Qu'est-ce que la régression exponentielle ?
La régression exponentielle consiste à ajuster une courbe de la forme \(y = A \cdot B^{x}\) à un ensemble de couples d'observations. C'est l'outil idéal dès qu'une grandeur croît ou décroît selon un facteur à peu près constant pour chaque augmentation d'une unité de x : croissance démographique, intérêts composés, désintégration radioactive, cultures bactériennes et bien d'autres phénomènes naturels. Il s'agit d'un outil statistique universel, sans règles propres à un pays donné.
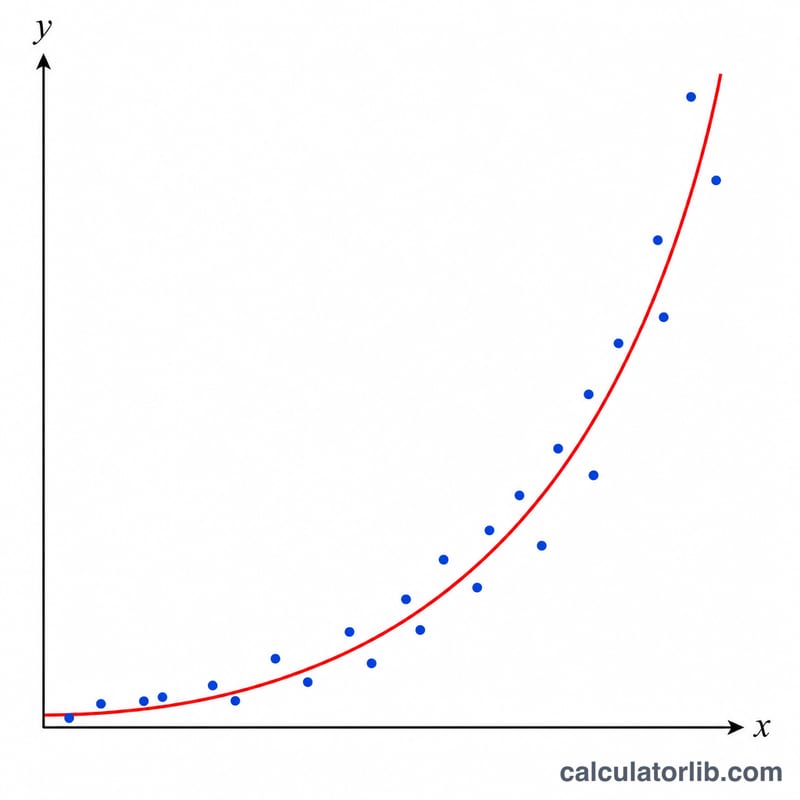
Comment l'utiliser
Saisissez vos données à raison d'un couple par ligne sous la forme x,y. Il vous faut au moins deux points, les valeurs de x ne doivent pas être toutes identiques et chaque valeur de y doit être strictement positive (la méthode prend le logarithme naturel de y). Choisissez le nombre de décimales à afficher, puis lisez directement A, B et le coefficient de corrélation r.
La formule expliquée
Le modèle est non linéaire, mais le passage au logarithme le rend linéaire :
$$\ln(y) = \ln(A) + x \cdot \ln(B)$$On effectue donc un ajustement linéaire par les moindres carrés ordinaires sur les points transformés \((x_i, \ln y_i)\). En notant \(\bar{x}\) la moyenne des x et \(\overline{\ln y}\) la moyenne des ln y, on pose \(S_{xx} = \sum (x_i - \bar{x})^2\), \(S_{yy} = \sum (\ln y_i - \overline{\ln y})^2\) et \(S_{xy} = \sum (x_i - \bar{x})(\ln y_i - \overline{\ln y})\). On obtient alors
$$B = e^{S_{xy}/S_{xx}}, \quad A = e^{\,\overline{\ln y} - \bar{x}\ln B}, \quad r = \frac{S_{xy}}{\sqrt{S_{xx}\,S_{yy}}}$$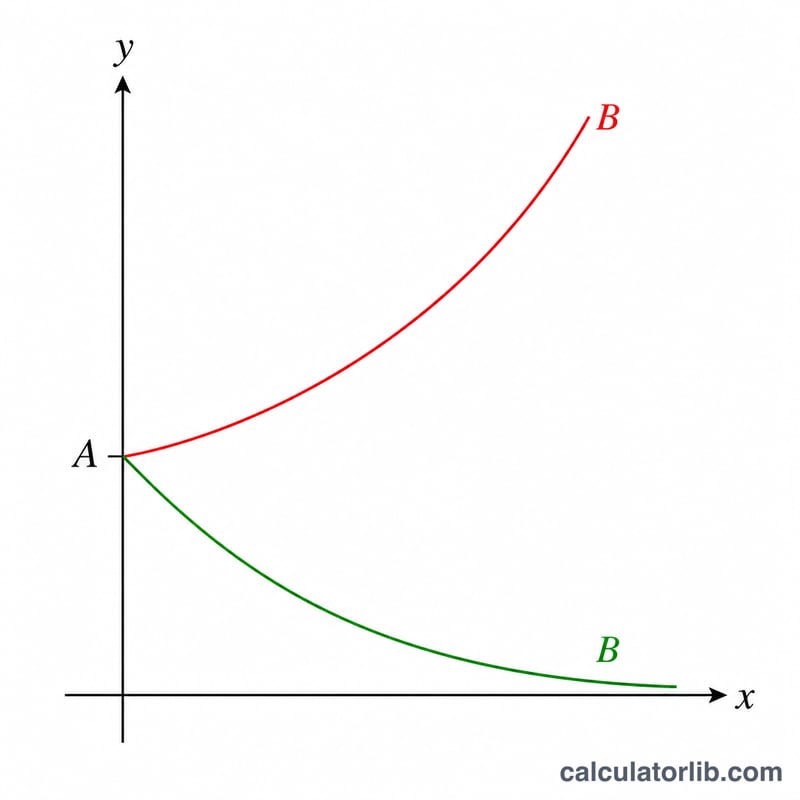
Exemple concret
Pour les points (1, 2.7), (2, 7.4), (3, 20.1), (4, 54.6), (5, 148.4) : \(n = 5\), \(\bar{x} = 3\), \(\overline{\ln y} \approx 2.99906\). \(S_{xx} = 10\), \(S_{xy} \approx 10.01167\), \(S_{yy} \approx 10.02337\). On a donc
$$B = e^{1.001167} \approx 2.7215, \quad A = e^{2.99906 - 3 \cdot 1.001167} \approx 0.9956, \quad r \approx 0.99999985$$Le modèle ajusté \(y \approx 0.9956 \cdot 2.7215^{x}\) reproduit fidèlement la loi sous-jacente \(y \approx e^{x}\).
Interpréter votre résultat
Une régression exponentielle retourne trois nombres — \(A\), \(B\) et \(r\) — qui décrivent ensemble le modèle \(y = A \cdot B^{\,x}\). Voici comment lire chacun d'eux.
La base \(B\) : croissance ou décroissance
La base \(B\) contrôle la direction et la vitesse du changement pour chaque augmentation d'une unité en \(x\) :
- \(B > 1\) signifie croissance. Chaque étape en \(x\) multiplie \(y\) par \(B\), donc la courbe monte. Le changement en pourcentage par unité est \((B-1)\times100\%\). Par exemple, \(B = 1.08\) correspond à 8 % de croissance par unité de \(x\).
