What is the Leaky ReLU activation function?
The Leaky ReLU (Leaky Rectified Linear Unit) is a popular activation function in deep neural networks. Like the standard ReLU it passes positive inputs straight through, but instead of flattening negative inputs to zero it gives them a small nonzero slope alpha. This keeps a small gradient flowing for negative pre-activations and helps avoid the "dying ReLU" problem, where neurons get stuck outputting zero and stop learning.
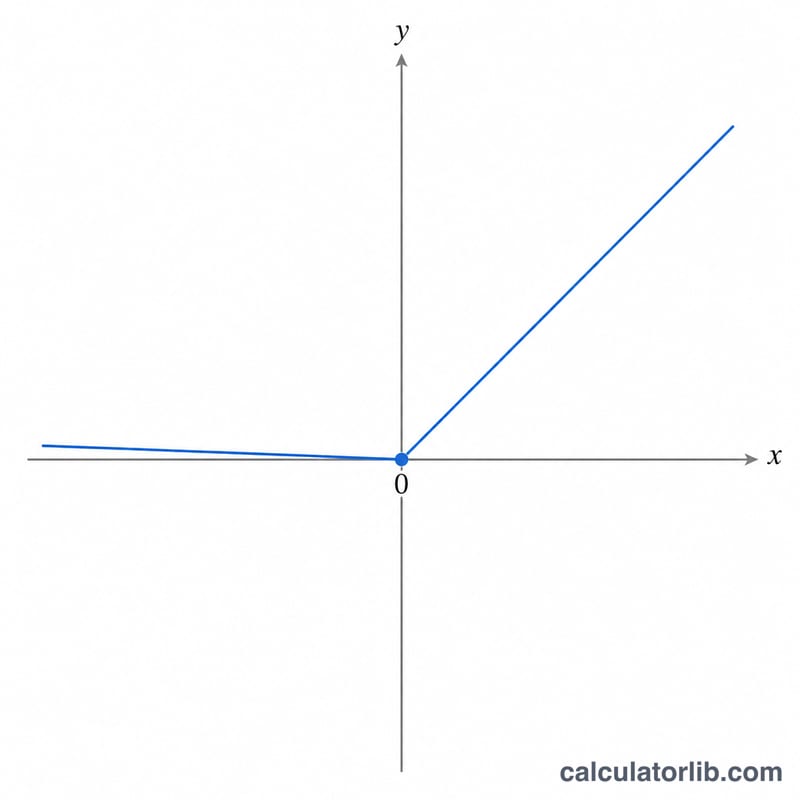
The formula
For an input \(x\) and leak slope \(\alpha\), the output is
$$f(x) = \begin{cases} x & \text{if } x > 0 \\[0.5em] \alpha \cdot x & \text{if } x \le 0 \end{cases}$$The default leak is \(\alpha = 0.01\). Two special cases are worth noting: \(\alpha = 0\) reproduces the standard ReLU (\(\max(0, x)\)), and \(\alpha = 1\) collapses the function to the identity line \(f(x) = x\).
How to use this calculator
Enter the initial x value, the step size between points, the number of points to generate, and the leak slope alpha. The tool builds the sequence
$$x_i = \text{startX} + i \cdot \text{stepX}, \quad i = 0, 1, \dots, \text{count} - 1$$evaluates \(f\) at each point, and lists the \((x, f(x))\) pairs plus a plot of the curve. You can also type a single \(x\) value to get one direct evaluation of \(f(x)\).
Worked example
With \(\alpha = 0.01\): at \(x = -4\) the input is non-positive, so $$f = 0.01 \times (-4) = -0.04.$$ At \(x = 0\), \(f = 0\). At \(x = 3\) the input is positive, so \(f = 3\). Using the defaults (\(\text{startX} = -4\), \(\text{stepX} = 0.05\), \(\text{count} = 101\)), the sweep runs from \(x = -4\) (\(f = -0.04\)) up to \(x = +1.0\) (\(f = 1.0\)), crossing zero at the 81st point (\(i = 80\)).
FAQ
How does Leaky ReLU differ from ReLU? ReLU outputs exactly 0 for all negative inputs; Leaky ReLU outputs \(\alpha \cdot x\), a small negative value, preserving a gradient.
What is a good value for alpha? 0.01 is the common default. Variants like Parametric ReLU learn alpha during training.
Can alpha be negative? Mathematically yes, but it is unusual and not recommended for standard networks.