什么是 Leaky ReLU 激活函数?
Leaky ReLU(带泄漏的修正线性单元,Leaky Rectified Linear Unit)是深度神经网络中常用的激活函数。和标准 ReLU 一样,它会让正数输入原样通过;不同的是,对于负数输入它不会直接压成零,而是赋予一个很小的非零斜率 alpha。这样一来,当预激活值为负时仍能保留一点点梯度,有助于缓解"ReLU 神经元死亡"(dying ReLU)问题——即神经元始终输出零、停止学习的情况。
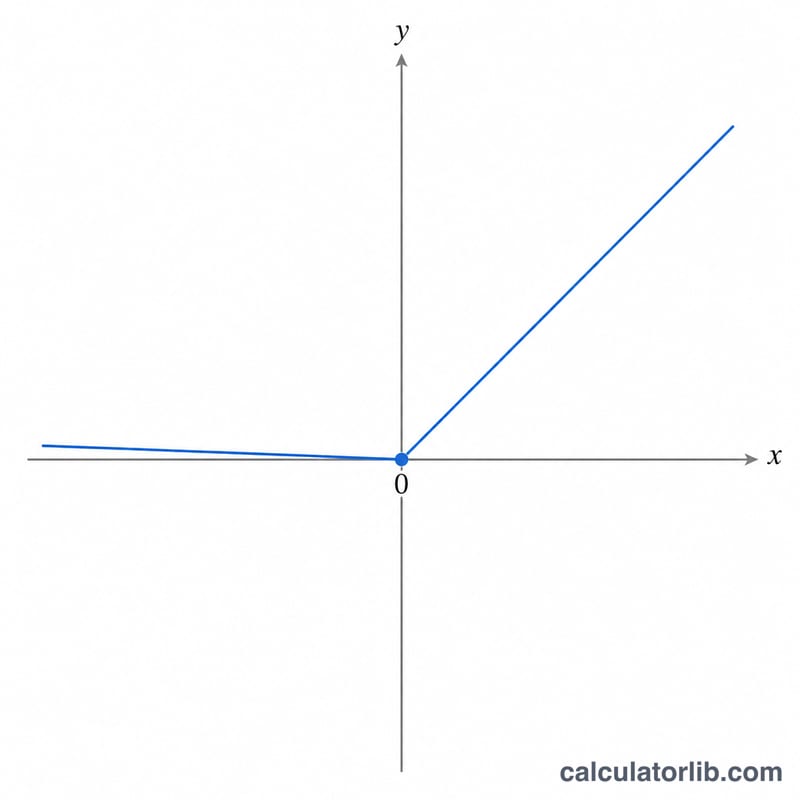
计算公式
给定输入 \(x\) 和泄漏斜率 \(\alpha\),输出为:
$$f(\text{x}) = \begin{cases} \text{x} & \text{if } \text{x} > 0 \\[0.5em] \alpha \cdot \text{x} & \text{if } \text{x} \le 0 \end{cases}$$当 \(x > 0\) 时 \(f(x) = x\);当 \(x \le 0\) 时 \(f(x) = \alpha \cdot x\)。默认泄漏斜率为 \(\alpha = 0.01\)。有两个特殊情形值得留意:当 \(\alpha = 0\) 时,函数还原为标准 ReLU(\(\max(0, x)\));当 \(\alpha = 1\) 时,函数退化为恒等直线 \(f(x) = x\)。
如何使用本计算器
依次输入起始 \(x\) 值、相邻两点之间的步长、需要生成的点数,以及泄漏斜率 \(\alpha\)。工具会按
$$x_i = \text{Initial x} + i \cdot \text{Step}, \quad i = 0, 1, \dots, \text{Count} - 1$$(\(i\) 从 0 到 count-1)构造数列,对每个点求出 \(f\) 值,并列出所有 \((x, f(x))\) 数据对,同时绘制函数曲线。你也可以只输入单个 \(x\) 值,直接得到对应的 \(f(x)\) 结果。
实例演算
取 \(\alpha = 0.01\):当 \(x = -4\) 时,输入为非正数,因此 \(f = 0.01 \times (-4) = -0.04\);当 \(x = 0\) 时,\(f = 0\);当 \(x = 3\) 时,输入为正数,因此 \(f = 3\)。采用默认参数(\(\text{startX} = -4\),\(\text{stepX} = 0.05\),\(\text{count} = 101\))时,扫描区间从 \(x = -4\)(\(f = -0.04\))一直到 \(x = +1.0\)(\(f = 1.0\)),并在第 81 个点(\(i = 80\))处穿过零点。
常见问题
Leaky ReLU 和 ReLU 有什么区别? 对于所有负数输入,ReLU 的输出严格为 0;而 Leaky ReLU 的输出是 \(\alpha \cdot x\),即一个很小的负值,从而保留了梯度。
alpha 取什么值比较合适? 0.01 是常见的默认值。像参数化 ReLU(Parametric ReLU)这类变体,则会在训练过程中自动学习 \(\alpha\) 的取值。
alpha 可以取负值吗? 从数学上讲是可以的,但这种用法很少见,在常规网络中并不推荐。