這個計算器的功能
本工具會針對一份次數分配表,擬合形如 \(y = A\cdot B^{x}\) 的 ab 指數趨勢線。每一列資料都包含一個 x 值、一個 y 值,以及一個頻率 \(f\)(也就是該組 (x, y) 出現的次數或權重)。這是一套純粹的統計方法,在任何地方的計算結果都完全一致──沒有單位限制,也不受任何國家或法規影響。
使用方式
每行輸入一筆資料,格式為 x, y, f。由於計算過程會對 y 取自然對數,因此 y 值必須嚴格大於 0。若你想做一般未加權的擬合,只要把每一筆的頻率都設為 1 即可(也可以省略第三個數字,系統會自動視為 f = 1)。接著選擇輸出係數要顯示的有效位數,就能讀出 A、B 與相關係數 r。
公式原理
關鍵技巧在於把模型「線性化」:對 \(y = A\cdot B^{x}\) 兩邊取對數,可得 \(\ln y = \ln A + x\cdot\ln B\),在 (x, ln y) 座標中就是一條直線。我們對 ln y 與 x 進行頻率加權的最小平方迴歸。令 \(n = \sum f\),加權平均數為 \(\bar{x}\) 與 \(\overline{\ln y}\),加權平方和為 \(S_{xx}\)、\(S_{yy}\)、\(S_{xy}\),則斜率為 \(S_{xy}/S_{xx}\),截距為 \(\overline{\ln y} - \bar{x}\cdot\text{斜率}\)。再取指數還原,即得 \(B = e^{\text{斜率}}\) 與 \(A = e^{\text{截距}}\)。相關係數 \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\),用來衡量此對數線性模型的擬合程度。完整公式如下:
$$y = A \cdot B^{x}, \qquad B = e^{\,S_{xy}/S_{xx}}, \quad A = e^{\,\overline{\ln y} - \bar{x}\,(S_{xy}/S_{xx})}$$ $$\text{where}\quad \left\{ \begin{aligned} n &= \textstyle\sum f, \quad \bar{x} = \frac{\sum f x}{n}, \quad \overline{\ln y} = \frac{\sum f \ln y}{n} \\ S_{xx} &= \textstyle\sum f x^{2} - n\,\bar{x}^{2} \\ S_{xy} &= \textstyle\sum f\,x \ln y - n\,\bar{x}\,\overline{\ln y} \\ x,\,y,\,f &= \text{Data points (x, y, f)} \end{aligned} \right.$$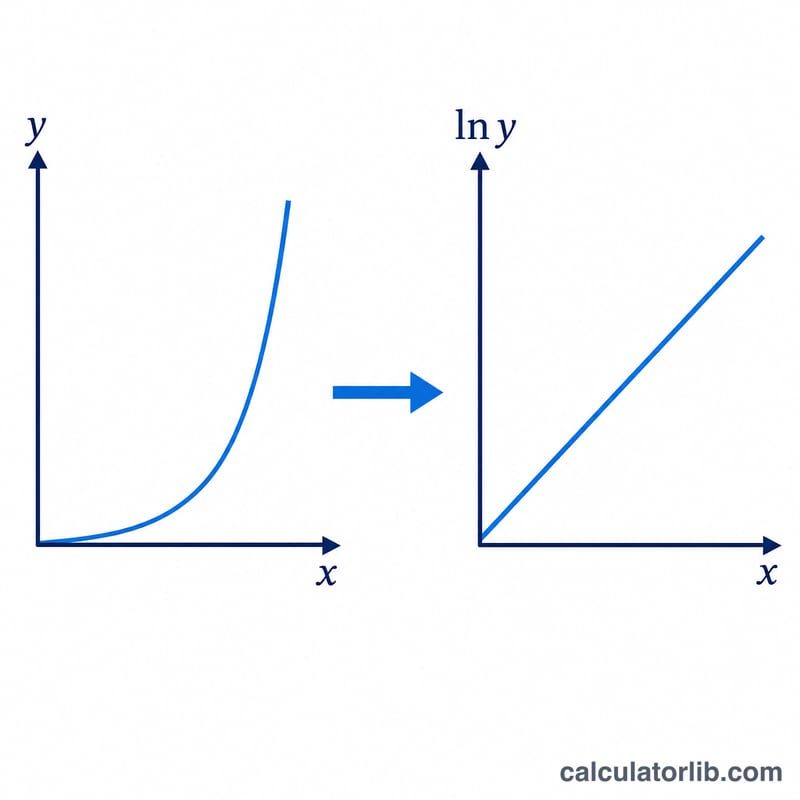
實際範例
以完美倍增的資料 (1, 2)、(2, 4)、(3, 8)、(4, 16),且 f 皆為 1 為例:\(n = 4\),\(\bar{x} = 2.5\),\(\overline{\ln y} = 1.732868\),\(S_{xx} = 5\),\(S_{xy} = 3.465735\),\(S_{yy} = 2.402224\)。於是 \(B = e^{3.465735/5} = e^{0.693147} = 2\),\(A = e^{0} = 1\),\(r = 1\)。因此擬合出的曲線正是 \(y = 1\cdot 2^{x}\),與預期完全吻合。
常見問題
頻率欄位有什麼作用?它會依照每筆資料出現的次數加以加權,所以 f = 5 的一列,效果等同於五筆相同的資料。若要做一般迴歸,把所有 f 都設為 1 即可。
該如何解讀 r?|r| > 0.7 代表高度相關,0.4~0.7 為中度,0.2~0.4 為低度,低於 0.2 則幾乎沒有相關性。r 是在 (x, ln y) 座標中計算的。
為什麼 y 必須為正?因為模型要對 y 取自然對數,而當 y ≤ 0 時 ln y 沒有定義,因此非正值的資料列會被自動忽略。