이 계산기의 기능
이 도구는 빈도 분포표 형태의 데이터에 \(y = A \cdot B^{x}\) 꼴의 ab-지수 추세선을 적합합니다. 각 행은 x 값, y 값, 그리고 빈도 \(f\)(해당 (x, y) 쌍이 나타나는 횟수 또는 가중치)로 구성됩니다. 단위나 특정 국가 규정에 얽매이지 않는 순수 통계 기법으로, 어디서나 동일하게 적용됩니다.
사용 방법
한 줄에 하나씩 데이터 점을 x, y, f 형식으로 입력하세요. 이 방법은 y에 자연로그를 취하므로 y 값은 반드시 양수여야 합니다. 가중치를 적용하지 않는 일반 회귀를 원한다면 모든 빈도를 1로 설정하면 됩니다(세 번째 숫자를 생략하면 f = 1로 간주합니다). 표시할 계수의 유효숫자 자릿수를 선택한 뒤 A, B, 상관계수 r 값을 확인하세요.
공식 설명
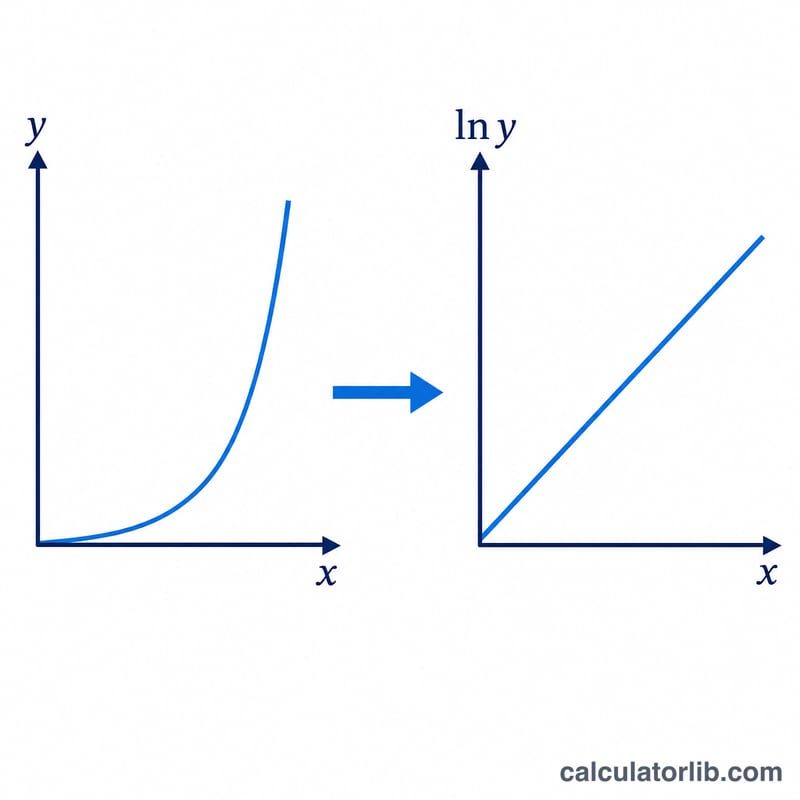
핵심은 모델을 선형화하는 것입니다. \(y = A \cdot B^{x}\)의 양변에 로그를 취하면 \(\ln y = \ln A + x \cdot \ln B\)가 되어 (x, ln y) 공간에서 직선이 됩니다. 여기에 x에 대한 ln y의 빈도 가중 최소제곱 회귀를 수행합니다.
$$y = A \cdot B^{x}, \qquad B = e^{\,S_{xy}/S_{xx}}, \quad A = e^{\,\overline{\ln y} - \bar{x}\,(S_{xy}/S_{xx})}$$$$\text{where}\quad \left\{ \begin{aligned} n &= \textstyle\sum f, \quad \bar{x} = \frac{\sum f x}{n}, \quad \overline{\ln y} = \frac{\sum f \ln y}{n} \\ S_{xx} &= \textstyle\sum f x^{2} - n\,\bar{x}^{2} \\ S_{xy} &= \textstyle\sum f\,x \ln y - n\,\bar{x}\,\overline{\ln y} \\ x,\,y,\,f &= \text{Data points (x, y, f)} \end{aligned} \right.$$n = \(\sum f\), 가중 평균 \(\bar{x}\)와 \(\overline{\ln y}\), 가중 합 \(S_{xx}\), \(S_{yy}\), \(S_{xy}\)를 사용할 때 기울기는 \(S_{xy}/S_{xx}\), 절편은 \(\overline{\ln y} - \bar{x} \cdot \text{기울기}\)입니다. 이를 지수화하면 \(B = e^{\text{기울기}}\), \(A = e^{\text{절편}}\)이 됩니다. 상관계수 \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\)는 로그-선형 모델이 데이터에 얼마나 잘 맞는지를 나타냅니다.
