Üstel regresyon nedir?
Üstel regresyon, eşleştirilmiş gözlem kümenize \(y = A \cdot B^{x}\) biçiminde bir eğri uydurur. x değeri her bir birim arttığında miktarın yaklaşık sabit bir oranla büyüdüğü veya azaldığı durumlarda kullanılması gereken doğru araçtır — nüfus artışı, bileşik faiz, radyoaktif bozunma, bakteri kültürleri ve daha pek çok doğal süreç bu kapsama girer. Bu, bölgeye özgü hiçbir kuralı olmayan, evrensel bir istatistiksel araçtır.
Nasıl kullanılır?
Verilerinizi her satıra bir çift olacak şekilde x,y formatında girin. En az iki noktaya ihtiyacınız vardır; x değerlerinin tamamı birbirinin aynısı olmamalı ve her y değeri kesinlikle pozitif olmalıdır (yöntem, y'nin doğal logaritmasını alır). Gösterilecek ondalık basamak sayısını seçin, ardından A, B ve korelasyon katsayısı r değerlerini okuyun.
Formülün açıklaması
Model doğrusal değildir, ancak logaritma almak onu doğrusal hâle getirir: $$\ln(y) = \ln(A) + x \cdot \ln(B)$$ Bu nedenle dönüştürülmüş noktalar \((x_i, \ln y_i)\) üzerinde sıradan en küçük kareler doğru uydurması uygularız. \(\bar{x}\) x'in ortalaması, meanLnY ise ln y'nin ortalaması olmak üzere şunları tanımlarız: \(S_{xx} = \sum(x_i - \bar{x})^2\), \(S_{yy} = \sum(\ln y_i - \text{meanLnY})^2\) ve \(S_{xy} = \sum(x_i - \bar{x})(\ln y_i - \text{meanLnY})\). Buradan $$B = \exp\!\left(\frac{S_{xy}}{S_{xx}}\right), \quad A = \exp\!\left(\text{meanLnY} - \bar{x} \cdot \ln B\right), \quad r = \frac{S_{xy}}{\sqrt{S_{xx}} \cdot \sqrt{S_{yy}}}$$ bulunur.
Çözümlü örnek
(1, 2.7), (2, 7.4), (3, 20.1), (4, 54.6), (5, 148.4) noktaları için: \(n = 5\), \(\bar{x} = 3\), \(\text{meanLnY} \approx 2.99906\). \(S_{xx} = 10\), \(S_{xy} \approx 10.01167\), \(S_{yy} \approx 10.02337\). Böylece $$B = \exp(1.001167) \approx 2.7215$$ $$A = \exp(2.99906 - 3 \cdot 1.001167) \approx 0.9956$$ ve \(r \approx 0.99999985\) olur. Uydurulan model \(y \approx 0.9956 \cdot 2.7215^{x}\), altta yatan \(y \approx e^{x}\) ilişkisiyle son derece örtüşür.
Sonucunuzu Yorumlama
Exponential regresyon üç sayı döndürür — \(A\), \(B\) ve \(r\) — bu sayılar birlikte \(y = A \cdot B^{\,x}\) modelini tanımlar. Her birini nasıl okuyacağınız aşağıda açıklanmıştır.
