什么是 ReLU 激活函数?
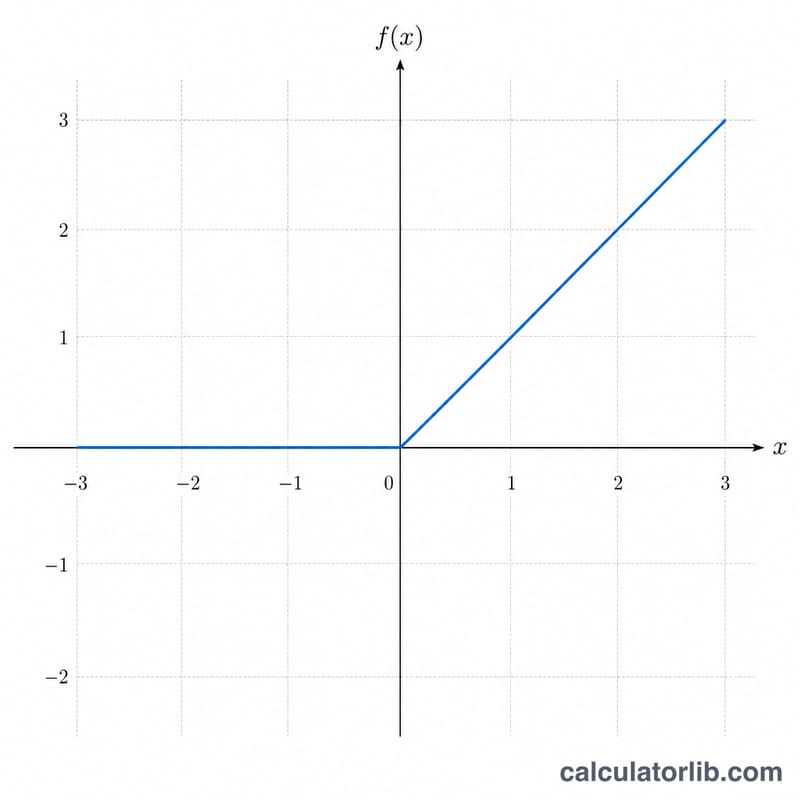
ReLU 是「线性整流单元」(Rectified Linear Unit)的缩写,是现代深度学习与神经网络中应用最广泛的激活函数之一。它的定义为 \(f(x) = \max(0,\ x)\),也就是说:正数输入原样输出,而负数(以及 0)则被截断为 0。这个简单的规则为网络引入了非线性,同时计算成本极低,因此当今绝大多数卷积层和全连接层都采用它。
如何使用本计算器
在 x 输入框中填入任意实数,计算器即可返回 \(f(x) = \text{ReLU}(x)\)。负数、0 和正数都是合法输入。当 x 大于 0 时,结果等于 x;当 x 为 0 或负数时,结果等于 0。计算器还会给出约定俗成的导数值:正数输入时为 1,其余情况下为 0。
公式详解
ReLU 函数采用分段定义:当 x > 0 时 \(f(x) = x\);当 x ≤ 0 时 \(f(x) = 0\)。它的定义域是全体实数 (-∞, +∞),值域为 [0, +∞)。ReLU 在整个定义域上连续,但严格来说它在 x = 0 处的导数是没有定义的;按照惯例,这里取 0,于是当 x ≤ 0 时 \(f'(x) = 0\),当 x > 0 时 \(f'(x) = 1\)。由于运算中不涉及除法,因此无需担心任何特殊边界情况。
计算实例
假设 x = -3.2,由于 -3.2 是负数,因此 $$f(x) = \max(0,\ -3.2) = 0.$$ 若 x = 7,则 $$f(x) = \max(0,\ 7) = 7.$$ 对于默认输入 x = 0.5,则有 $$f(x) = \max(0,\ 0.5) = 0.5.$$
常见问题
ReLU 为什么如此流行? 它避免了 sigmoid 和 tanh 在输入较大时容易出现的梯度消失问题,而且计算极其简单——只需和 0 做一次比较即可。
x = 0 时会怎样? 此时函数值为 0,导数按惯例同样取 0。
ReLU、Sigmoid 和 Softmax 有什么区别? Sigmoid 会把数值压缩到 (0, 1) 区间,Softmax 则把一个向量转换为一组概率分布,而 ReLU 只是把单个数值整流为非负数。