这个计算器有什么用
本工具可对一组带频数权重的数据拟合出形如 \(y = A \cdot e^{Bx}\) 的指数趋势曲线。每一行数据由三元组 (x, y, f) 组成,其中 f 表示频数或权重,也就是该观测值出现的次数。计算结果会给出拟合系数 A 和 B,以及对应线性拟合的相关系数 r。这是纯粹的数学计算,适用于任何场景,不涉及任何地区性的特殊规则。
使用方法
每行输入一个数据点,格式为 x, y, f。y 值必须大于 0,因为模型需要先对其取自然对数进行线性化处理。如果省略第三列,频数默认为 1。选择想要显示的有效数字位数后,即可读取 A、B、r 以及代入数值后的拟合方程。
公式原理
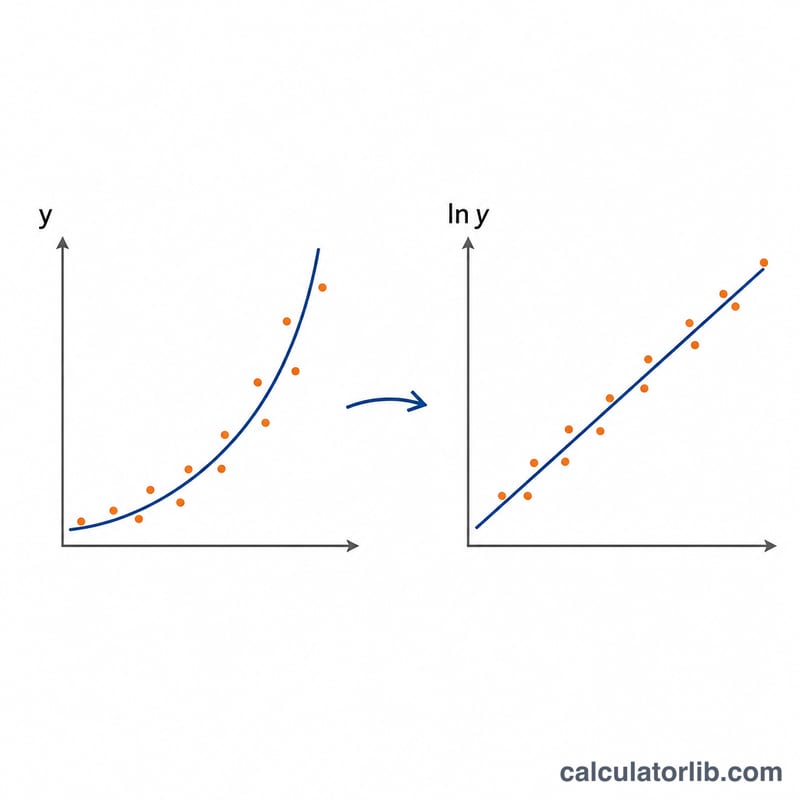
由于 ln y = ln A + B·x,拟合指数曲线实际上就归结为对 ln y 关于 x 做加权线性回归。在加权求和中,每一项都乘以频数 f:令 \(n = \sum f\),并定义加权均值 \(\bar{x}\) 与 \(\bar{L}\)(ln y 的均值),以及加权平方和 \(S_{xx}\)、\(S_{yy}\) 和交叉乘积 \(S_{xy}\)。于是 $$y = A \cdot e^{B x}$$ $$\text{where}\quad \left\{ \begin{aligned} B &= \frac{S_{xy}}{S_{xx}} \\ A &= e^{\,\bar{L} - B\bar{x}} \\ S_{xx} &= \textstyle\sum f x^{2} - n\bar{x}^{2} \\ S_{xy} &= \textstyle\sum f x \ln y - n\bar{x}\bar{L} \\ n &= \textstyle\sum f,\quad \bar{x}=\tfrac{\sum f x}{n},\quad \bar{L}=\tfrac{\sum f \ln y}{n} \end{aligned} \right.$$ \(B = S_{xy} / S_{xx}\),\(A = e^{(\bar{L} - B \cdot \bar{x})}\),\(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\)。当 r 越接近 \(\pm 1\),说明拟合效果越好。
实例演示
取数据点 (1, 2.7)、(2, 7.4)、(3, 20.1)、(4, 54.6),频数均为 1,它们都接近曲线 \(y = e^{x}\)。此时 \(\bar{x} = 2.5\),\(\bar{L} \approx 2.49887\),\(S_{xx} = 5\),\(S_{xy} \approx 5.0098\),\(S_{yy} \approx 5.0196\)。于是 \(B \approx 1.0020\),\(A = e^{(2.49887 - 2.5048)} \approx 0.9940\),\(r \approx 0.9998\)。拟合方程约为 \(y = 0.9940 \cdot e^{(1.0020 \cdot x)}\),本质上就是 \(y = e^{x}\)。
常见问题
为什么 y 必须为正数? 拟合过程会用到 \(\ln(y)\),而 0 或负数的对数没有定义,因此这类数据行会被自动剔除。
频数 f 代表什么? 它决定了每个数据点对拟合结果的影响力大小,特别适合处理频数分布表——表中往往有许多观测值共享相同的 (x, y)。
如何解读 r? |r| 大于 0.7 为强相关,0.4–0.7 为中度相关,0.2–0.4 为弱相关,低于 0.2 则基本不相关。