- \(B < 1\) signifie décroissance. Chaque étape multiplie \(y\) par moins de un, donc la courbe descend vers zéro. La même formule \((B-1)\times100\%\) donne un résultat négatif ; par exemple \(B = 0.85\) est un changement de \(-15\%\) par unité.
- \(B = 1\) est plat. \(y\) reste égal à \(A\) quel que soit \(x\) (zéro pour cent de changement).
Le coefficient \(A\) : l'ordonnée à l'origine
\(A\) est la valeur de \(y\) quand \(x = 0\), car \(A \cdot B^{0} = A\). Il ancre la courbe verticalement et représente le montant initial, la population initiale, le capital, ou la dose à l'origine de votre axe \(x\).
Le coefficient de corrélation \(r\) : l'ajustement à l'échelle logarithmique
Cet ajustement fonctionne en prenant \(z_i = \ln y_i\) et en exécutant une régression linéaire ordinaire de \(z\) en fonction de \(x\). Par conséquent, \(r\) mesure l'ajustement des données transformées en logarithme \(\ln(y)\) sur une ligne droite — non la façon dont les valeurs brutes de \(y\) s'ajustent à la courbe. Une valeur de \(r\) proche de \(+1\) ou \(-1\) indique une relation exponentielle forte ; le signe correspond à la direction (positif pour la croissance, négatif pour la décroissance).
En utilisant les bandes standard d'interprétation de corrélation pour \(|r|\) :
- 0.9 – 1.0 : ajustement très fort — les données suivent étroitement le modèle exponentiel.
- 0.7 – 0.9 : ajustement fort — l'exponentielle est une bonne description avec une certaine dispersion.
- 0.5 – 0.7 : ajustement modéré — une tendance existe mais d'autres facteurs sont en jeu.
- en dessous de 0.5 : ajustement faible — un modèle exponentiel peut ne pas être approprié.
Parce que \(r\) reflète l'ajustement à l'échelle logarithmique, un \(r\) élevé ne garantit pas de petites erreurs sur l'échelle \(y\) originale ; les grandes valeurs de \(y\) sont pondérées moins fortement après la transformation \(\ln\). Tracez toujours la courbe ajustée par rapport à vos données brutes comme vérification de cohérence.
FAQ
Pourquoi y doit-il être positif ? L'ajustement repose sur \(\ln(y)\), or le logarithme de zéro ou d'un nombre négatif n'est pas défini.
Que signifie r ici ? C'est la corrélation entre x et ln(y). Repère utile : \(0{,}7 < |r| \le 1\) forte, \(0{,}4 < |r| < 0{,}7\) modérée, \(0{,}2 < |r| < 0{,}4\) faible, en dessous de 0,2 inexistante.
Et si toutes mes valeurs de x sont identiques ? Alors \(S_{xx} = 0\) et la pente n'est pas définie : fournissez au moins deux valeurs de x distinctes.