Qué hace esta calculadora
Esta herramienta evalúa la distribución normal bivariante estándar, una gaussiana bidimensional con medias nulas, varianzas unitarias en ambos ejes y un único parámetro libre: el coeficiente de correlación ρ. Dado un punto \((x, y)\), devuelve dos valores: la densidad de probabilidad conjunta \(f(x, y, \rho)\) en ese punto y la probabilidad acumulada de cola superior (orthante) \(Q(x, y, \rho) = P(U_1 > x \text{ Y } U_2 > y)\). Como todas las entradas son ya puntuaciones estandarizadas y adimensionales, la calculadora es universal y no necesita conversión de unidades.
Cómo usarla
Introduce el punto percentil x, el punto percentil y y la correlación ρ. Aquí "punto percentil" se refiere a un umbral estandarizado tipo z (una coordenada), no a un percentil entre 0 y 1. La correlación debe cumplir \(-1 < \rho < 1\); los valores \(\pm 1\) se rechazan porque la densidad se vuelve singular (división por cero en \(\sqrt{1-\rho^{2}}\)).
Las fórmulas explicadas
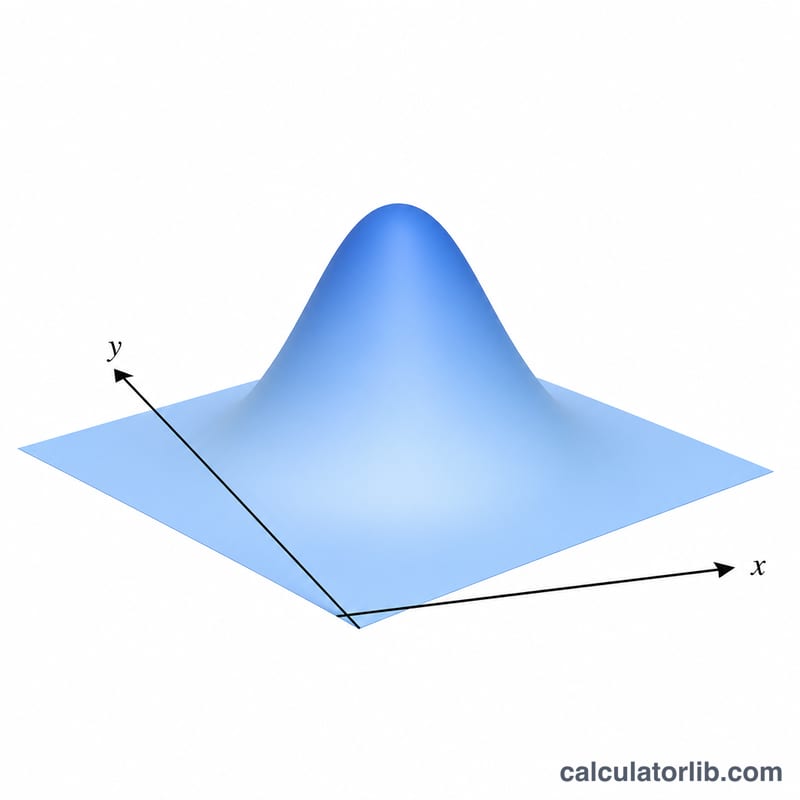
La densidad es la gaussiana en forma cerrada mostrada arriba.
$$\varphi(x,y;\rho) = \frac{1}{2\pi\sqrt{1-\rho^{2}}}\,\exp\!\left(-\frac{x^{2}-2\rho\,x\,y+y^{2}}{2\left(1-\rho^{2}\right)}\right)$$La probabilidad del orthante emplea la identidad de Sheppard: cuando ρ = 0 las variables son independientes y \(Q = Q_1(x)\cdot Q_1(y)\), donde \(Q_1(t)\) es la función univariante de cola superior de la normal estándar. Para ρ distinto de cero se añade una integral de corrección de 0 a ρ, evaluada aquí mediante cuadratura de Gauss–Legendre de 24 nodos para garantizar la precisión.
