什麼是 ReLU 激活函數?
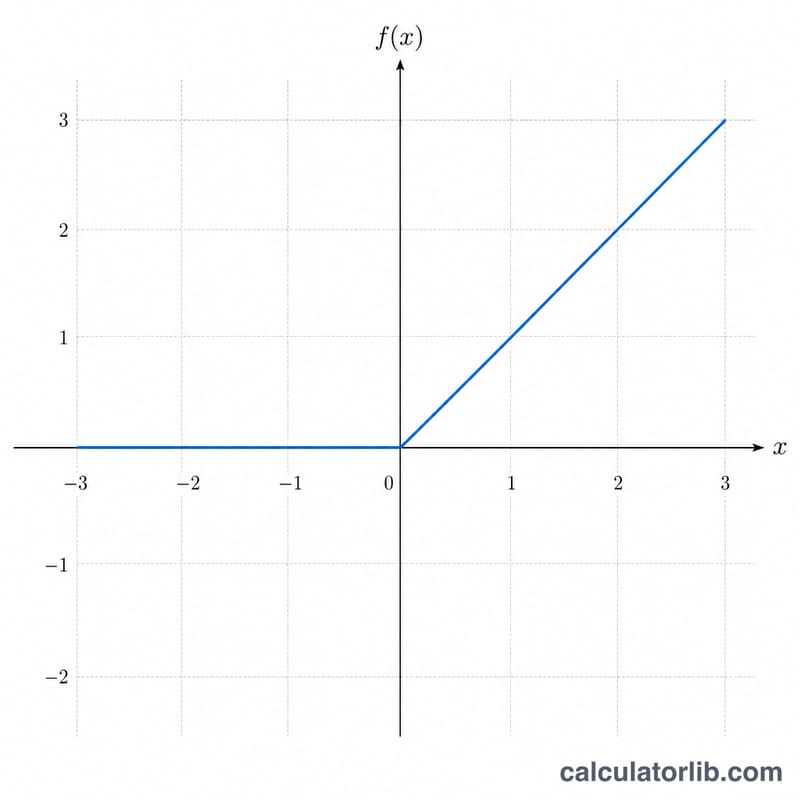
ReLU 是「整流線性單元」(Rectified Linear Unit)的縮寫,也是現代深度學習與神經網路中最常使用的激活函數之一。它的定義為 \( f(x) = \max(0,\ x) \),意思是正數輸入會原封不動地通過,負數(以及零)則一律被壓成 0。這條簡單的規則為網路引入了非線性,計算成本卻極低,因此今日大多數的卷積層與全連接層都採用它。
如何使用這個計算器
只要在 x 欄位輸入任意實數,計算器就會回傳 \( f(x) = \text{ReLU}(x) \)。負數、零、正數都可以輸入。當 x 大於 0 時,結果等於 x;當 x 為 0 或負數時,結果等於 0。計算器同時也會顯示慣用的導數:正數輸入時為 1,其餘情況為 0。
公式詳解
ReLU 是一個分段函數:當 \( x > 0 \) 時 \( f(x) = x \),當 \( x \le 0 \) 時 \( f(x) = 0 \)。它的定義域為全體實數 \( (-\infty,\ +\infty) \),值域為 \( [0,\ +\infty) \)。ReLU 處處連續,但嚴格來說在 \( x = 0 \) 這一點上導數並未定義;依慣例會將該點設為 0,因此 \( x \le 0 \) 時 \( f'(x) = 0 \),\( x > 0 \) 時 \( f'(x) = 1 \)。由於整個過程沒有牽涉除法,所以不需要特別防範任何邊界情況。
實際範例
假設 \( x = -3.2 \),則 $$ f(x) = \max(0,\ -3.2) = 0 $$ 因為 -3.2 是負數。若 \( x = 7 \),則 $$ f(x) = \max(0,\ 7) = 7 $$ 以預設輸入 \( x = 0.5 \) 為例, $$ f(x) = \max(0,\ 0.5) = 0.5 $$
常見問題
為什麼 ReLU 這麼受歡迎?它能避免 sigmoid 與 tanh 在輸入值較大時所遇到的梯度消失問題,而且運算極為簡單——只需要和 0 比較大小。
在 \( x = 0 \) 時會發生什麼?此時函數值為 0,導數依慣例也取為 0。
ReLU、Sigmoid 與 Softmax 有什麼差別?Sigmoid 會把數值壓縮到 \( (0,\ 1) \) 之間,Softmax 則會對一整個向量產生機率分布;而 ReLU 只是單純把單一數值整流為非負值。