Что делает этот калькулятор
Инструмент строит кривую логарифмической регрессии вида \(y = A + B\cdot\ln(x)\) по таблице наблюдений, где у каждой строки указан свой вес (частота) f. Взвешивание по частоте позволяет компактно вводить сгруппированные или повторяющиеся данные: вместо того чтобы много раз перечислять одну и ту же пару (x, y), вы записываете её один раз и ставите рядом число повторений f. Это чистая статистика, и метод работает абсолютно одинаково в любой стране — никакие единицы измерения или местные правила здесь роли не играют.
Как пользоваться
Каждую группу наблюдений вводите в отдельной строке в формате x y f. Столбец с частотой необязателен: если его не указать, каждая строка считается один раз (f = 1). Все значения x должны быть строго больше нуля, поскольку берётся натуральный логарифм \(\ln(x)\). Задайте минимум две строки с разными значениями x — иначе прямую не построить. Выберите точность вывода (по умолчанию 10 значащих цифр) — этот параметр влияет только на округление выводимых чисел и никак не меняет сами вычисления.
Разбор формулы
Пусть имеется m групп (i = 1..m), тогда \(n = \sum f_i\). Взвешенные средние: $$\text{meanLnX} = \frac{\sum f_i\cdot\ln x_i}{n}$$ и $$\text{meanY} = \frac{\sum f_i\cdot y_i}{n}.$$ Взвешенные суммы квадратов: $$S_{xx} = \sum f_i(\ln x_i)^2 - n\cdot\text{meanLnX}^2,$$ $$S_{yy} = \sum f_i y_i^2 - n\cdot\text{meanY}^2$$ и $$S_{xy} = \sum f_i\cdot\ln x_i\cdot y_i - n\cdot\text{meanLnX}\cdot\text{meanY}.$$ Отсюда $$B = \frac{S_{xy}}{S_{xx}}, \quad A = \text{meanY} - B\cdot\text{meanLnX}$$ и $$r = \frac{S_{xy}}{\sqrt{S_{xx}}\cdot\sqrt{S_{yy}}}.$$
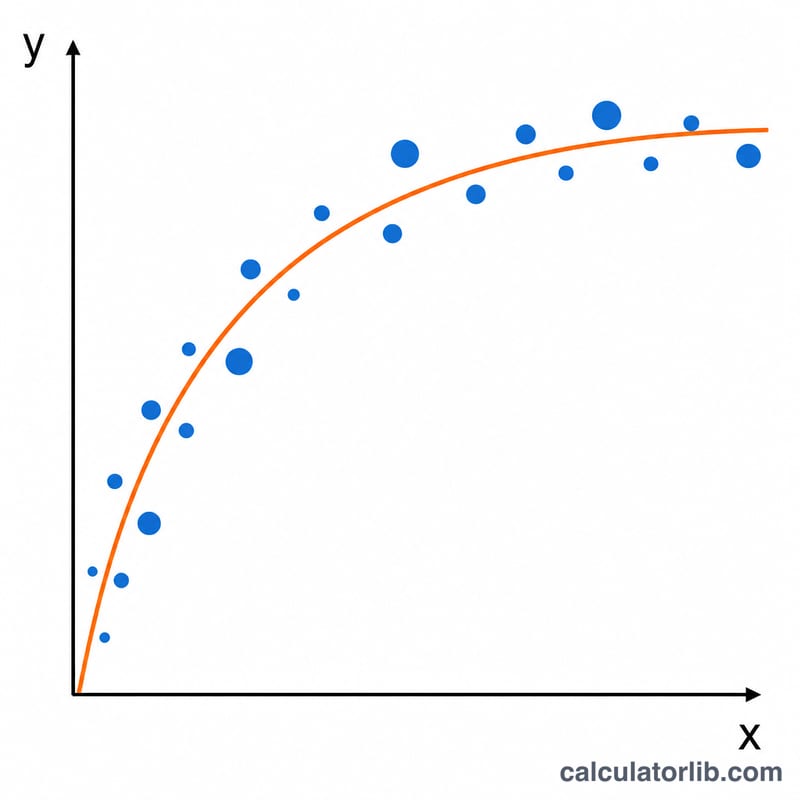
Пример с расчётом
Возьмём пять строк, у всех f = 1 — (1,2), (2,3), (3,3), (4,4), (5,4). Получаем $$\text{meanLnX} = 0{,}9574984, \quad \text{meanY} = 3{,}2,$$ $$S_{xx} = 1{,}6154888, \quad S_{yy} = 2{,}8, \quad S_{xy} = 2{,}0382328.$$ Тогда $$B = 1{,}2616933, \quad A = 1{,}9919295 \quad \text{и} \quad r = 0{,}9583567.$$ Итоговая кривая — \(y = 1{,}9919 + 1{,}2617\cdot\ln(x)\) с сильной корреляцией.
Частые вопросы
Зачем нужен столбец частоты? Он задаёт вес каждой строки. Строка с f = 5 трактуется как пять одинаковых наблюдений, поэтому влияет на результат в пять раз сильнее, чем строка с f = 1.
Как трактовать r? |r| выше 0,7 — сильная связь, 0,4–0,7 — умеренная, 0,2–0,4 — слабая, ниже 0,2 — корреляции практически нет.
Почему появляется надпись «нельзя построить регрессию»? Для построения нужны минимум два различных значения x (иначе \(S_{xx} = 0\)) и положительная суммарная частота. Кроме того, все x должны быть больше нуля, чтобы \(\ln(x)\) был определён.