로그 회귀란?
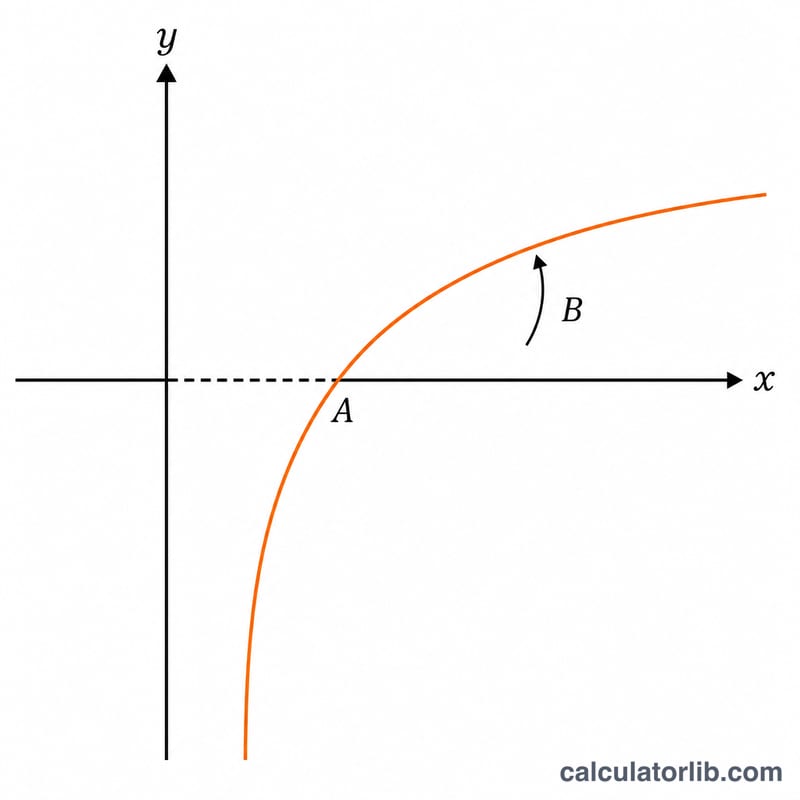
로그 회귀는 데이터에 \(y = A + B\cdot\ln(x)\) 형태의 곡선을 적합하는 방법입니다. 어떤 값이 처음에는 빠르게 증가하다가 점차 완만해질 때, 즉 x가 일정한 비율로 곱해질 때 y가 거의 일정한 폭으로 더해지는 관계에 유용합니다. 모든 x 값에 자연로그를 취하면, 변환된 변수 \(u = \ln(x)\)에 대한 일반적인 직선(최소제곱) 적합 문제로 바뀝니다.
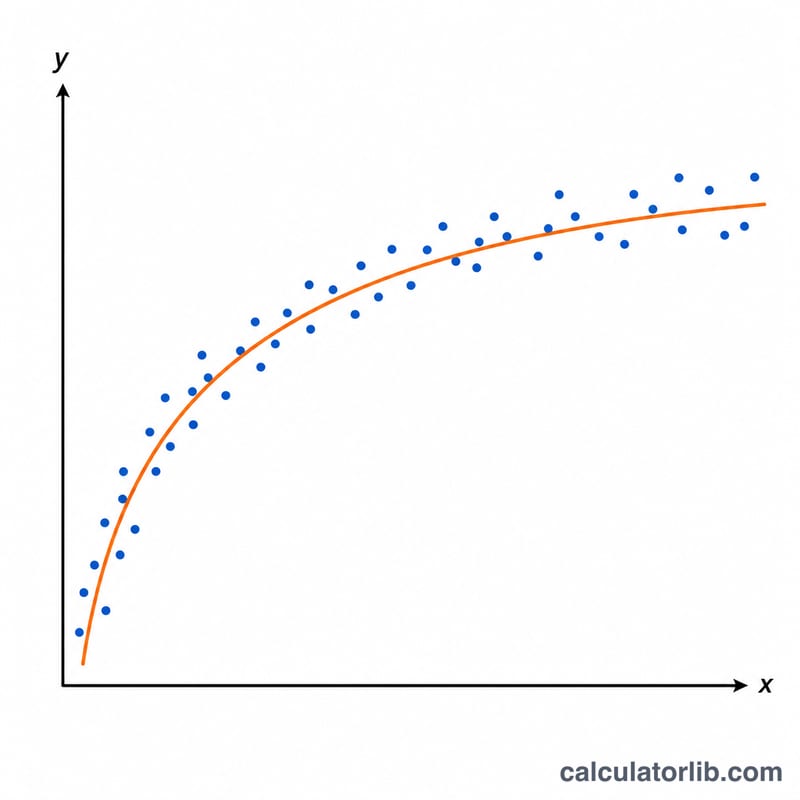
계산기 사용 방법
표 입력란에 (x, y) 쌍을 한 줄에 하나씩, 쉼표나 공백으로 구분해 입력하세요. \(\ln(x)\)는 0이나 음수에서 정의되지 않으므로 모든 x 값은 반드시 양수여야 하며, 그렇지 않은 행과 빈 줄은 무시됩니다. 표시할 유효숫자 자릿수를 선택한 뒤, 적합된 절편 A, 계수 B, 상관계수 r, 그리고 평균값을 확인하면 됩니다.
