What is the Softsign function?
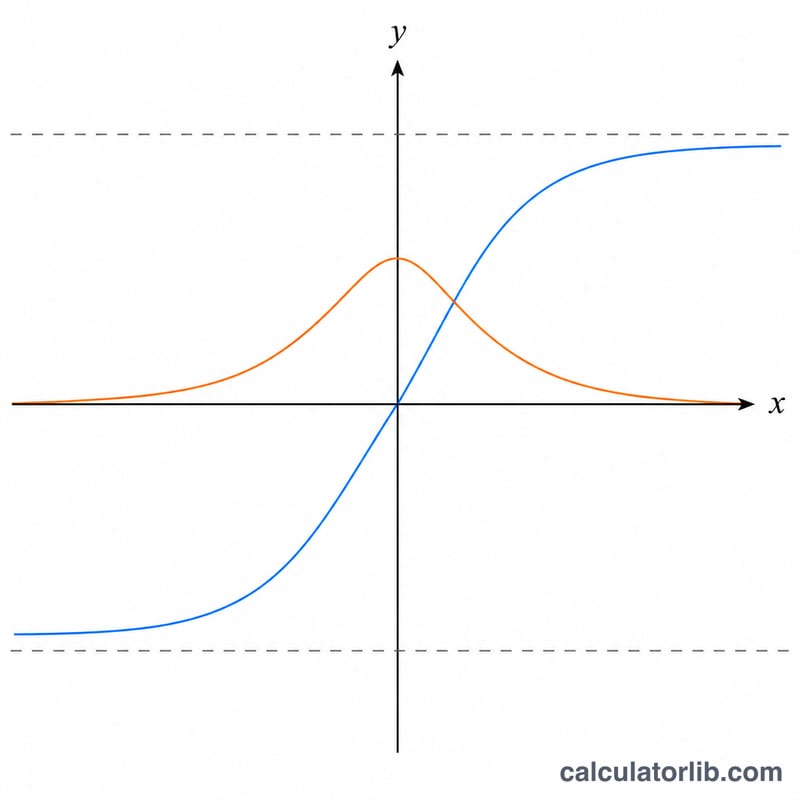
The Softsign function is a smooth activation function used in neural networks, defined as \(\phi(x) = x / (1 + |x|)\). It maps any real input into the open range (-1, 1), much like the hyperbolic tangent, but approaches its saturation limits more slowly. This gentler saturation can help reduce the vanishing-gradient problem during training. This calculator returns both the function value \(\phi(x)\) and, as its primary output, the first derivative \(\phi'(x)\).
How to use this calculator
Enter any real number for x — positive, negative, or zero — and read off \(\phi'(x)\) (the slope of the Softsign curve) along with \(\phi(x)\) (the activation output). No units are involved; x is a pure dimensionless real number. The default input is \(x = 0.5\).
The formula explained
The derivative of \(\phi(x) = x / (1 + |x|)\) is
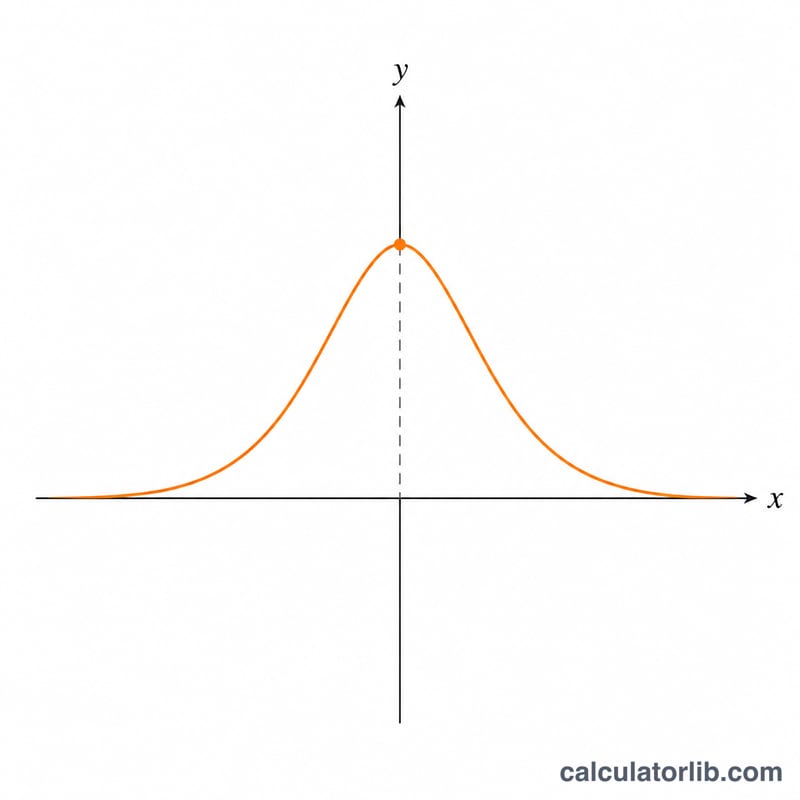
$$\phi'(x) = \frac{1}{\left(1 + |x|\right)^{2}}$$Because the denominator \((1 + |x|)\) is always at least 1, the derivative is always strictly positive and lies in the range (0, 1]. Its maximum value of 1 occurs at \(x = 0\), where the function is steepest. As \(|x|\) grows large, \(\phi'(x)\) shrinks toward 0, reflecting the function's saturation.
Worked example
For \(x = 0.5\): \(|x| = 0.5\), so \(1 + |x| = 1.5\). The function value is
$$\phi(0.5) = \frac{0.5}{1.5} = 0.333333\ldots$$and the derivative is
$$\phi'(0.5) = \frac{1}{1.5^{2}} = \frac{1}{2.25} = 0.444444\ldots$$So the Softsign curve at \(x = 0.5\) has an output near 0.3333 and a slope near 0.4444.
FAQ
Is the Softsign differentiable everywhere? Yes. Even though \(|x|\) has a kink at \(x = 0\), the left and right derivatives of \(\phi\) both equal 1 there, so \(\phi\) is differentiable at 0 and everywhere else.
Can the derivative ever be negative? No. \(\phi'(x) = 1 / (1 + |x|)^2\) is always positive, since it is one divided by a squared positive number.
How does Softsign compare to tanh? Both saturate to (-1, 1), but Softsign uses polynomial \((1/x^2)\) tails rather than tanh's exponential tails, so it saturates more slowly and keeps slightly larger gradients far from zero.