$$\begin{gathered} Q(x,y;\rho) = Q_1(x)\,Q_1(y) + \frac{1}{2\pi}\int_{0}^{\rho}\frac{\exp\!\left(-\dfrac{x^{2}-2r\,x\,y+y^{2}}{2(1-r^{2})}\right)}{\sqrt{1-r^{2}}}\,dr \\[1.5em] \text{where}\quad \left\{ \begin{aligned} x &= \text{Percentile point x} \\ y &= \text{Percentile point y} \\ \rho &= \text{Correlation }\rho \\ Q_1(t) &= \tfrac{1}{2}\,\operatorname{erfc}\!\left(\tfrac{t}{\sqrt{2}}\right) \end{aligned} \right. \end{gathered}$$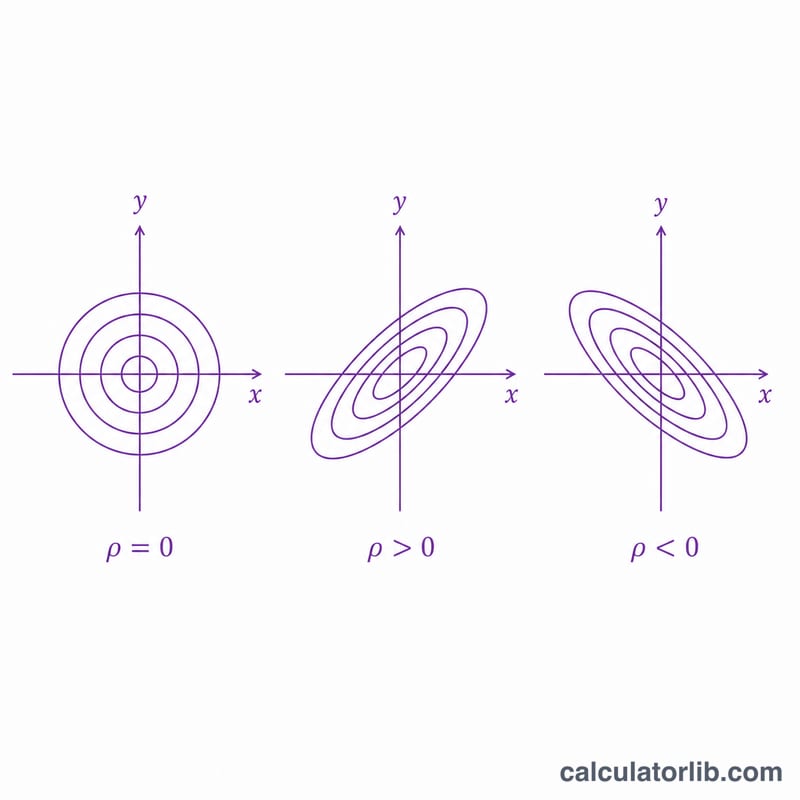
Ejemplo resuelto
Para \(x = 2\), \(y = 0{,}7\), \(\rho = 0{,}8\): \(1 - \rho^{2} = 0{,}36\), \(\sqrt{\,} = 0{,}6\), factor previo \(= 1/(2\pi\cdot 0{,}6) = 0{,}265258\). Numerador del exponente \(= 4 - 2\cdot 0{,}8\cdot 2\cdot 0{,}7 + 0{,}49 = 2{,}25\), dividido entre \(0{,}72\) da \(3{,}125\). Así que \(f = 0{,}265258 \cdot e^{-3{,}125} \approx 0{,}011655\). La probabilidad superior \(Q \approx 0{,}0212\) — mayor que el valor de independencia \(0{,}0055\), porque la correlación positiva empuja ambas variables hacia arriba a la vez.