공식 자세히 보기
\(u_i = \ln(x_i)\)로 둡니다. 먼저 u와 y의 평균을 구한 다음, 제곱합 \(S_{xx} = \sum (u-\bar{u})^2\), \(S_{yy} = \sum (y-\bar{y})^2\)와 교차곱 \(S_{xy} = \sum (u-\bar{u})(y-\bar{y})\)를 계산합니다.
$$y = A + B\,\ln(x) \quad\text{fit to}\;\text{Data }(x_i,\,y_i)$$기울기는 다음과 같습니다.
$$\begin{aligned} B &= \frac{\sum (u_i - \bar{u})(y_i - \bar{y})}{\sum (u_i - \bar{u})^2}, \quad u_i = \ln(x_i) \\ A &= \bar{y} - B\,\bar{u} \\ r &= \frac{\sum (u_i - \bar{u})(y_i - \bar{y})}{\sqrt{\sum (u_i - \bar{u})^2 \,\sum (y_i - \bar{y})^2}} \end{aligned}$$즉 기울기는 \(B = S_{xy} / S_{xx}\), 절편은 \(A = \bar{y} - B\cdot\bar{u}\), 상관계수는 \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\)입니다. 여기서 표시되는 "x 평균"은 산술평균이 아니라 기하평균 \(\exp(\bar{u})\)라는 점에 유의하세요. 적합이 로그 공간에서 이루어지기 때문입니다.
계산 예시
점 (1, 2.0), (2, 4.0), (3, 5.0), (4, 5.5), (5, 6.0)에 대해: \(\text{meanLnX} = 0.957498\), \(\text{meanY} = 4.5\), \(S_{xx} = 1.615493\), \(S_{yy} = 10.0\), \(S_{xy} = 4.003192\)입니다. 따라서 \(B = 2.4780\), \(A = 2.1273\), \(r = 0.9963\)(강한 상관관계)이 됩니다. 적합된 선은 다음과 같습니다.
$$y = 2.1273 + 2.4780\cdot\ln(x)$$이며, 기하평균 \(x = \exp(0.957498) = 2.6051\)입니다.
자주 묻는 질문
"x 평균"이 왜 제 x 값들의 평균과 다른가요? 회귀가 \(\ln(x)\)를 기준으로 계산되기 때문에, 이 모델에서 x 데이터의 자연스러운 중심은 기하평균 \(\exp(\overline{\ln x})\)이며, 바로 이 값이 표시됩니다.
상관계수 r은 어떻게 해석하나요? \(|r|\)이 0.7보다 크면 강한 관계, 0.4~0.7이면 보통, 0.2~0.4이면 약함, 0.2 미만이면 사실상 상관관계가 없음을 의미합니다.
모든 x 값이 같으면 어떻게 되나요? 이 경우 \(S_{xx} = 0\)이 되어 기울기를 정의할 수 없으므로(0으로 나누기), 적합을 계산할 수 없습니다. 적어도 서로 다른 x 값이 두 개는 있어야 합니다.