この計算ツールでできること
このツールは、度数分布表の形式で入力したデータに ab指数 型の回帰曲線 \(y = A\cdot B^{x}\) を当てはめます。各行には x の値、y の値、そして度数 \(f\)(その (x, y) の組が出現する回数、または重み)を指定します。これは純粋な統計手法であり、単位や国・地域に依存せず、どこでもまったく同じように使えます。
使い方
1行につき1つのデータ点を x, y, f の形式で入力します。この手法は y の自然対数をとるため、y の値は必ず正(0より大きい)でなければなりません。重みを付けない通常の回帰を行いたい場合は、すべての度数を 1 に設定してください(3番目の数値を省略した場合も f = 1 とみなされます)。表示する係数の有効桁数を選び、係数 A・B と相関係数 r を読み取ります。
計算式の解説
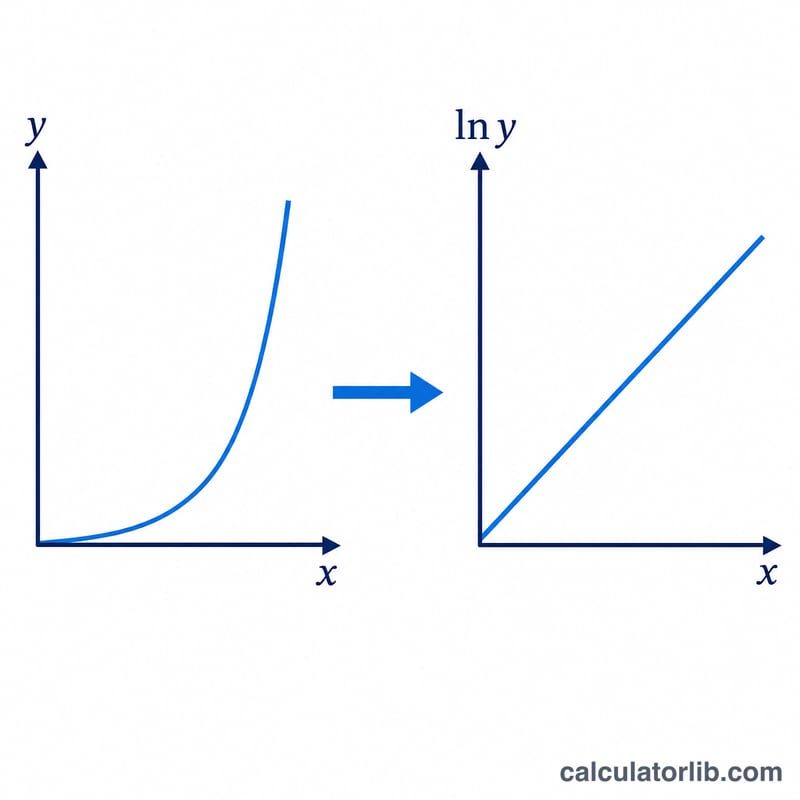
ポイントはモデルを線形化することです。\(y = A\cdot B^{x}\) の両辺の対数をとると \(\ln y = \ln A + x\cdot\ln B\) となり、(x, ln y) 空間における直線になります。ここで ln y を x で度数加重の最小二乗回帰します。\(n = \sum f\) とし、加重平均 \(\bar{x}\)・\(\overline{\ln y}\)、加重和 \(S_{xx}\)・\(S_{yy}\)・\(S_{xy}\) を用いると、傾きは \(S_{xy}/S_{xx}\)、切片は \(\overline{\ln y} - \bar{x}\cdot\text{傾き}\) で求まります。これを指数関数に戻すと \(B = e^{\text{傾き}}\)、\(A = e^{\text{切片}}\) となります。相関係数 $$y = A \cdot B^{x}, \qquad B = e^{\,S_{xy}/S_{xx}}, \quad A = e^{\,\overline{\ln y} - \bar{x}\,(S_{xy}/S_{xx})}$$ $$\text{where}\quad \left\{ \begin{aligned} n &= \textstyle\sum f, \quad \bar{x} = \frac{\sum f x}{n}, \quad \overline{\ln y} = \frac{\sum f \ln y}{n} \\ S_{xx} &= \textstyle\sum f x^{2} - n\,\bar{x}^{2} \\ S_{xy} &= \textstyle\sum f\,x \ln y - n\,\bar{x}\,\overline{\ln y} \\ x,\,y,\,f &= \text{Data points (x, y, f)} \end{aligned} \right.$$ \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\) は、対数線形モデルがどれだけよく当てはまっているかを表します。
計算例
きれいに2倍ずつ増えるデータ (1, 2)、(2, 4)、(3, 8)、(4, 16) をすべて f = 1 として計算すると:\(n = 4\)、\(\bar{x} = 2.5\)、\(\overline{\ln y} = 1.732868\)、\(S_{xx} = 5\)、\(S_{xy} = 3.465735\)、\(S_{yy} = 2.402224\) となります。これより $$B = e^{3.465735/5} = e^{0.693147} = 2, \quad A = e^{0} = 1, \quad r = 1.$$ したがって当てはめた曲線は \(y = 1\cdot 2^{x}\) となり、予想どおりの結果が得られます。
よくある質問
度数の列にはどんな意味がありますか? 各データ点が出現する回数に応じて重みを付けるものです。f = 5 の行は、同じ行が5つあるのと同じ扱いになります。すべて f = 1 にすれば通常の回帰になります。
相関係数 r はどう読めばよいですか? |r| > 0.7 なら強い相関、0.4–0.7 はやや相関あり、0.2–0.4 は弱い相関、0.2 未満ならほとんど相関なしと判断します。r は (x, ln y) 空間で計算されます。
なぜ y は正でなければならないのですか? このモデルは y の自然対数をとりますが、y ≤ 0 では ln y が定義できないためです。したがって 0 以下の行は無視されます。