指数回帰とは
指数回帰とは、対になった観測データに \(y = A \cdot B^{x}\) という形の曲線を当てはめる手法です。xが1単位増えるごとに、ある量がほぼ一定の倍率で増加(または減少)する場面で最適なツールといえます。人口増加、複利計算、放射性崩壊、細菌の培養など、自然界の多くの現象に当てはまります。地域や国ごとのルールに左右されない、普遍的な統計手法です。
使い方
データは1行に1組ずつ、x,y の形式で入力してください。点は最低2つ必要で、すべてのxが同じ値であってはなりません。また、すべてのyは正の値である必要があります(この手法はyの自然対数をとるため)。表示する桁数を選べば、係数A・Bと相関係数rが表示されます。
計算式の解説
このモデルは非線形ですが、対数をとると線形になります。すなわち \(\ln(y) = \ln(A) + x \cdot \ln(B)\) です。そこで、変換した点 \((x_i, \ln y_i)\) に対して通常の最小二乗法による直線当てはめを行います。xの平均を \(\bar{x}\)、ln yの平均を \(\overline{\ln y}\) とすると、 $$S_{xx} = \sum (x_i - \bar{x})^2, \quad S_{yy} = \sum (\ln y_i - \overline{\ln y})^2, \quad S_{xy} = \sum (x_i - \bar{x})(\ln y_i - \overline{\ln y})$$ と定義できます。これより $$B = \exp\!\left(\frac{S_{xy}}{S_{xx}}\right), \quad A = \exp\!\left(\overline{\ln y} - \bar{x} \cdot \ln B\right), \quad r = \frac{S_{xy}}{\sqrt{S_{xx}}\,\sqrt{S_{yy}}}$$ が求まります。
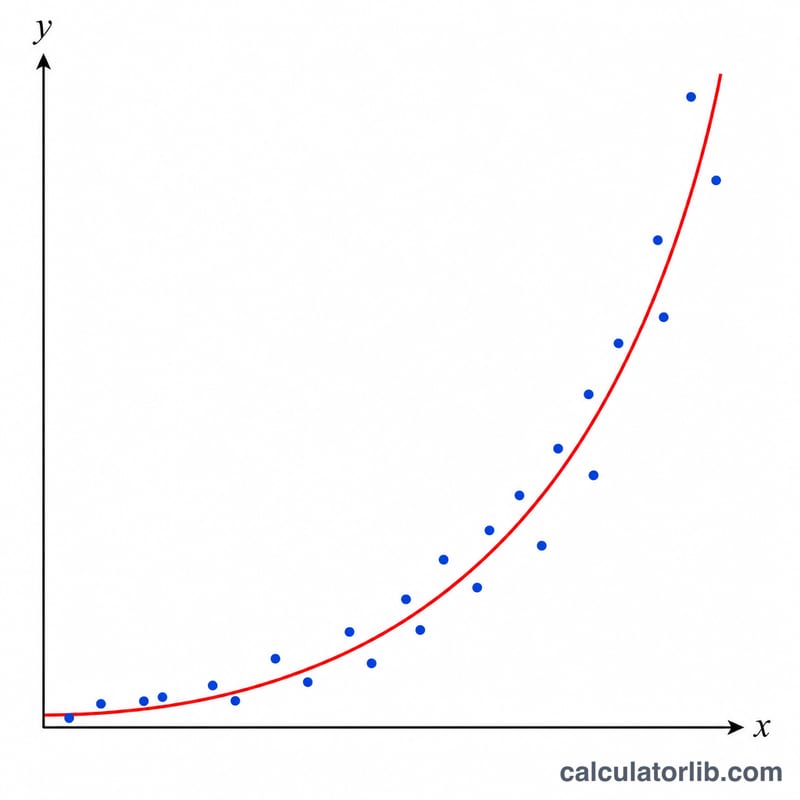
計算例
点 (1, 2.7)、(2, 7.4)、(3, 20.1)、(4, 54.6)、(5, 148.4) の場合:\(n = 5\)、\(\bar{x} = 3\)、\(\overline{\ln y} \approx 2.99906\) です。\(S_{xx} = 10\)、\(S_{xy} \approx 10.01167\)、\(S_{yy} \approx 10.02337\) となります。したがって $$B = \exp(1.001167) \approx 2.7215, \quad A = \exp(2.99906 - 3 \cdot 1.001167) \approx 0.9956, \quad r \approx 0.99999985$$ です。当てはめたモデル \(y \approx 0.9956 \cdot 2.7215^{x}\) は、元の \(y \approx e^{x}\) によく一致しています。
結果の解釈
指数回帰は3つの数値 — \(A\)、\(B\) および \(r\) — を返し、これらが一緒にモデル \(y = A \cdot B^{\,x}\) を説明します。各数値の読み方は以下の通りです。
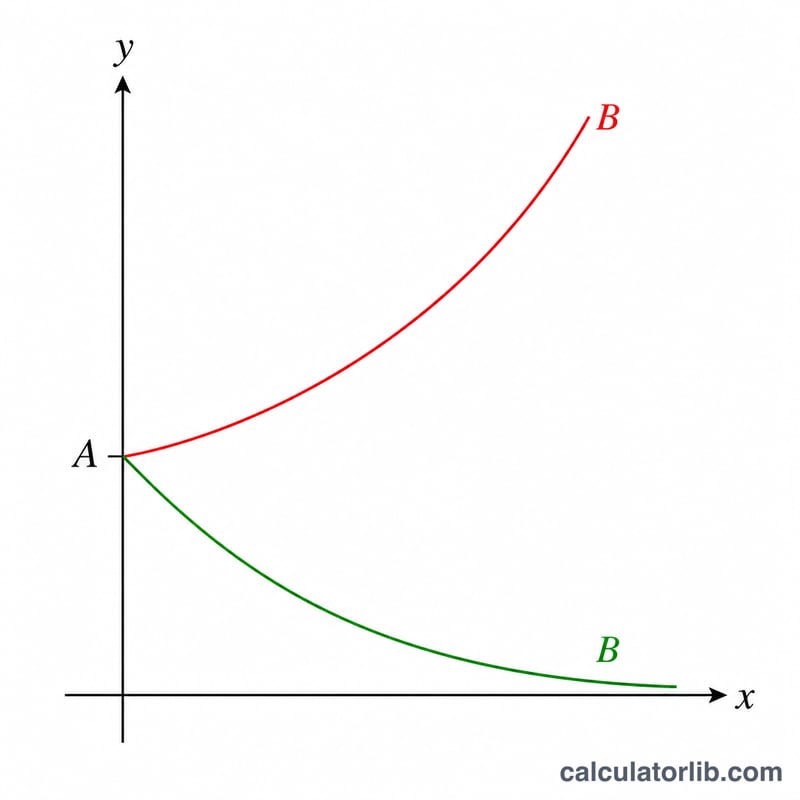