Cómo la correlación cambia la probabilidad del ortante
La probabilidad del ortante \(Q(x,y;\rho)=P(U_1>x,\,U_2>y)\) mide la probabilidad de que dos variables normales estándar simultáneamente superen sus umbrales. Manteniendo los puntos de corte fijos en \(x=1\) y \(y=1\) y variando la correlación \(\rho\) aísla el efecto puro de la dependencia. Cuando \(\rho=0\) las variables son independientes y \(Q\) se factoriza en el producto de las dos colas superiores univariadas, \(Q_1(x)\,Q_1(y)\). Para una normal estándar, \(Q_1(1)=P(U>1)\approx 0.158655\), por lo que el punto de referencia de la independencia es \(0.158655^2\approx 0.025172\).
| \(\rho\) | Densidad \(f(1,1;\rho)\) | Ortante \(Q(1,1;\rho)\) | Independencia \(Q_1(1)Q_1(1)\) |
|---|---|---|---|
| \(-0.8\) | 0.0476 | 0.0049 | 0.0252 |
| \(-0.4\) | 0.0780 | 0.0145 | 0.0252 |
| \(0\) | 0.0585 | 0.0252 | 0.0252 |
| \(0.4\) | 0.1063 | 0.0438 | 0.0252 |
| \(0.8\) | 0.2643 | 0.0826 | 0.0252 |
El patrón es monótono: la correlación positiva hace que la excedencia conjunta sea más probable (los valores grandes tienden a ocurrir juntos), por lo que \(Q\) se eleva por encima del valor de independencia; la correlación negativa tira de las dos variables en direcciones opuestas, por lo que la excedencia conjunta se vuelve más rara y \(Q\) cae por debajo de \(Q_1 Q_1\). En \(\rho=0\) la probabilidad del ortante es exactamente igual al producto \(0.0252\), confirmando la factorización de independencia.
Interpretación de la densidad y la probabilidad del ortante
La densidad \(f\) no es una probabilidad. El valor \(\varphi(x,y;\rho)\) es una densidad de probabilidad por unidad de área en el plano \((x,y)\); solo su integral sobre una región devuelve una probabilidad. La superficie alcanza su máximo en el origen \((0,0)\), donde el término exponencial es igual a 1 y
$$f(0,0;\rho)=\frac{1}{2\pi\sqrt{1-\rho^{2}}}.$$Para \(\rho=0\) este pico es \(1/(2\pi)\approx 0.159\), cómodamente por debajo de 1. Cuando \(\rho\to\pm 1\) el factor \(1/\sqrt{1-\rho^2}\) diverge, por lo que la densidad máxima puede exceder 1 — eso es normal para una densidad, ya que concentra la masa de probabilidad en la línea \(y=\rho x\).
La probabilidad del ortante \(Q\) es una probabilidad genuina y siempre se encuentra en \([0,1]\). Es el volumen bajo la superficie de densidad sobre el cuadrante \(\{U_1>x,\,U_2>y\}\). Hechos estructurales útiles:
- Independencia (\(\rho=0\)): \(Q(x,y;0)=Q_1(x)\,Q_1(y)\), el producto de las dos colas superiores univariadas.
- Simetría en los argumentos: intercambiando los papeles de las dos coordenadas, \(Q(x,y;\rho)=Q(y,x;\rho)\).
- Identidad de reflexión: \(Q(-x,-y;\rho)=Q(x,y;\rho)+ \Phi(-x)+\Phi(-y)-1\) (expresable equivalentemente a través de la función de distribución acumulada bivariada), e invertir el signo de un argumento invierte la correlación efectiva: \(P(U_1>x,\,U_2
- Comportamiento límite \(\rho\to 1^{-}\): las variables se vuelven perfectamente comonótonas, \(U_2\approx U_1\), por lo que \(Q(x,y;\rho)\to Q_1(\max(x,y))\) — ambas excedencias coinciden.
