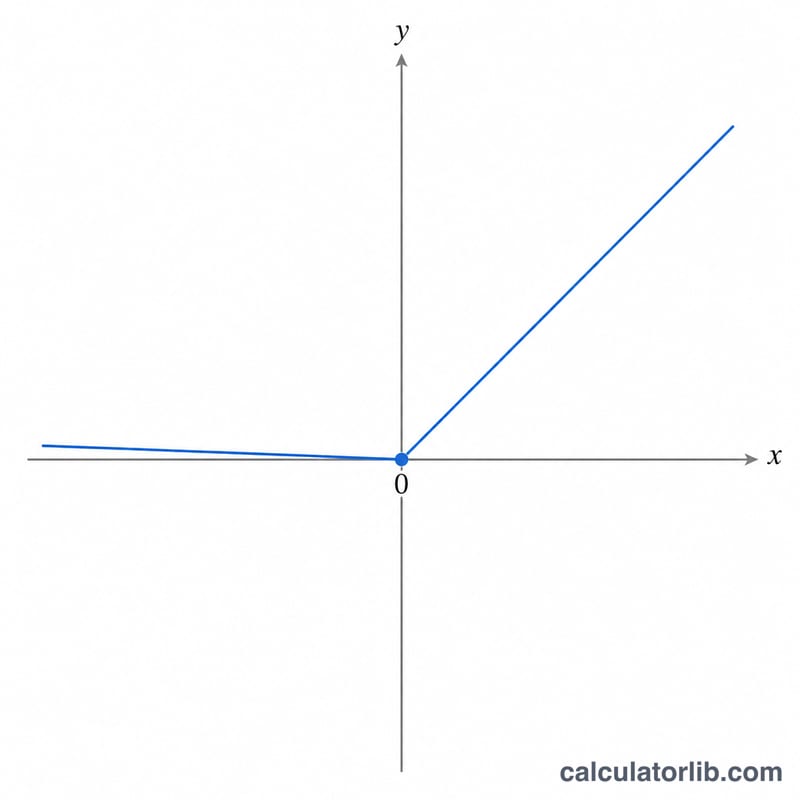
La formule
Pour une entrée \(x\) et une pente de fuite \(\alpha\), la sortie vaut $$f(x) = \begin{cases} x & \text{if } x > 0 \\[0.5em] \alpha \cdot x & \text{if } x \le 0 \end{cases}$$ La fuite par défaut est \(\alpha = 0{,}01\). Deux cas particuliers méritent d'être signalés : \(\alpha = 0\) redonne la ReLU classique (\(\max(0, x)\)), tandis qu'\(\alpha = 1\) ramène la fonction à la droite identité \(f(x) = x\).
Comment utiliser ce calculateur
Saisissez la valeur initiale de \(x\), le pas entre deux points, le nombre de points à générer et la pente de fuite \(\alpha\). L'outil construit la suite $$x_i = \text{startX} + i \cdot \text{stepX}, \quad i = 0, 1, \dots, \text{count} - 1$$ évalue \(f\) en chaque point, puis affiche les couples \((x, f(x))\) ainsi qu'un tracé de la courbe. Vous pouvez aussi saisir une seule valeur de \(x\) pour obtenir directement l'évaluation correspondante de \(f(x)\).
Exemple détaillé
Avec \(\alpha = 0{,}01\) : en \(x = -4\), l'entrée est négative, donc \(f = 0{,}01 \times (-4) = -0{,}04\). En \(x = 0\), \(f = 0\). En \(x = 3\), l'entrée est positive, donc \(f = 3\). En reprenant les valeurs par défaut (\(\text{startX} = -4\), \(\text{stepX} = 0{,}05\), \(\text{count} = 101\)), le balayage va de \(x = -4\) (\(f = -0{,}04\)) jusqu'à \(x = +1{,}0\) (\(f = 1{,}0\)), en franchissant le zéro au 81ᵉ point (\(i = 80\)).
FAQ
En quoi la Leaky ReLU diffère-t-elle de la ReLU ? La ReLU renvoie exactement 0 pour toutes les entrées négatives ; la Leaky ReLU renvoie \(\alpha \cdot x\), une petite valeur négative, ce qui préserve un gradient.
Quelle valeur choisir pour alpha ? 0,01 est la valeur par défaut la plus courante. Des variantes comme la Parametric ReLU (PReLU) apprennent la valeur d'alpha pendant l'entraînement.
Alpha peut-il être négatif ? Mathématiquement oui, mais c'est inhabituel et déconseillé pour les réseaux classiques.