지수 회귀란?
지수 회귀는 짝지어진 관측값들에 \(y = A \cdot B^{x}\) 형태의 곡선을 적합시키는 방법입니다. x가 한 단위 늘어날 때마다 어떤 값이 거의 일정한 배율로 늘거나 줄어드는 상황, 예를 들어 인구 증가, 복리 이자, 방사성 붕괴, 박테리아 배양처럼 자연계에서 흔히 볼 수 있는 현상을 다룰 때 가장 적합한 도구입니다. 특정 국가의 규칙과는 무관한, 어디서나 통용되는 보편적인 통계 도구입니다.
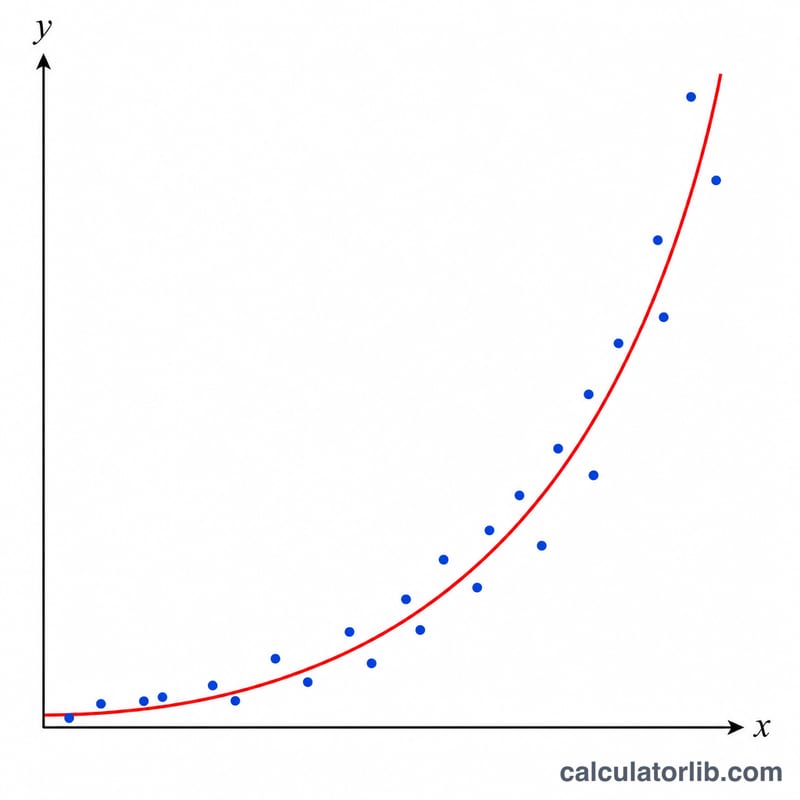
사용 방법
데이터를 한 줄에 한 쌍씩 x,y 형식으로 입력하세요. 최소 두 개의 점이 필요하며, x 값이 모두 같아서는 안 되고, 모든 y 값은 반드시 양수여야 합니다(이 방법은 y의 자연로그를 사용하기 때문입니다). 표시할 자릿수를 고른 뒤 결과로 나오는 A, B, 그리고 상관계수 r을 확인하면 됩니다.
공식 풀이
이 모델은 비선형이지만, 로그를 취하면 선형으로 바뀝니다: $$\ln(y) = \ln(A) + x \cdot \ln(B)$$ 따라서 변환된 점 \((x_i, \ln y_i)\)에 일반 최소제곱 직선 적합을 적용합니다. x의 평균을 \(\bar{x}\), ln y의 평균을 \(\text{meanLnY}\)라 할 때, \(S_{xx} = \sum (x_i - \bar{x})^2\), \(S_{yy} = \sum (\ln y_i - \text{meanLnY})^2\), \(S_{xy} = \sum (x_i - \bar{x})(\ln y_i - \text{meanLnY})\)로 정의합니다. 그러면 $$B = \exp\!\left(\frac{S_{xy}}{S_{xx}}\right), \quad A = \exp\!\left(\text{meanLnY} - \bar{x} \cdot \ln B\right), \quad r = \frac{S_{xy}}{\sqrt{S_{xx}} \cdot \sqrt{S_{yy}}}$$가 됩니다.