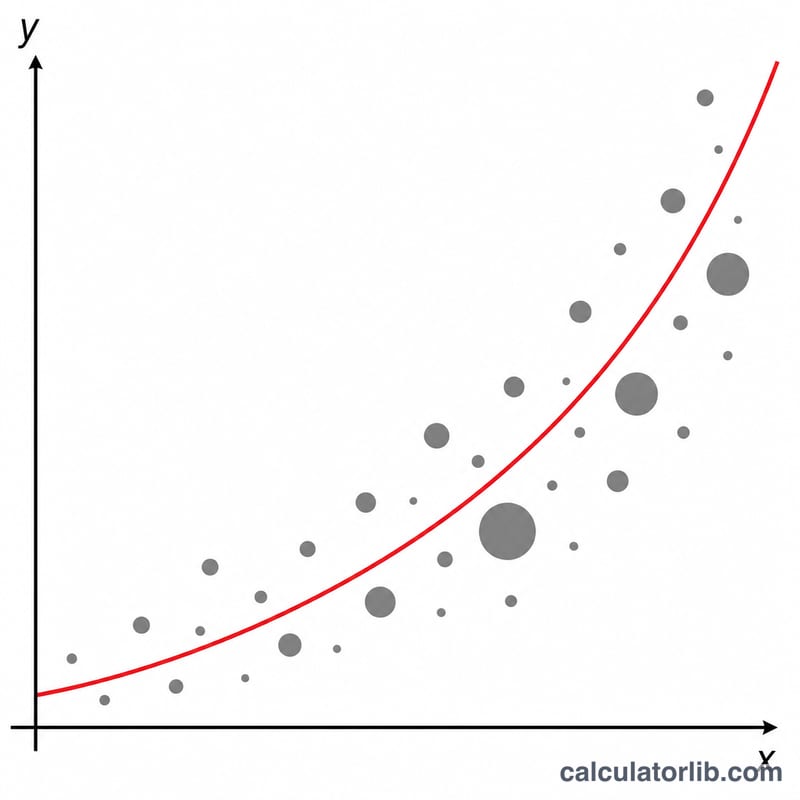
계산 예시
정확히 2배씩 증가하는 데이터 (1, 2), (2, 4), (3, 8), (4, 16)이 모두 f = 1인 경우: n = 4, \(\bar{x} = 2.5\), \(\overline{\ln y} = 1.732868\), \(S_{xx} = 5\), \(S_{xy} = 3.465735\), \(S_{yy} = 2.402224\)입니다. 따라서 $$B = e^{3.465735/5} = e^{0.693147} = 2, \quad A = e^{0} = 1, \quad r = 1$$이 됩니다. 즉 적합된 곡선은 \(y = 1 \cdot 2^{x}\)로, 예상과 정확히 일치합니다.
자주 묻는 질문
빈도 열은 무슨 역할을 하나요? 각 데이터 점이 나타나는 횟수만큼 가중치를 부여합니다. 즉 f = 5인 행은 동일한 행 다섯 개와 같은 효과를 냅니다. 일반 회귀를 원한다면 모든 f를 1로 두세요.
r은 어떻게 해석하나요? |r| > 0.7이면 강한 상관관계, 0.4–0.7이면 중간, 0.2–0.4이면 약함, 0.2 미만이면 사실상 상관관계가 없음을 의미합니다. r은 (x, ln y) 공간에서 계산됩니다.
왜 y는 양수여야 하나요? 이 모델은 y에 자연로그를 취하는데, y ≤ 0일 때는 ln y가 정의되지 않습니다. 따라서 양수가 아닌 행은 무시됩니다.





