Что делает этот калькулятор
Этот инструмент подбирает ab-экспоненциальную линию тренда вида \(y = A\cdot B^{x}\) по таблице данных с распределением частот. В каждой строке указываются значение x, значение y и частота \(f\) — то, сколько раз встречается пара (x, y), или её вес. Это чисто статистический метод, который работает одинаково в любой стране: без единиц измерения и без привязки к законодательству.
Как пользоваться
Вводите по одной точке данных в строке в формате x, y, f. Значение y должно быть строго положительным, поскольку метод берёт натуральный логарифм от y. Если нужна обычная регрессия без весов, поставьте каждой частоте значение 1 (третье число можно и опустить — тогда принимается \(f = 1\)). Выберите число значащих цифр для вывода коэффициентов и считайте готовые A, B и коэффициент корреляции r.
Разбор формулы
Хитрость в том, чтобы линеаризовать модель: после логарифмирования \(y = A\cdot B^{x}\) получаем \(\ln y = \ln A + x\cdot\ln B\) — прямую линию в координатах (x, ln y). Мы выполняем взвешенную по частоте регрессию методом наименьших квадратов для ln y по x. При \(n = \sum f\), взвешенных средних \(\bar{x}\) и \(\overline{\ln y}\) и взвешенных суммах \(S_{xx}\), \(S_{yy}\), \(S_{xy}\) угловой коэффициент равен \(S_{xy}/S_{xx}\), а свободный член — \(\overline{\ln y} - \bar{x}\cdot\text{наклон}\). После потенцирования получаем \(B = e^{\text{наклон}}\) и \(A = e^{\text{свободный член}}\). Коэффициент корреляции \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\) показывает, насколько хорошо логлинейная модель описывает данные.
$$ y = A \cdot B^{x}, \qquad B = e^{\,S_{xy}/S_{xx}}, \quad A = e^{\,\overline{\ln y} - \bar{x}\,(S_{xy}/S_{xx})} $$ $$ \text{where}\quad \left\{ \begin{aligned} n &= \textstyle\sum f, \quad \bar{x} = \frac{\sum f x}{n}, \quad \overline{\ln y} = \frac{\sum f \ln y}{n} \\ S_{xx} &= \textstyle\sum f x^{2} - n\,\bar{x}^{2} \\ S_{xy} &= \textstyle\sum f\,x \ln y - n\,\bar{x}\,\overline{\ln y} \\ x,\,y,\,f &= \text{Data points (x, y, f)} \end{aligned} \right. $$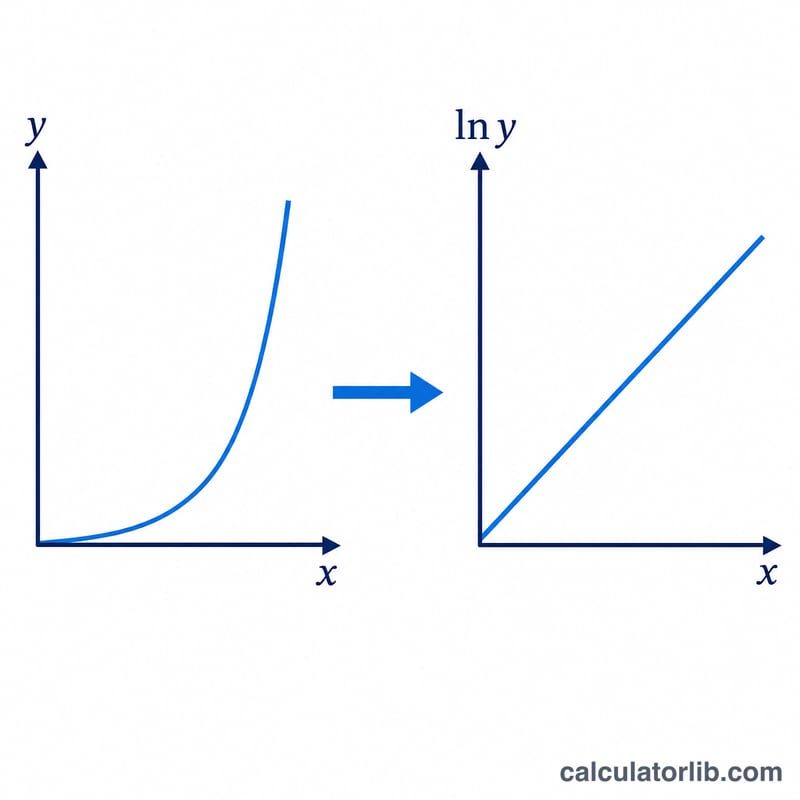
Разобранный пример
Возьмём идеально удваивающиеся данные (1, 2), (2, 4), (3, 8), (4, 16), все с \(f = 1\): \(n = 4\), \(\bar{x} = 2.5\), \(\overline{\ln y} = 1.732868\), \(S_{xx} = 5\), \(S_{xy} = 3.465735\), \(S_{yy} = 2.402224\). Тогда $$B = e^{3.465735/5} = e^{0.693147} = 2,$$ \(A = e^{0} = 1\) и \(r = 1\). Подобранная кривая получается \(y = 1\cdot 2^{x}\) — ровно то, что и ожидалось.
Частые вопросы
Зачем нужен столбец частоты? Он задаёт вес каждой точке в зависимости от того, как часто она встречается: строка с \(f = 5\) эквивалентна пяти одинаковым строкам. Для обычной регрессии поставьте везде \(f = 1\).
Как трактовать r? \(|r| > 0.7\) — сильная корреляция, 0.4–0.7 — умеренная, 0.2–0.4 — слабая, ниже 0.2 — практически отсутствует. Значение r вычисляется в координатах (x, ln y).
Почему y должно быть положительным? Модель берёт натуральный логарифм от y, а ln y не определён при \(y \le 0\), поэтому строки с неположительным y игнорируются.