Что такое логарифмическая регрессия?
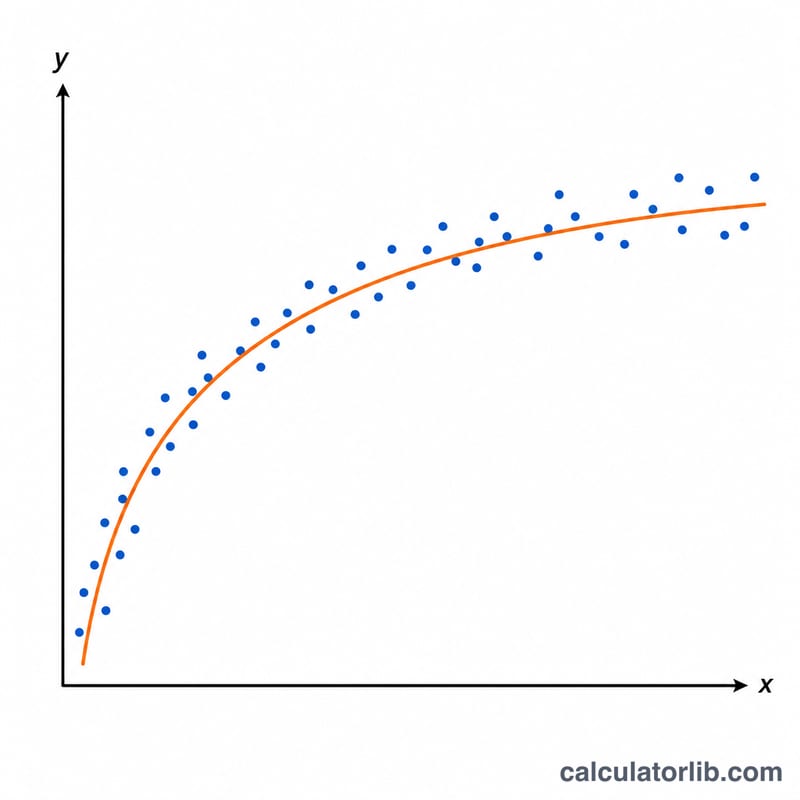
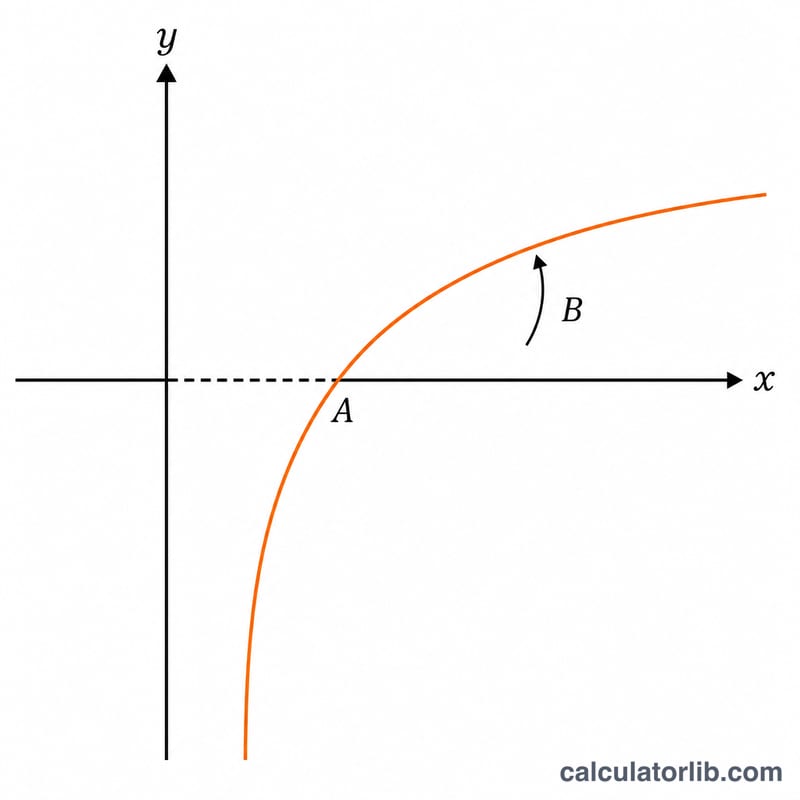
Логарифмическая регрессия подбирает кривую вида \(y = A + B\cdot\ln(x)\) к вашим данным. Она удобна, когда величина сначала растёт быстро, а затем выходит на плато: равные «множительные» шаги по x дают примерно одинаковый прирост y. Если взять натуральный логарифм каждого значения x, задача сводится к обычной линейной аппроксимации (методом наименьших квадратов) в новой переменной \(u = \ln(x)\).
Как пользоваться калькулятором
Введите данные в поле таблицы — по одной паре (x, y) на строку, разделяя числа запятой или пробелом. Все значения x должны быть строго положительными, поскольку \(\ln(x)\) не определён для нуля и отрицательных чисел; такие строки, как и пустые, просто игнорируются. Укажите, сколько значащих цифр выводить, и считайте готовые результаты: свободный член A, коэффициент B, коэффициент корреляции r и средние значения.
Разбор формулы
Обозначим \(u_i = \ln(x_i)\). Сначала находим средние значения u и y, затем суммы квадратов \(S_{xx} = \sum (u-\bar{u})^2\), \(S_{yy} = \sum (y-\bar{y})^2\) и сумму произведений отклонений \(S_{xy} = \sum (u-\bar{u})(y-\bar{y})\). Угловой коэффициент равен $$B = \frac{S_{xy}}{S_{xx}},$$ свободный член — $$A = \bar{y} - B\cdot\bar{u},$$ а корреляция — $$r = \frac{S_{xy}}{\sqrt{S_{xx}} \cdot \sqrt{S_{yy}}}.$$ Обратите внимание: показанное «среднее x» — это геометрическое среднее \(\exp(\bar{u})\), а не арифметическое, ведь аппроксимация выполняется в логарифмическом масштабе.
Пример с расчётом
Для точек (1, 2.0), (2, 4.0), (3, 5.0), (4, 5.5), (5, 6.0): \(\text{meanLnX} = 0.957498\), \(\text{meanY} = 4.5\), \(S_{xx} = 1.615493\), \(S_{yy} = 10.0\), \(S_{xy} = 4.003192\). Отсюда \(B = 2.4780\), \(A = 2.1273\) и \(r = 0.9963\) (сильная корреляция). Подобранная линия — $$y = 2.1273 + 2.4780\cdot\ln(x),$$ а геометрическое среднее $$x = \exp(0.957498) = 2.6051.$$
Частые вопросы
Почему «среднее x» не совпадает со средним арифметическим моих значений x? Регрессия строится по \(\ln(x)\), поэтому естественным центром данных по x в этой модели служит геометрическое среднее \(\exp(\text{среднего от } \ln x)\) — именно оно и выводится.
Как трактовать коэффициент корреляции r? \(|r|\) выше 0,7 говорит о сильной связи, 0,4–0,7 — об умеренной, 0,2–0,4 — о слабой, а ниже 0,2 — практически об отсутствии корреляции.
Что если все значения x одинаковы? Тогда \(S_{xx} = 0\), и угловой коэффициент не определён (деление на ноль), поэтому аппроксимацию построить нельзя: нужно как минимум два различных значения x.