Что считает этот калькулятор
Инструмент подбирает экспоненциальную трендовую кривую вида \(y = A \cdot e^{Bx}\) к набору данных, где каждой точке задан вес (частота). Каждая строка данных — это тройка (x, y, f), в которой f — частота, или вес, то есть сколько раз встречается данное наблюдение. На выходе вы получаете подобранные коэффициенты A и B, а также коэффициент корреляции r лежащей в основе линейной аппроксимации. Это чистая математика, которая работает одинаково в любой стране и не зависит от каких-либо региональных правил.
Как пользоваться
Вводите по одной точке в строке в формате x, y, f. Значение y должно быть больше 0, потому что модель линеаризуется через натуральный логарифм. Если третий столбец не указать, частота по умолчанию равна 1. Выберите, сколько значащих цифр выводить, и посмотрите значения A, B, r, а также готовое уравнение с подставленными коэффициентами.
Разбор формулы
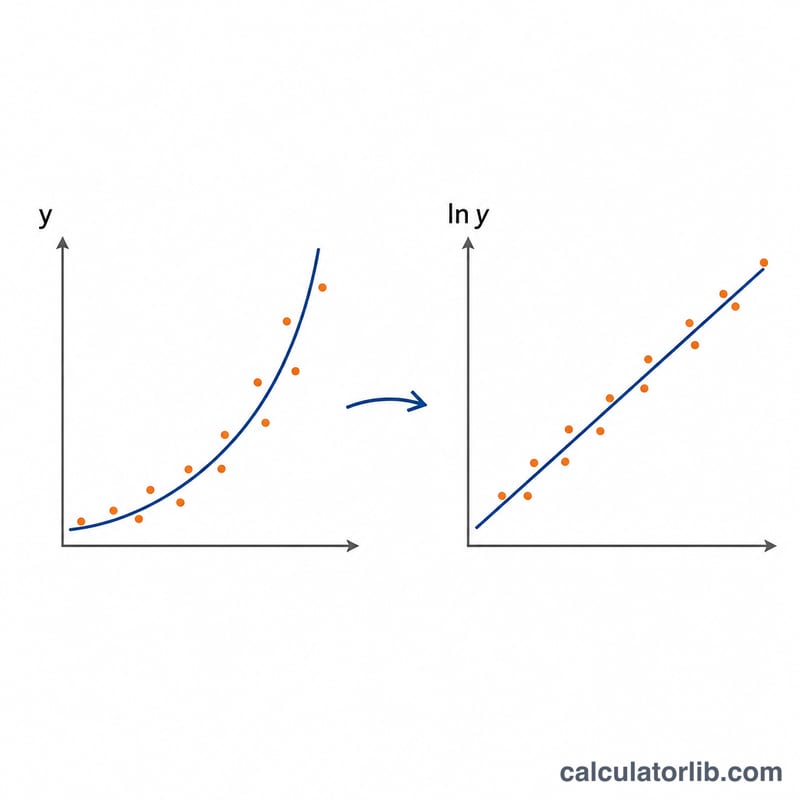
Поскольку ln y = ln A + B·x, подбор экспоненты сводится к взвешенной линейной регрессии ln y по x. Используя взвешенные суммы, где каждое слагаемое умножается на частоту f, определим \(n = \sum f\), взвешенные средние \(\bar{x}\) и \(\bar{L}\) (среднее от \(\ln y\)), а также взвешенные суммы квадратов \(S_{xx}\), \(S_{yy}\) и сумму произведений \(S_{xy}\). Тогда $$y = A \cdot e^{B x}$$ $$\text{где}\quad \left\{ \begin{aligned} B &= \frac{S_{xy}}{S_{xx}} \\ A &= e^{\,\bar{L} - B\bar{x}} \\ S_{xx} &= \textstyle\sum f x^{2} - n\bar{x}^{2} \\ S_{xy} &= \textstyle\sum f x \ln y - n\bar{x}\bar{L} \\ n &= \textstyle\sum f,\quad \bar{x}=\tfrac{\sum f x}{n},\quad \bar{L}=\tfrac{\sum f \ln y}{n} \end{aligned} \right.$$ а \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\). Значение r, близкое к \(\pm 1\), говорит о хорошем приближении.
Пример расчёта
Возьмём точки (1, 2.7), (2, 7.4), (3, 20.1), (4, 54.6), каждая с частотой 1 — они близки к кривой \(y = e^{x}\). Здесь \(\bar{x} = 2.5\), \(\bar{L} \approx 2.49887\), \(S_{xx} = 5\), \(S_{xy} \approx 5.0098\), \(S_{yy} \approx 5.0196\). Получаем \(B \approx 1.0020\), \(A = e^{\,2.49887 - 2.5048} \approx 0.9940\) и \(r \approx 0.9998\). Итоговое уравнение примерно равно $$y = 0.9940 \cdot e^{1.0020 \cdot x}$$ — по сути это \(y = e^{x}\).
Частые вопросы
Почему y должен быть положительным? В расчёте используется \(\ln(y)\), а логарифм нуля или отрицательного числа не определён, поэтому такие строки отбрасываются.
Что означает частота f? Она задаёт вес — насколько сильно точка влияет на результат подбора. Это удобно для таблиц частотных распределений, где множество наблюдений имеют одинаковые (x, y).
Как читать r? \(|r|\) выше 0.7 — сильная корреляция, 0.4–0.7 — умеренная, 0.2–0.4 — слабая, а ниже 0.2 — связи практически нет.