- Comportamiento límite \(\rho\to -1^{+}\): las variables se vuelven perfectamente contramonótonas, \(U_2\approx -U_1\). La excedencia superior conjunta es entonces posible solo cuando ambos umbrales pueden superarse simultáneamente, dando \(Q\to\max\!\big(0,\;1-\Phi(x)-\Phi(y)\big)\), que es 0 cada vez que \(x+y\ge 0\).
Dado que no hay forma cerrada para \(Q\) con \(\rho\) general, se evalúa numéricamente — típicamente a través de la función T de Owen o una integral unidimensional sobre \(\rho\) usando cuadratura de Gauss–Legendre, ambas de las cuales reproducen los valores mostrados en la tabla de comparación con alta precisión.
Definiciones y glosario
- Puntuación estandarizada (\(x\), \(y\))
- Una coordenada similar a z que mide cuántas desviaciones estándar se encuentra un valor de su media. Los valores de entrada \(x\) e \(y\) ya están estandarizados, por lo que cada uno sigue marginalmente la distribución normal estándar \(N(0,1)\).
- Coeficiente de correlación \(\rho\)
- La correlación lineal (Pearson) entre las dos variables normales estándar, con \(-1<\rho<1\). Es el único parámetro que rige cuán fuertemente se mueven juntas las dos coordenadas; \(\rho=0\) significa independencia aquí, mientras que \(\rho\to\pm1\) significa una relación lineal casi determinista. Un \(\rho\) observado puede estimarse a partir de datos apareados con una calculadora de correlación de Pearson.
- Densidad conjunta \(f(x,y;\rho)\)
- La densidad de probabilidad normal bivariada estándar, \(\varphi(x,y;\rho)=\dfrac{1}{2\pi\sqrt{1-\rho^2}}\exp\!\left(-\dfrac{x^2-2\rho xy+y^2}{2(1-\rho^2)}\right)\). Describe la probabilidad por unidad de área, no una probabilidad en sí misma.
- Probabilidad del ortante \(Q(x,y;\rho)\)
- La probabilidad conjunta de la cola superior \(P(U_1>x,\,U_2>y)\) — el volumen bajo la superficie de densidad sobre el cuadrante superior derecho definido por los dos umbrales. Siempre entre 0 y 1.
- Cola superior univariada \(Q_1(t)\)
- La función de supervivencia normal estándar \(Q_1(t)=P(U>t)=1-\Phi(t)\), el área en la cola derecha más allá de \(t\). Por ejemplo \(Q_1(1)\approx 0.1587\). En \(\rho=0\), \(Q=Q_1(x)Q_1(y)\).
- Función de error complementaria (\(\operatorname{erfc}\))
- Una función especial relacionada con la cola normal por \(Q_1(t)=\tfrac{1}{2}\operatorname{erfc}\!\left(t/\sqrt{2}\right)\). Proporciona una manera numéricamente estable de calcular las probabilidades de cola univariadas utilizadas en \(Q\).
- Cuadratura de Gauss–Legendre
- Un esquema de integración numérica que aproxima una integral definida por una suma ponderada del integrando en nodos elegidos óptimamente. Dado que \(Q(x,y;\rho)\) no tiene forma cerrada elemental, comúnmente se evalúa integrando la densidad (o una función de \(\rho\)) con este método para obtener resultados precisos.
Preguntas frecuentes
¿Por qué ρ no puede valer exactamente 1? En \(\rho = \pm 1\) las dos variables son perfectamente dependientes y la distribución se reduce a una línea; la densidad no tiene un valor finito fuera de esa línea.
¿Qué representa Q? Es la masa de probabilidad en el "orthante" superior derecho, más allá de ambos umbrales: \(P(U_1 > x, U_2 > y)\).
¿Qué ocurre con valores grandes de x o y? La densidad decae hacia 0 y \(Q\) se aproxima a 0, ya que es cada vez más improbable que ambas variables estandarizadas superen umbrales positivos elevados.