什麼是 Leaky ReLU 激活函數?
Leaky ReLU(Leaky Rectified Linear Unit,帶洩漏的線性整流單元)是深度神經網路中相當常用的激活函數。它和標準 ReLU 一樣會讓正值輸入原封不動地通過,但不同的是,對於負值輸入,它不會直接壓成 0,而是賦予一個微小的非零斜率 alpha。如此一來,即使是負的預激活值也能保留一點梯度流動,有助於避免所謂的「ReLU 死亡」問題——也就是神經元卡在輸出 0、再也學不到東西的情況。
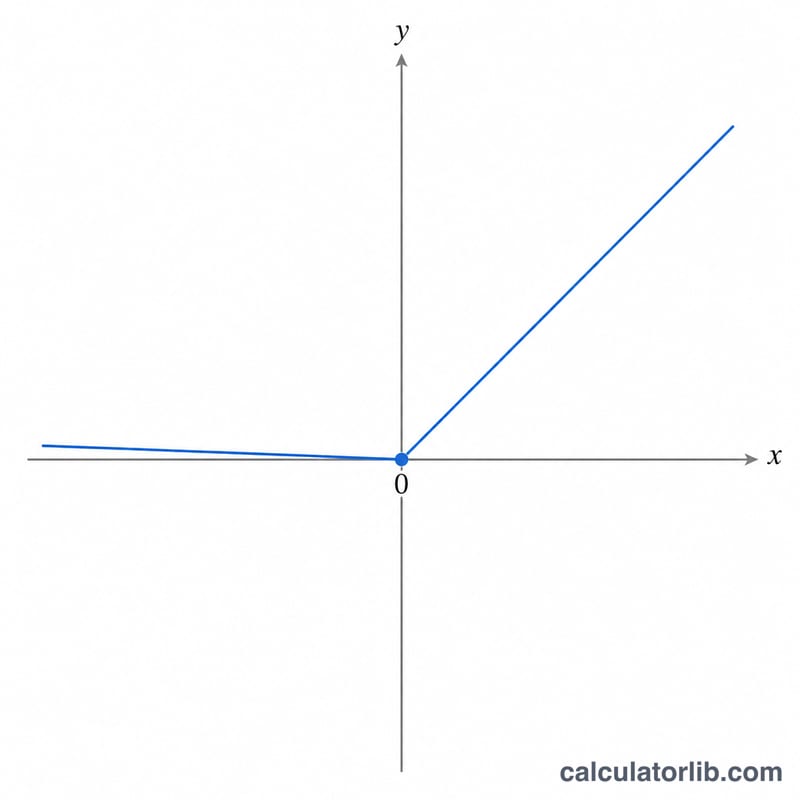
計算公式
對於輸入 \(x\) 與洩漏斜率 \(\alpha\),輸出為:當 \(x > 0\) 時 \(f(x) = x\);當 \(x \le 0\) 時 \(f(x) = \alpha \cdot x\)。
$$f(x) = \begin{cases} x & \text{if } x > 0 \\[0.5em] \alpha \cdot x & \text{if } x \le 0 \end{cases}$$預設的洩漏斜率為 \(\alpha = 0.01\)。有兩個特殊情況值得留意:當 \(\alpha = 0\) 時,函數就退化成標準 ReLU(\(\max(0, x)\));當 \(\alpha = 1\) 時,函數則塌縮成恆等直線 \(f(x) = x\)。
如何使用本計算器
輸入起始 \(x\) 值、各點之間的間距(步長)、要產生的點數,以及洩漏斜率 \(\alpha\)。工具會依公式
$$x_i = \text{startX} + i \cdot \text{stepX}, \quad i = 0, 1, \dots, \text{count} - 1$$(\(i\) 從 0 到 \(\text{count}-1\))建立數列,計算每個點的 \(f\) 值,並列出所有 \((x, f(x))\) 配對,同時繪製出曲線圖。你也可以直接輸入單一 \(x\) 值,立即取得對應的 \(f(x)\) 計算結果。
實例演算
以 \(\alpha = 0.01\) 為例:當 \(x = -4\) 時,輸入為非正值,所以 \(f = 0.01 \times (-4) = -0.04\);當 \(x = 0\) 時,\(f = 0\);當 \(x = 3\) 時,輸入為正值,所以 \(f = 3\)。若使用預設值(\(\text{startX} = -4\)、\(\text{stepX} = 0.05\)、\(\text{count} = 101\)),掃描範圍會從 \(x = -4\)(\(f = -0.04\))一路到 \(x = +1.0\)(\(f = 1.0\)),並在第 81 個點(\(i = 80\))處通過零點。
常見問題
Leaky ReLU 和 ReLU 有什麼差別?ReLU 對所有負值輸入都輸出 0;而 Leaky ReLU 會輸出 \(\alpha \cdot x\),也就是一個微小的負值,藉此保留梯度。
\(\alpha\) 取多少比較合適?0.01 是最常見的預設值。像 Parametric ReLU 這類變體,則會在訓練過程中自動學習 \(\alpha\) 的值。
\(\alpha\) 可以是負數嗎?數學上可以,但這種做法相當罕見,並不建議用在一般的神經網路中。