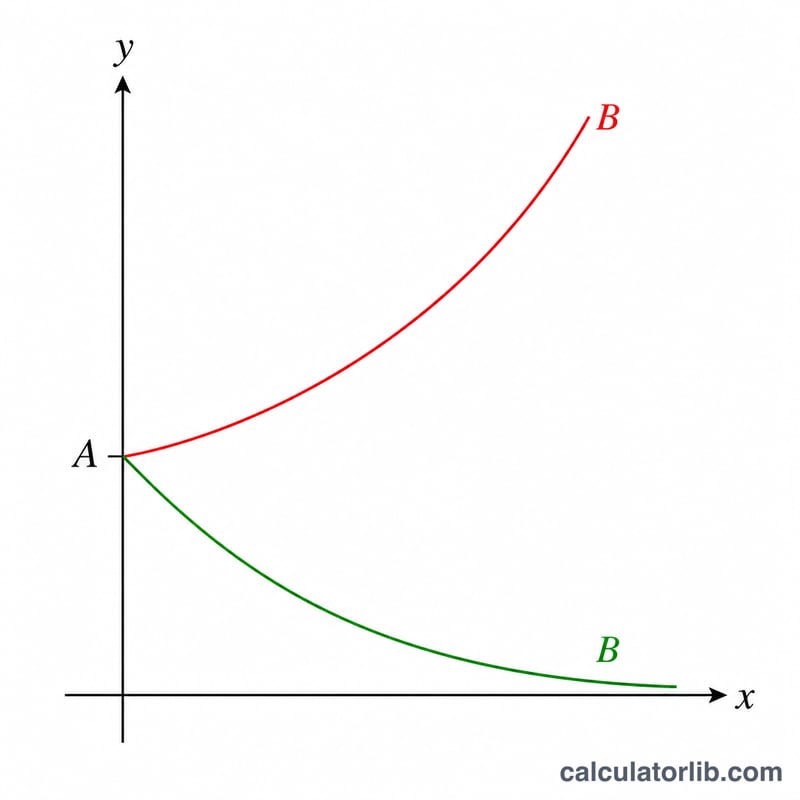
계산 예시
점 (1, 2.7), (2, 7.4), (3, 20.1), (4, 54.6), (5, 148.4)을 살펴봅시다. \(n = 5\), \(\bar{x} = 3\), \(\text{meanLnY} \approx 2.99906\)입니다. \(S_{xx} = 10\), \(S_{xy} \approx 10.01167\), \(S_{yy} \approx 10.02337\)이므로, $$B = \exp(1.001167) \approx 2.7215, \quad A = \exp(2.99906 - 3 \cdot 1.001167) \approx 0.9956, \quad r \approx 0.99999985$$가 나옵니다. 적합된 모델 \(y \approx 0.9956 \cdot 2.7215^{x}\)는 실제 함수 \(y \approx e^{x}\)와 거의 완벽하게 일치합니다.
결과 해석
지수 회귀는 모델 \(y = A \cdot B^{\,x}\)을(를) 설명하는 세 개의 숫자 — \(A\), \(B\) 그리고 \(r\) — 를 반환합니다. 각각을 읽는 방법은 다음과 같습니다.
밑 \(B\): 성장 또는 감소
밑 \(B\)는 \(x\)가 한 단위 증가할 때마다 변화의 방향과 속도를 제어합니다:
- \(B > 1\)은 성장을 의미합니다. \(x\)의 각 단계마다 \(y\)에 \(B\)를 곱하므로 곡선이 상승합니다. 단위당 백분율 변화는 \((B-1)\times100\%\)입니다. 예를 들어, \(B = 1.08\)은 8% \(x\)의 단위당 성장에 해당합니다.
- \(B < 1\)은 감소를 의미합니다. 각 단계마다 \(y\)에 1보다 작은 수를 곱하므로 곡선이 0으로 향해 내려갑니다. 같은 공식 \((B-1)\times100\%\)은 음수 결과를 줍니다. 예를 들어, \(B = 0.85\)는 단위당 \(-15\%\) 변화입니다.
- \(B = 1\)은 평탄합니다. \(x\)와 관계없이 \(y\)는 \(A\)와 같게 유지됩니다(백분율 변화 없음).
계수 \(A\): y절편
\(A\)는 \(x = 0\)일 때 \(y\)의 값입니다. 왜냐하면 \(A \cdot B^{0} = A\)이기 때문입니다. 곡선을 수직으로 고정하고 시작 금액, 초기 인구, 원금 또는 \(x\)축의 원점에서의 용량을 나타냅니다.
상관 계수 \(r\): 로그 스케일의 적합도
이 적합은 \(z_i = \ln y_i\)를 취하고 \(z\)를 \(x\)에 대해 일반 선형 회귀를 실행하는 방식으로 작동합니다. 따라서 \(r\)은 로그 변환된 데이터 \(\ln(y)\)가 직선에 얼마나 잘 맞는지를 측정합니다 — 원본 \(y\) 값이 곡선에 얼마나 잘 맞는지가 아닙니다. \(r\)이 \(+1\) 또는 \(-1\)에 가까운 값은 강한 지수 관계를 나타냅니다. 부호는 방향과 일치합니다(성장의 경우 양수, 감소의 경우 음수).
\(|r|\)에 대한 표준 상관 해석 대역을 사용하면:
- 0.9 – 1.0: 매우 강한 적합 — 데이터가 지수 모델을 밀접하게 따릅니다.
- 0.7 – 0.9: 강한 적합 — 지수는 약간의 산포가 있는 좋은 설명입니다.
- 0.5 – 0.7: 중간 적합 — 추세가 존재하지만 다른 요소가 작용합니다.
- 0.5 이하: 약한 적합 — 지수 모델이 적절하지 않을 수 있습니다.
\(r\)이 로그 스케일 적합을 반영하기 때문에 높은 \(r\)이 원본 \(y\) 스케일에서 작은 오차를 보장하지는 않습니다. \(\ln\) 변환 후 큰 \(y\) 값의 가중치가 더 낮습니다. 항상 피팅된 곡선을 원본 데이터에 대해 도표로 표시하여 타당성을 확인하십시오.
자주 묻는 질문
y가 반드시 양수여야 하는 이유는? 적합 계산은 \(\ln(y)\)를 기반으로 하는데, 0이나 음수의 로그는 정의되지 않기 때문입니다.
여기서 r은 무엇을 의미하나요? x와 \(\ln(y)\) 사이의 상관관계를 나타냅니다. 다음 기준으로 해석하세요: \(0.7 < |r| \le 1\) 강함, \(0.4 < |r| < 0.7\) 보통, \(0.2 < |r| < 0.4\) 약함, 0.2 미만이면 상관 없음.
x 값이 모두 같으면 어떻게 되나요? 그 경우 \(S_{xx} = 0\)이 되어 기울기를 구할 수 없습니다. 서로 다른 x 값을 최소 두 개 이상 입력해 주세요.