P-Hat क्या है?
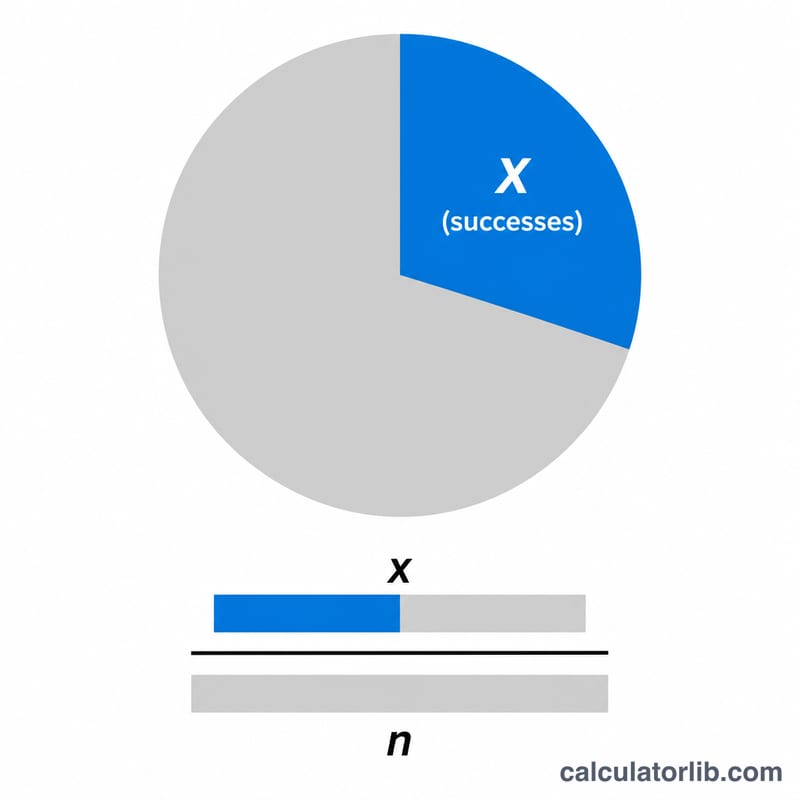
P-hat (जिसे p̂ लिखा जाता है) दरअसल सैंपल अनुपात है — यानी आपके सैंपल का वह हिस्सा जिसमें कोई खास विशेषता या "सफलता" मौजूद होती है। यह अज्ञात जनसंख्या अनुपात p का बिंदु आकलन (point estimate) होता है। इसे निकालने के लिए सफलताओं की संख्या (x) को कुल सैंपल आकार (n) से भाग दिया जाता है। यह कैलकुलेटर हर क्षेत्र में काम आता है: ओपिनियन पोल, गुणवत्ता नियंत्रण, जीव विज्ञान, चिकित्सा या कक्षा के सांख्यिकी प्रश्न।
इस कैलकुलेटर का उपयोग कैसे करें
बस दो मान भरें: सफलताओं की संख्या x (आपके सैंपल में कितनी चीज़ें शर्त पूरी करती हैं) और सैंपल आकार n (कुल कितनी चीज़ें देखी गईं)। कैलकुलेटर आपको p̂ दशमलव रूप में, वही मान प्रतिशत में, और पूरक \(\hat{q} = 1 - \hat{p}\) (यानी असफलताओं का अनुपात) तीनों दिखा देगा।
फ़ॉर्मूला समझें
फ़ॉर्मूला बेहद सरल है —
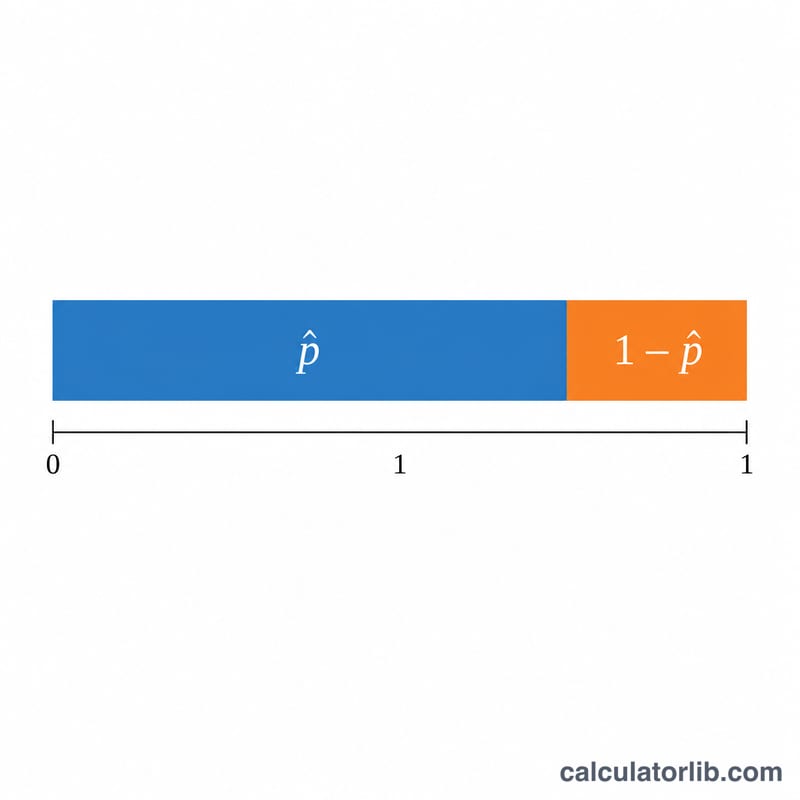
$$\hat{p} = \frac{\text{Successes }(x)}{\text{Sample Size }(n)}$$चूँकि x कभी भी n से ज़्यादा नहीं हो सकता, इसलिए p̂ हमेशा 0 और 1 के बीच रहता है। इसे प्रतिशत में पढ़ने के लिए 100 से गुणा कर दें। पूरक \(\hat{q} = 1 - \hat{p}\) कॉन्फ़िडेंस इंटरवल और मानक त्रुटि (standard error) के फ़ॉर्मूलों में काम आता है, जहाँ p̂ की मानक त्रुटि \(\sqrt{\hat{p}\cdot\hat{q} / n}\) होती है।
हल किया गया उदाहरण
मान लीजिए n = 100 लोगों के एक सर्वे में पाया गया कि x = 40 लोग किसी प्रस्ताव का समर्थन करते हैं। तब $$\hat{p} = \frac{40}{100} = 0.40,$$ यानी 40%। पूरक \(\hat{q} = 1 - 0.40 = 0.60\), यानी 60% लोग इसका समर्थन नहीं करते।
अक्सर पूछे जाने वाले सवाल
p और p̂ में क्या फ़र्क है? p असली (और अक्सर अज्ञात) जनसंख्या अनुपात होता है; जबकि p̂ सैंपल से निकाला गया उसका आकलन होता है।
क्या p̂ 1 से ज़्यादा हो सकता है? नहीं। चूँकि सफलताएँ सैंपल आकार से अधिक नहीं हो सकतीं, इसलिए p̂ हमेशा 0 और 1 के बीच ही रहता है।
q̂ क्यों मायने रखता है? \(\hat{q} = 1 - \hat{p}\) अनुपातों की मानक त्रुटि और कॉन्फ़िडेंस इंटरवल के फ़ॉर्मूलों में आता है, इसलिए इसे अक्सर p̂ के साथ ही बताया जाता है।