這個計算器的用途
本工具會把形式為 \(y = A \cdot e^{Bx}\) 的指數趨勢曲線,擬合到一組「頻率加權」的資料中。每一筆資料都是一組三元組 (x, y, f),其中 f 代表頻率或權重,也就是該筆觀測值出現的次數。計算後會回傳擬合出的係數 A 與 B,並附上底層線性擬合的相關係數 r。這純粹是數學運算,不受任何地區規則影響,在世界各地的結果都完全一致。
使用方法
每行輸入一個資料點,格式為 x, y, f。由於模型是透過取自然對數來線性化,因此 y 值必須大於 0。如果省略第三欄,頻率會自動預設為 1。接著選擇要顯示的有效位數,即可讀取 A、B、r 以及代入數值後的擬合方程式。
公式解析
因為 \(\ln y = \ln A + B \cdot x\),所以擬合指數曲線其實等同於對 \(\ln y\) 與 \(x\) 進行加權線性迴歸。我們使用加權總和(每一項都乘上頻率 f),定義 \(n = \sum f\)、加權平均數 \(\bar{x}\) 與 \(\bar{L}\)(ln y 的平均)、以及加權平方和 \(S_{xx}\)、\(S_{yy}\) 與交叉乘積 \(S_{xy}\)。於是可得 $$B = \frac{S_{xy}}{S_{xx}}, \quad A = e^{\,\bar{L} - B \cdot \bar{x}}, \quad r = \frac{S_{xy}}{\sqrt{S_{xx}} \cdot \sqrt{S_{yy}}}.$$ 當 r 越接近 \(\pm 1\),代表擬合程度越好。
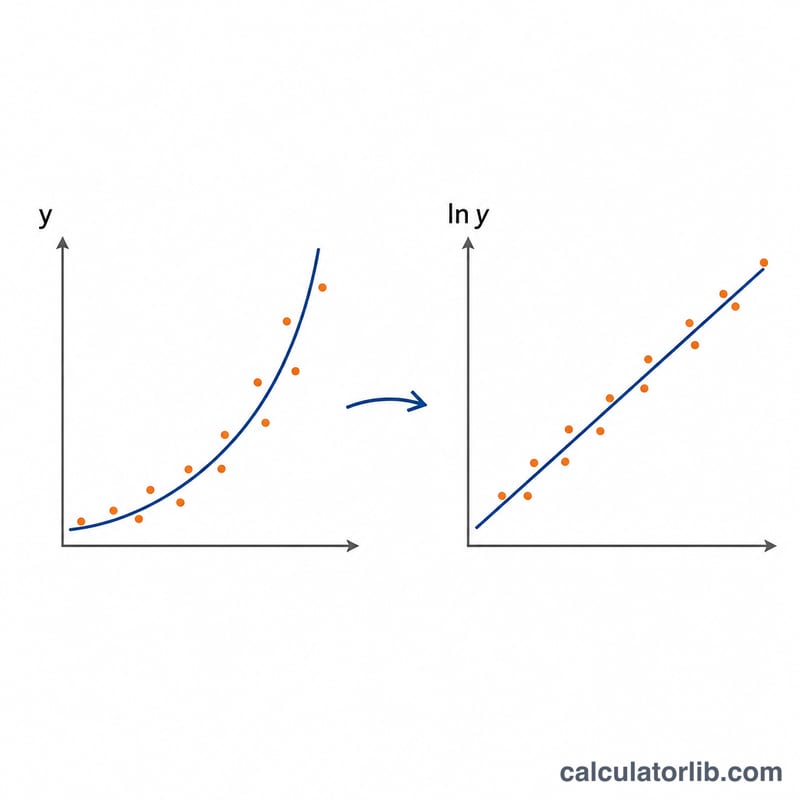
範例演練
取四個點 (1, 2.7)、(2, 7.4)、(3, 20.1)、(4, 54.6),頻率皆為 1,這些點都很接近 \(y = e^{x}\)。計算可得 \(\bar{x} = 2.5\)、\(\bar{L} \approx 2.49887\)、\(S_{xx} = 5\)、\(S_{xy} \approx 5.0098\)、\(S_{yy} \approx 5.0196\)。因此 \(B \approx 1.0020\),\(A = e^{\,(2.49887 - 2.5048)} \approx 0.9940\),\(r \approx 0.9998\)。擬合出的方程式約為 $$y = 0.9940 \cdot e^{\,(1.0020 \cdot x)},$$ 基本上就是 \(y = e^{x}\)。
常見問題
為什麼 y 必須是正數?因為擬合過程會用到 \(\ln(y)\),而 0 或負數的對數沒有定義,所以這類資料列會被排除。
頻率 f 代表什麼?它決定每個資料點對擬合結果的影響力高低,特別適合用在許多觀測值共用同一組 (x, y) 的次數分配表。
該如何解讀 r?\(|r|\) 大於 0.7 表示強相關,0.4–0.7 為中等相關,0.2–0.4 為弱相關,低於 0.2 則幾乎沒有相關性。