e指数回帰とは
e指数回帰は、対になったデータ点の集合に対して \(y = A\cdot e^{Bx}\) という形の曲線を当てはめる手法です。現在の大きさに比例した速さで増加・減少する量をモデル化する定番の方法で、人口の増加、放射性物質の崩壊、複利計算、細菌の培養などに広く使われます。この計算ツールは純粋な数学・統計の道具であり、特定の国の制度や前提に依存しないため、どの国でもまったく同じように利用できます。
使い方
独立変数の値を X値 の欄に、従属変数の値を Y値 の欄に、それぞれカンマ区切りの数値として入力します。2つのリストは要素数を同じにする必要があり、データ点は最低2つ必要です。また、すべてのY値は厳密に正の数でなければなりません(この手法ではyの自然対数をとるため)。表示する桁数(精度)を選べば、当てはめた係数A・B、相関係数r、そして組み立てられた式が表示されます。
計算式の解説
\(y = A\cdot e^{Bx}\) は非線形のため、自然対数をとって線形化します:\(\ln y = \ln A + B\cdot x\)。これは \(\ln(y)\) を \(x\) に対して回帰する、通常の線形回帰に帰着します。中心化した和 \(S_{xx} = \sum (x - \bar{x})^2\)、\(S_{yy} = \sum (\ln y - \overline{\ln y})^2\)、\(S_{xy} = \sum (x - \bar{x})(\ln y - \overline{\ln y})\) を用いると、傾きは $$B = \frac{S_{xy}}{S_{xx}}$$ そして $$A = \exp\!\left(\overline{\ln y} - B\cdot\bar{x}\right)$$ で求まります。相関係数 $$r = \frac{S_{xy}}{\sqrt{S_{xx}}\cdot\sqrt{S_{yy}}}$$ は \(-1\) から \(1\) の範囲をとり、絶対値が \(0.7\) を超えると強い当てはまりを示します。
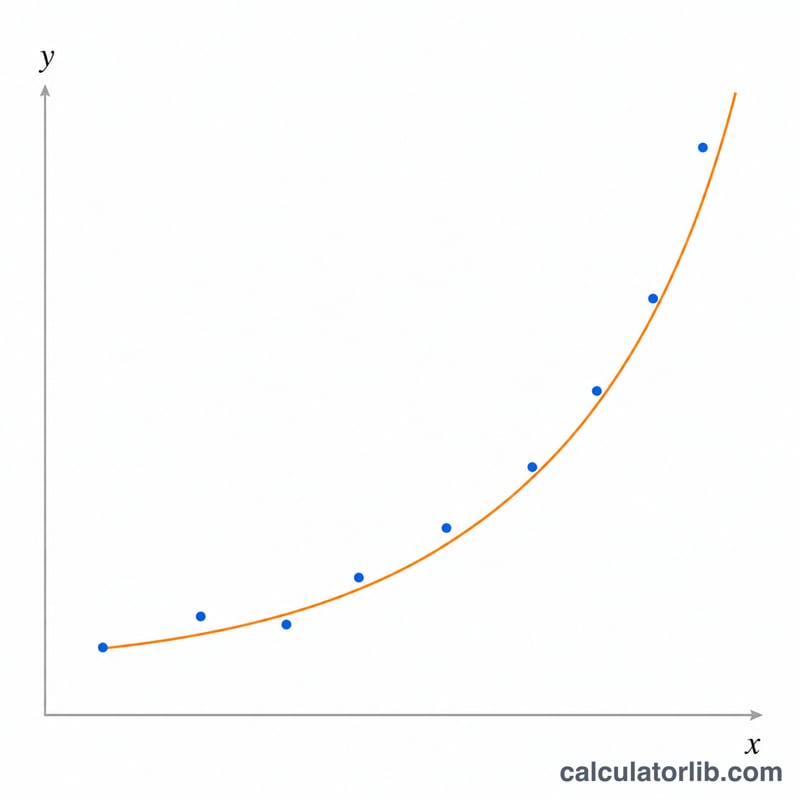
計算例
\(x = [1, 2, 3, 4, 5]\)、\(y = [2.7, 7.4, 20.1, 54.6, 148.4]\)(およそ \(e^{x}\))の場合、\(S_{xx} = 10\)、\(S_{xy} \approx 10.0115\)、\(S_{yy} \approx 10.0231\) となります。これより \(B \approx 1.0012\)、\(A \approx 0.9956\)、\(r \approx 1.0000\)。当てはめた曲線 $$y \approx 0.9956\cdot e^{1.0012x}$$ は、データが \(y = e^{x}\) から得られたものであることを裏付けています。
よくある質問
なぜYは正の数でなければならないのですか? この手法では \(\ln(y)\) を計算します。0や負の数の対数は定義されないため、0以下のY値は受け付けられません。
rが1に近いとは何を意味しますか? 指数モデルがデータを非常によく説明していることを意味します。0に近い場合は、指数関係がほとんどない、または存在しないことを示します。
xは負の数でも構いませんか? はい。Xは任意の実数で構いません。正の数に限定されるのはYだけです。