지수 회귀란?
지수 회귀는 짝지어진 데이터 점들에 \(y = A\cdot e^{Bx}\) 형태의 곡선을 맞추는 분석 기법입니다. 인구 증가, 방사성 붕괴, 복리 이자, 세균 배양처럼 현재 크기에 비례하는 속도로 증가하거나 감소하는 현상을 모델링할 때 표준적으로 쓰입니다. 이 계산기는 순수한 수학·통계 도구이므로 특정 국가의 가정 없이 어디서나 동일하게 적용됩니다.
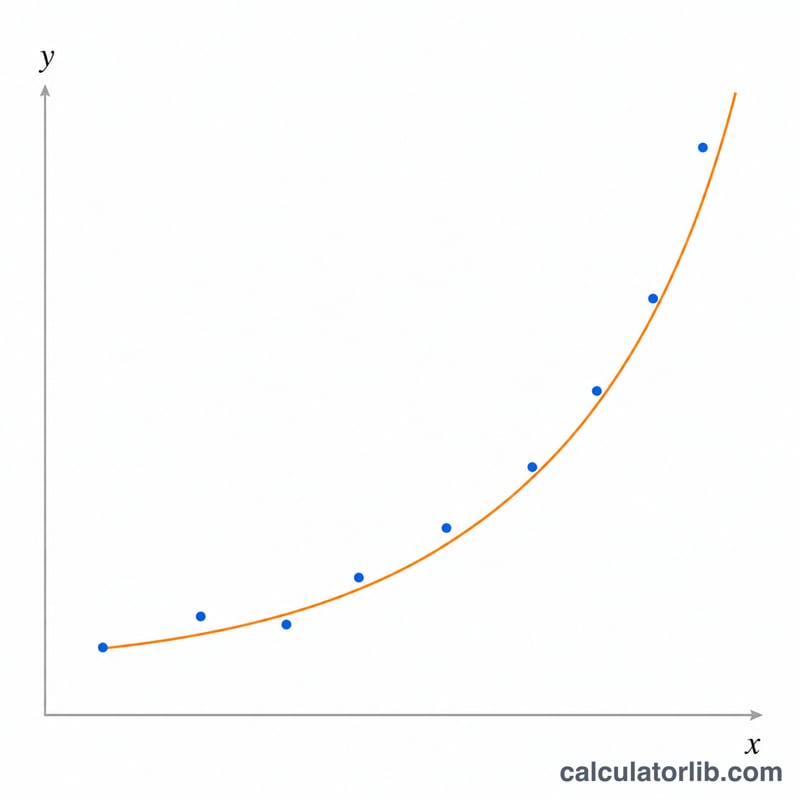
사용 방법
독립 변수 값은 X 값 칸에, 종속 변수 값은 Y 값 칸에 각각 쉼표로 구분해 입력하세요. 두 목록의 개수는 반드시 같아야 하며, 점은 최소 2개 이상 필요합니다. 또한 모든 Y 값은 반드시 양수여야 합니다(이 방법은 y의 자연로그를 사용하기 때문입니다). 표시 자릿수를 선택한 뒤, 적합된 계수 A와 B, 상관계수 r, 그리고 완성된 방정식을 확인하면 됩니다.
공식 풀이
\(y = A\cdot e^{Bx}\)는 비선형이기 때문에, 자연로그를 취해 선형으로 바꿉니다: \(\ln y = \ln A + B\cdot x\). 이렇게 하면 x에 대한 \(\ln(y)\)의 일반적인 선형 회귀가 됩니다. 중심화된 합 $$S_{xx} = \sum (x - \bar{x})^2, \quad S_{yy} = \sum (\ln y - \overline{\ln y})^2, \quad S_{xy} = \sum (x - \bar{x})(\ln y - \overline{\ln y})$$ 을 사용하면 기울기는 \(B = S_{xy}/S_{xx}\), 그리고 $$A = \exp\!\left(\overline{\ln y} - B\cdot \bar{x}\right)$$ 로 구해집니다. 상관계수 $$r = \frac{S_{xy}}{\sqrt{S_{xx}}\cdot \sqrt{S_{yy}}}$$ 는 \(-1\)과 \(1\) 사이의 값을 가지며, 절댓값이 \(0.7\)을 넘으면 적합도가 높다는 뜻입니다.
