この計算機でできること
このツールは、度数(重み)付きのデータに対して \(y = A \cdot e^{Bx}\) という形の指数トレンド曲線をあてはめます。各データ行は (x, y, f) の3つ組で、f は度数(重み)、つまりその観測値が何回現れるかを表します。出力されるのは、あてはめた係数 A と B、そして基礎となる線形回帰の相関係数 r です。これは純粋な数学計算であり、国や地域による違いはなく、どこで使っても同じ結果になります。
使い方
1行につき1点を x, y, f の形式で入力します。モデルは自然対数をとって線形化するため、y の値は必ず 0 より大きくしてください。3列目を省略した場合、度数は自動的に 1 として扱われます。表示する有効数字の桁数を選び、A・B・r と、値を代入したあてはめ式を確認しましょう。
計算式の解説
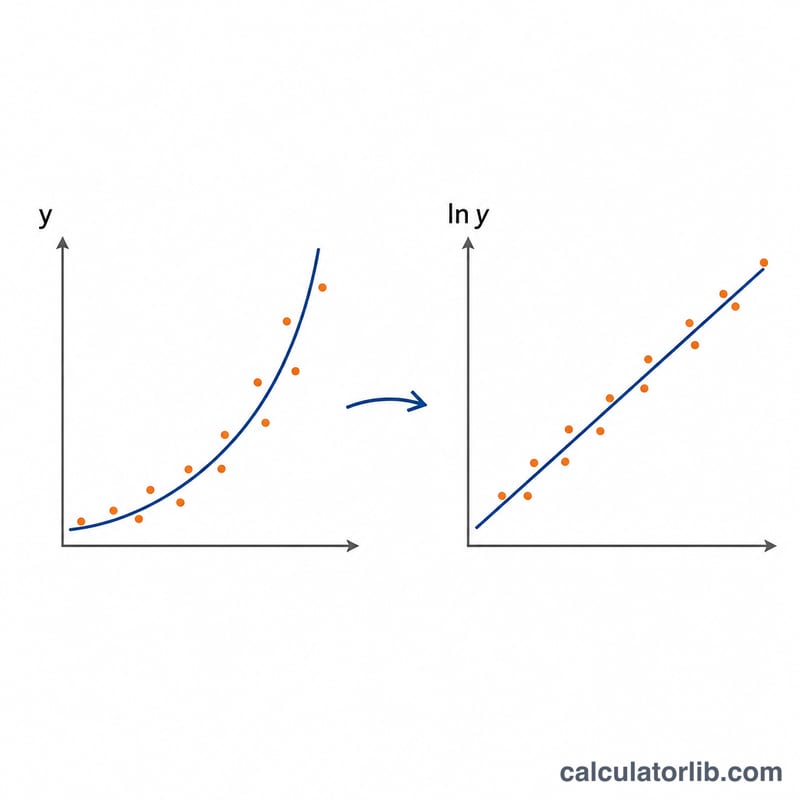
ln y = ln A + B・x という関係から、指数回帰は ln y を x に回帰させる加重線形回帰に帰着します。各項に度数 f を掛けた加重和を用いて、\(n = \sum f\)、加重平均 \(\bar{x}\) と \(\bar{L}\)(ln y の平均)、そして加重平方和 \(S_{xx}\)・\(S_{yy}\) と積和 \(S_{xy}\) を定義します。すると次のようになります。
また \(r = \frac{S_{xy}}{\sqrt{S_{xx}}\cdot\sqrt{S_{yy}}}\) となります。r が ±1 に近いほど、あてはまりが良いことを意味します。
計算例
度数をそれぞれ 1 とした4点 (1, 2.7)、(2, 7.4)、(3, 20.1)、(4, 54.6) を考えます。これらは \(y = e^{x}\) に近い値です。ここで \(\bar{x} = 2.5\)、\(\bar{L} \approx 2.49887\)、\(S_{xx} = 5\)、\(S_{xy} \approx 5.0098\)、\(S_{yy} \approx 5.0196\) となります。したがって \(B \approx 1.0020\)、\(A = e^{\,2.49887 - 2.5048} \approx 0.9940\)、\(r \approx 0.9998\) です。あてはめ式はおよそ $$y = 0.9940 \cdot e^{1.0020\,x}$$ つまりほぼ \(y = e^{x}\) となります。
よくある質問
なぜ y は正の値でなければならないのですか? このあてはめでは \(\ln(y)\) を使います。0 や負の数の対数は定義できないため、そのような行は除外されます。
度数 f は何を表しますか? 各点があてはめにどれだけ強く影響するかを表す重みです。同じ (x, y) を持つ観測値が多数ある度数分布表で特に役立ちます。
r はどう読み取ればよいですか? |r| が 0.7 を超えれば強い相関、0.4〜0.7 で中程度、0.2〜0.4 で弱い相関、0.2 未満ではほとんど相関がないと判断します。