Qu'est-ce que la fonction softmax ?
La fonction softmax prend un vecteur de K nombres réels et le transforme en une distribution de probabilités : chaque sortie est strictement comprise entre 0 et 1, et l'ensemble des K valeurs s'additionne exactement à 1. C'est la fonction d'activation de référence dans la couche de sortie des classifieurs à réseaux de neurones, où elle convertit les scores bruts du modèle (les logits) en probabilités de classe. Comme elle est sans dimension, les entrées sont de purs nombres, sans unité.
Comment utiliser ce calculateur
Saisissez votre vecteur d'entrée dans le champ sous la forme d'une liste de nombres séparés par des virgules, des espaces ou des sauts de ligne (par exemple 1, 2, 3). Les nombres peuvent être positifs, négatifs, nuls ou décimaux. Cliquez sur « Calculer » : vous obtiendrez la probabilité softmax de chaque composante, la somme des sorties (qui doit valoir 1) ainsi que l'argmax — l'indice (à partir de 1) de la plus grande probabilité.
La formule expliquée
Pour chaque composante j, le softmax vaut \(\sigma(z)_j = \dfrac{e^{z_j}}{\sum_{k} e^{z_k}}\). L'exponentiation rend chaque terme positif, et la division par le total les normalise pour que leur somme atteigne 1. Pour garantir la stabilité numérique, ce calculateur soustrait la valeur maximale \(m\) de chaque élément avant l'exponentiation :
$$\sigma(z)_j = \frac{e^{\,z_j - m}}{\displaystyle\sum_{k} e^{\,z_k - m}}$$Le facteur commun \(e^{-m}\) se simplifie, ce qui donne un résultat identique tout en évitant le dépassement de capacité (overflow) sur de grandes valeurs.
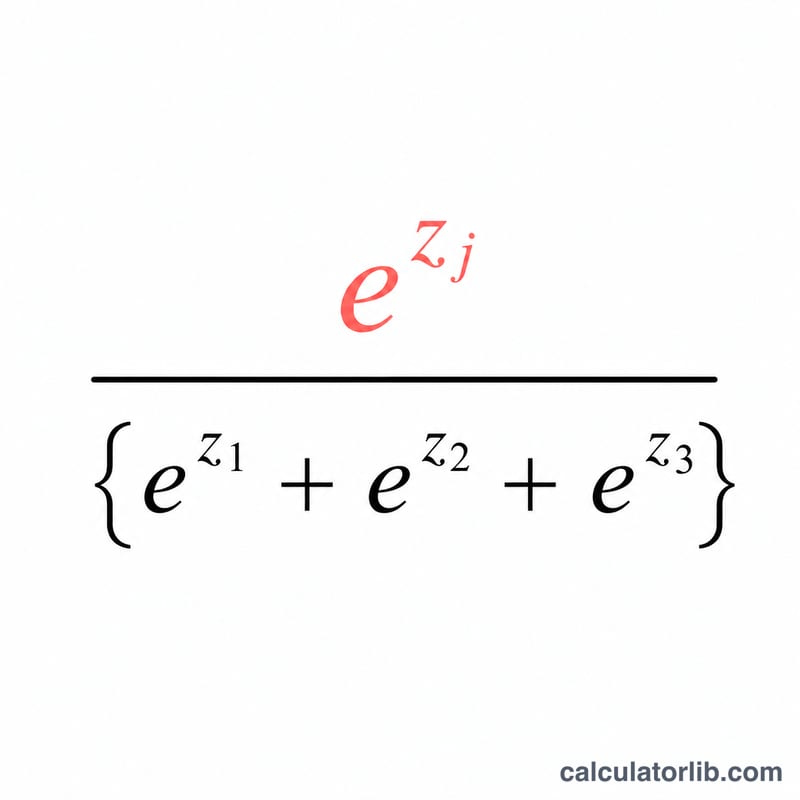
Exemple détaillé
Pour \(z = (1, 2, 3)\) : \(e^{1} = 2{,}71828\), \(e^{2} = 7{,}38906\), \(e^{3} = 20{,}08554\), soit une somme de \(30{,}19287\). En divisant chaque terme, on obtient
$$\sigma = (0{,}09003,\ 0{,}24473,\ 0{,}66524)$$dont la somme vaut 1. L'argmax est l'indice 3, qui correspond à la plus grande entrée, avec une probabilité de \(0{,}66524\).
FAQ
Pourquoi la somme des sorties vaut-elle toujours 1 ? Parce que chaque exponentielle est divisée par la somme de toutes les exponentielles : cette normalisation garantit un total de 1.
Que se passe-t-il si toutes les entrées sont égales ? Le résultat est une distribution uniforme où chaque sortie vaut \(1/K\).
Ajouter une constante à toutes les entrées change-t-il le résultat ? Non. Le softmax est invariant par translation : ajouter la même constante \(c\) à toutes les entrées ne modifie pas la sortie, et c'est précisément pour cela que soustraire le maximum est sans risque.