底 \(B\):成長または減衰
底 \(B\) は、\(x\) が1単位増加するたびに \(y\) の変化の方向と速度を制御します:
- \(B > 1\) は成長を意味します。 \(x\) のステップごとに \(y\) に \(B\) を掛けるため、曲線は上昇します。単位あたりのパーセンテージ変化は \((B-1)\times100\%\) です。例えば、\(B = 1.08\) は 1単位あたり8% の成長に相当します。
- \(B < 1\) は減衰を意味します。 各ステップで \(y\) に1より小さい値を掛けるため、曲線はゼロに向かって低下します。同じ式 \((B-1)\times100\%\) は負の結果を与えます。例えば、\(B = 0.85\) は単位あたり \(-15\%\) の変化です。
- \(B = 1\) は平坦です。 \(y\) は \(x\) に関係なく \(A\) に等しいままです(ゼロパーセント変化)。
係数 \(A\):y切片
\(A\) は \(x = 0\) のときの \(y\) の値です。なぜなら \(A \cdot B^{0} = A\) だからです。曲線を垂直に固定し、開始量、初期集団、元本、または\(x\)軸の原点での用量を表します。
相関係数 \(r\):対数スケールでの適合度
このフィッティングは \(z_i = \ln y_i\) を取得し、\(z\) を \(x\) に対して通常の線形回帰を実行することで機能します。その結果、\(r\) は対数変換されたデータ \(\ln(y)\) がどの程度よく直線上に落ちるかを測定します — 生の \(y\) 値が曲線にどの程度よく適合するかではありません。\(r\) が \(+1\) または \(-1\) に近い値は強い指数関係を示します。符号は方向と一致します(成長の場合は正、減衰の場合は負)。
\(|r|\) の標準的な相関解釈帯を使用すると:
- 0.9 – 1.0:非常に強い適合 — データは指数モデルに密接に従います。
- 0.7 – 0.9:強い適合 — 指数は適切な説明ですが、いくつかの散らばりがあります。
- 0.5 – 0.7:中程度の適合 — トレンドが存在しますが、他の要因も作用しています。
- 0.5以下:弱い適合 — 指数モデルは適切でない可能性があります。
\(r\) は対数スケールでの適合度を反映しているため、高い \(r\) は元の \(y\) スケールでの誤差が小さいことを保証しません。\(\ln\) 変換後、大きな \(y\) 値はより小さい重みを持ちます。常にフィッティングされた曲線を生のデータに対してプロットして、妥当性をチェックしてください。
よくある質問
なぜyは正の値でなければならないのですか? この当てはめは \(\ln(y)\) に対して行うため、0や負の数の対数は定義できないからです。
ここでのrは何を意味しますか? xと \(\ln(y)\) の相関を表します。目安として、\(0.7 < |r| \le 1\) で強い相関、\(0.4 < |r| < 0.7\) で中程度、\(0.2 < |r| < 0.4\) で弱い相関、0.2未満で相関なしと判断します。
xの値がすべて同じ場合はどうなりますか? その場合 \(S_{xx} = 0\) となり、傾きが定義できません。少なくとも2つの異なるxの値を入力してください。