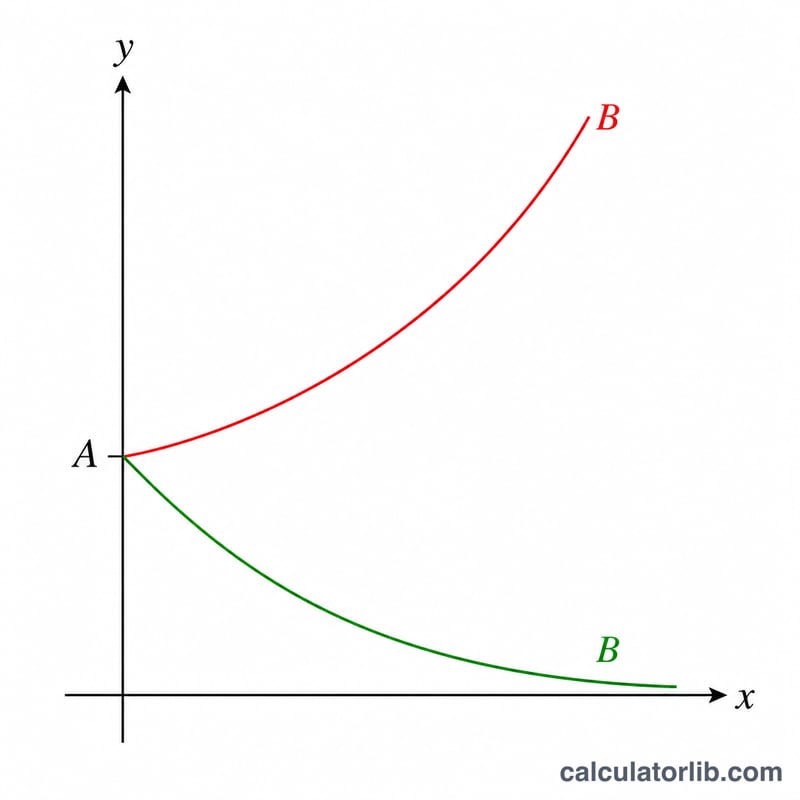
Taban \(B\): büyüme veya azalış
Taban \(B\), \(x\)'in her bir birim artışında \(y\) için değişimin yönünü ve hızını kontrol eder:
- \(B > 1\) büyüme anlamına gelir. \(x\)'deki her adım \(y\)'yi \(B\) ile çarpar, bu nedenle eğri yükselir. Birim başına yüzde değişim \((B-1)\times100\%\) dir. Örneğin, \(B = 1.08\) \(x\)'in her biriminde %8 büyümeye karşılık gelir.
- \(B < 1\) azalış anlamına gelir. Her adım \(y\)'yi birden küçük bir sayıyla çarpar, bu nedenle eğri sıfıra doğru düşer. Aynı formül \((B-1)\times100\%\) negatif bir sonuç verir; örneğin \(B = 0.85\) birim başına \(-15\%\) değişimdir.
- \(B = 1\) düzdür. \(y\), \(x\) ne olursa olsun \(A\)'ya eşit kalır (sıfır yüzde değişim).
Katsayı \(A\): y-eksen kesim noktası
\(A\), \(x = 0\) olduğunda \(y\)'nin değeridir, çünkü \(A \cdot B^{0} = A\) dır. Eğriyi dikey olarak sabitlendirmekle, başlangıç miktarını, ilk popülasyonu, anaparayı veya \(x\)-ekseninizin başlangıcındaki dozu temsil eder.
Korelasyon katsayısı \(r\): log ölçeğinde uyum
Bu uyum \(z_i = \ln y_i\) alınarak ve \(z\) ile \(x\) arasında sıradan bir doğrusal regresyon çalıştırılarak çalışır. Sonuç olarak, \(r\), log-dönüştürülen verinin \(\ln(y)\) bir doğru üzerine ne kadar iyi düştüğünü ölçer — ham \(y\) değerlerinin eğriye ne kadar iyi uyduğunu değil. \(r\)'nin \(+1\) veya \(-1\)'e yakın bir değeri güçlü bir exponential ilişkisini gösterir; işaret yönle eşleşir (büyüme için pozitif, azalış için negatif).
\(|r|\) için standart korelasyon yorumlama bantlarını kullanarak:
- 0.9 – 1.0: çok güçlü uyum — veriler exponential modeli yakından takip eder.
- 0.7 – 0.9: güçlü uyum — exponential bazı dağınıklıkla iyi bir tanımdır.
- 0.5 – 0.7: orta düzeyde uyum — bir eğilim vardır ancak başka faktörler devrededir.
- 0.5'in altında: zayıf uyum — exponential model uygun olmayabilir.
\(r\) log ölçeği uyumunu yansıttığından, yüksek \(r\) orijinal \(y\) ölçeğinde küçük hataları garanti etmez; büyük \(y\) değerleri \(\ln\) dönüşümünden sonra daha az ağırlık taşır. Uyumu kontrol etmek için her zaman uygun eğriyi ham verilerinize karşı çizin.
Sıkça sorulan sorular
y neden pozitif olmak zorunda? Uydurma işlemi \(\ln(y)\) üzerinde çalışır ve sıfırın ya da negatif bir sayının logaritması tanımsızdır.
Burada r ne anlama geliyor? r, x ile \(\ln(y)\) arasındaki korelasyondur. Şu rehberi kullanın: \(0.7 < |r| \le 1\) güçlü, \(0.4 < |r| < 0.7\) orta, \(0.2 < |r| < 0.4\) zayıf, 0.2'nin altı ilişki yok.
Tüm x değerlerim aynıysa ne olur? Bu durumda \(S_{xx} = 0\) olur ve eğim tanımsız hâle gelir; en az iki farklı x değeri girmelisiniz.