Leaky ReLU活性化関数とは
Leaky ReLU(Leaky Rectified Linear Unit)は、ディープニューラルネットワークで広く使われる活性化関数です。標準的なReLUと同様に、正の入力はそのまま出力します。一方で、負の入力をすべて0にしてしまうのではなく、小さな傾きα(リーク係数)を掛けた値を出力するのが特徴です。これにより負の入力に対してもわずかな勾配が流れ続けるため、ニューロンが常に0を出力し続けて学習が止まってしまう「死んだReLU(dying ReLU)」問題を回避しやすくなります。
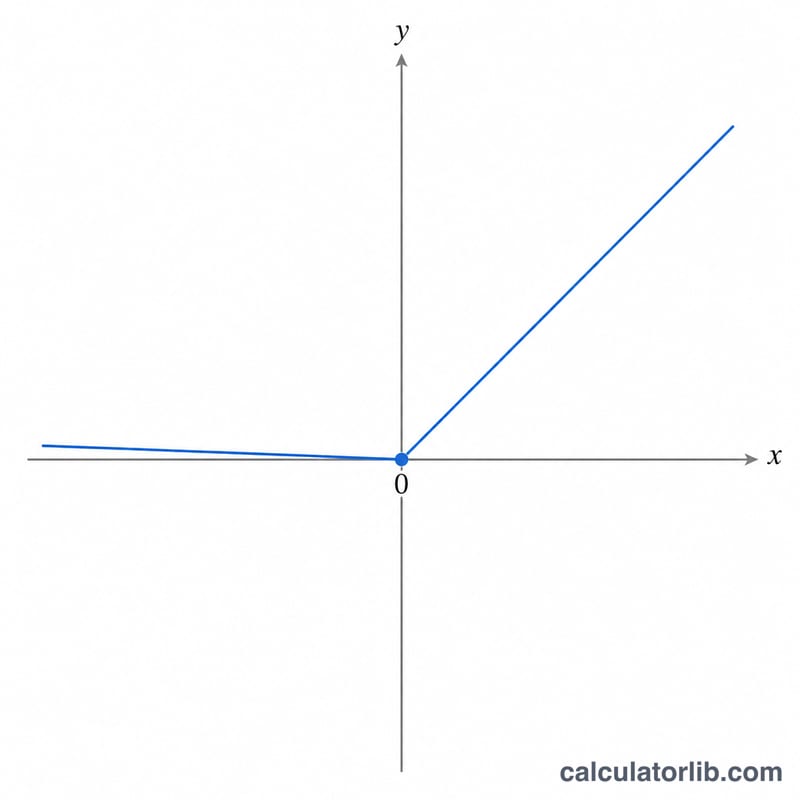
計算式
入力xとリーク係数αに対して、出力は次のようになります。
$$f(\text{x}) = \begin{cases} \text{x} & \text{if } \text{x} > 0 \\[0.5em] \alpha \cdot \text{x} & \text{if } \text{x} \le 0 \end{cases}$$αの既定値は 0.01 です。特別なケースとして、α = 0 のときは標準的なReLU(\(\max(0, \text{x})\))と一致し、α = 1 のときは恒等関数 \(f(\text{x}) = \text{x}\) になる点も押さえておくとよいでしょう。
このツールの使い方
xの初期値、点と点の間隔(ステップ幅)、生成する点の個数、そしてリーク係数αを入力してください。ツールは i = 0 から count−1 まで
$$x_i = \text{Initial x} + i \cdot \text{Step}, \quad i = 0, 1, \dots, \text{Count} - 1$$という数列を作り、各点で f を計算して、(x, f(x)) のペア一覧と曲線のグラフを表示します。また、単一のxの値を入力すれば、その点での \(f(\text{x})\) を1つだけ直接求めることもできます。
計算例
α = 0.01 の場合:x = −4 では入力が0以下なので \(f = 0.01 \times (-4) = -0.04\) となります。x = 0 では \(f = 0\)、x = 3 では入力が正なので \(f = 3\) です。既定値(startX = −4、stepX = 0.05、count = 101)を使うと、x = −4(f = −0.04)から x = +1.0(f = 1.0)まで計算が進み、81番目の点(i = 80)でちょうど0を通過します。
よくある質問(FAQ)
Leaky ReLUは通常のReLUと何が違いますか? ReLUは負の入力に対してすべて0を出力します。一方Leaky ReLUは \(\alpha \cdot \text{x}\) という小さな負の値を出力し、勾配を保ち続けます。
αにはどんな値が適していますか? 0.01 が一般的な既定値です。Parametric ReLU(PReLU)などの派生では、αを学習によって自動で調整します。
αを負の値にできますか? 数学的には可能ですが、一般的ではなく、通常のネットワークでは推奨されません。