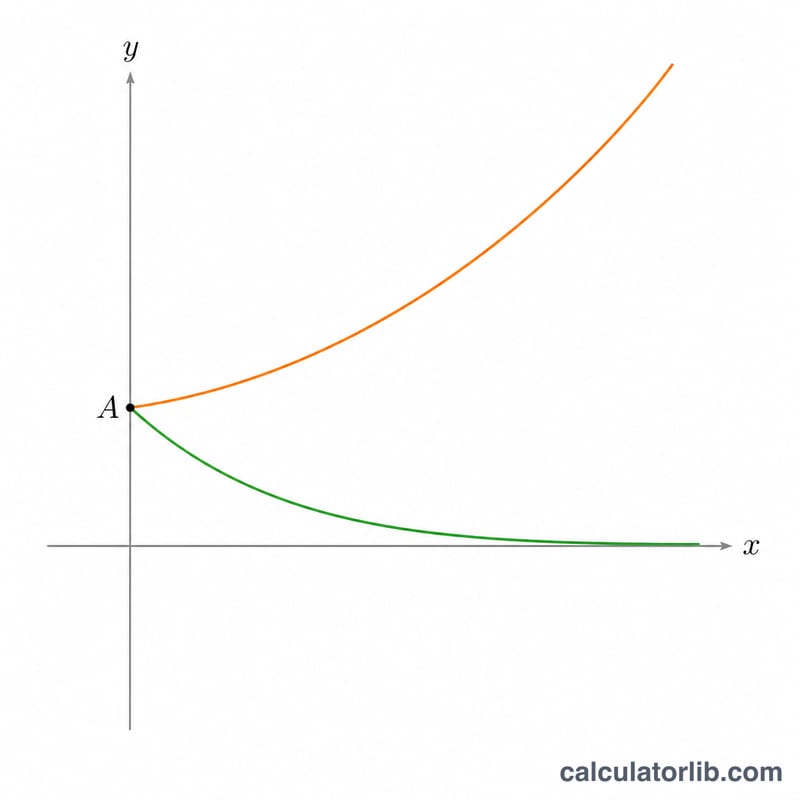
계산 예시
\(x = [1, 2, 3, 4, 5]\), \(y = [2.7, 7.4, 20.1, 54.6, 148.4]\)(대략 \(e^{x}\))인 경우, \(S_{xx} = 10\), \(S_{xy} \approx 10.0115\), \(S_{yy} \approx 10.0231\)이 됩니다. 그러면 \(B \approx 1.0012\), \(A \approx 0.9956\), \(r \approx 1.0000\)입니다. 적합된 곡선 $$y \approx 0.9956\cdot e^{1.0012x}$$ 는 데이터가 \(y = e^{x}\)에서 나왔음을 확인해 줍니다.
자주 묻는 질문
Y 값은 왜 양수여야 하나요? 이 방법은 \(\ln(y)\)를 사용하는데, 0이나 음수의 로그는 정의되지 않기 때문입니다. 그래서 0 이하의 Y 값은 입력에서 제외됩니다.
r이 1에 가까우면 무슨 뜻인가요? 지수 모델이 데이터를 매우 잘 설명한다는 의미입니다. 반대로 0에 가까우면 지수 관계가 거의 없거나 전혀 없다는 뜻입니다.
x가 음수여도 되나요? 네, 됩니다. X는 어떤 실수든 가능하며, 양수로 제한되는 것은 Y뿐입니다.