Hàm kích hoạt ReLU là gì?
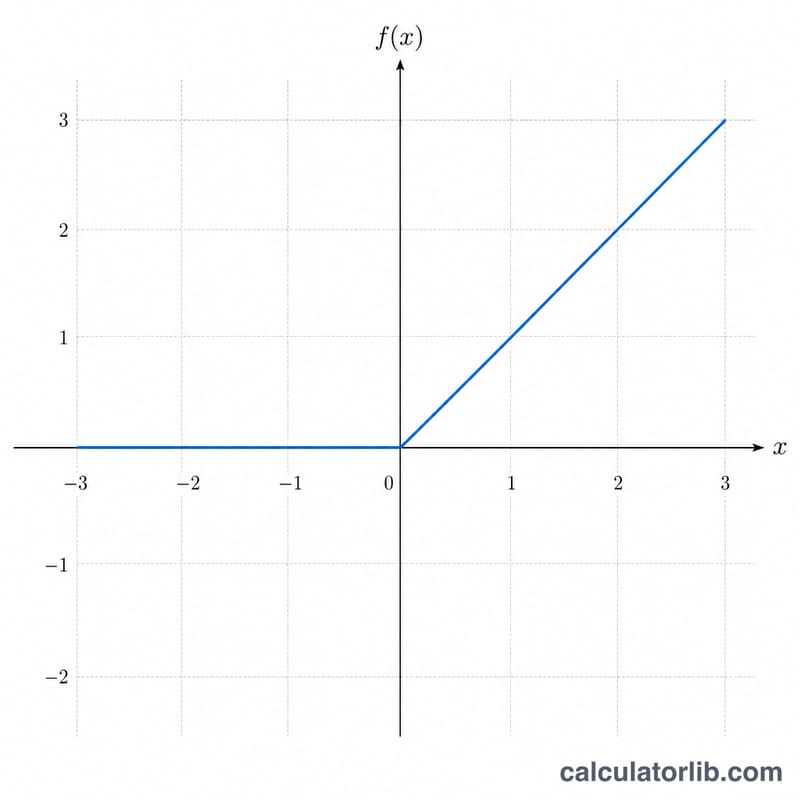
ReLU, viết tắt của Rectified Linear Unit (đơn vị tuyến tính chỉnh lưu), là một trong những hàm kích hoạt được dùng phổ biến nhất trong học sâu và mạng nơ-ron hiện đại. Hàm được định nghĩa là \(f(x) = \max(0,\ x)\), nghĩa là giữ nguyên các giá trị đầu vào dương và đưa các giá trị âm (cùng với 0) về 0. Quy tắc đơn giản này tạo ra tính phi tuyến cho mạng nhưng vẫn cực kỳ nhẹ về mặt tính toán — đó là lý do ReLU được sử dụng trong hầu hết các lớp tích chập và lớp kết nối đầy đủ ngày nay.
Cách sử dụng công cụ này
Nhập một số thực bất kỳ vào ô x và công cụ sẽ trả về \(f(x) = \text{ReLU}(x)\). Các giá trị âm, bằng 0 hay dương đều hợp lệ. Kết quả bằng \(x\) khi \(x\) lớn hơn 0, và bằng 0 khi \(x\) bằng 0 hoặc âm. Công cụ cũng hiển thị đạo hàm theo quy ước: bằng 1 với đầu vào dương và bằng 0 trong các trường hợp còn lại.
Giải thích công thức
Hàm ReLU được định nghĩa theo từng đoạn:
$$\text{ReLU}(x) = \max\left(0,\ x\right)$$\(f(x) = x\) nếu \(x > 0\), và \(f(x) = 0\) nếu \(x \le 0\). Tập xác định là toàn bộ số thực \((-\infty,\ +\infty)\) và tập giá trị là \([0,\ +\infty)\). ReLU liên tục ở mọi điểm, nhưng về mặt kỹ thuật đạo hàm không xác định đúng tại \(x = 0\); theo quy ước, người ta gán giá trị 0 tại điểm này, do đó \(f'(x) = 0\) khi \(x \le 0\) và \(f'(x) = 1\) khi \(x > 0\). Vì không có phép chia nào, nên không có trường hợp đặc biệt nào cần phòng tránh.
Ví dụ minh họa
Giả sử \(x = -3.2\). Khi đó
$$f(x) = \max(0,\ -3.2) = 0$$vì \(-3.2\) là số âm. Ngược lại, nếu \(x = 7\) thì
$$f(x) = \max(0,\ 7) = 7$$Với giá trị mặc định \(x = 0.5\), ta có
$$f(x) = \max(0,\ 0.5) = 0.5$$Câu hỏi thường gặp
Vì sao ReLU lại phổ biến đến vậy? Nó tránh được vấn đề tiêu biến gradient (vanishing gradient) — vốn gây khó khăn cho hàm sigmoid và tanh khi đầu vào lớn — đồng thời tính toán cực kỳ đơn giản, chỉ là một phép so sánh với 0.
Điều gì xảy ra tại \(x = 0\)? Giá trị hàm là 0, và đạo hàm theo quy ước được lấy bằng 0.
ReLU, Sigmoid và Softmax khác nhau thế nào? Sigmoid nén các giá trị về khoảng \((0,\ 1)\) và Softmax tạo ra một phân phối xác suất trên một vector, trong khi ReLU chỉ đơn giản chỉnh lưu một giá trị đơn lẻ thành không âm.