Qué hace esta calculadora
Esta herramienta ajusta una línea de tendencia ab-exponencial de la forma \(y = A\cdot B^{x}\) a una tabla de distribución de frecuencias. Cada fila contiene un valor x, un valor y y una frecuencia f (el número de veces, o el peso, con que aparece el par (x, y)). Es un método puramente estadístico que funciona igual en cualquier lugar: sin unidades ni normativa de ningún país.
Cómo usarla
Introduce un punto de datos por línea con el formato x, y, f. El valor de y debe ser estrictamente positivo, ya que el método aplica el logaritmo natural de y. Si deseas un ajuste corriente sin ponderar, asigna a todas las frecuencias el valor 1 (también puedes omitir el tercer número, en cuyo caso se asume f = 1). Elige el número de cifras significativas con que quieres ver los coeficientes y consulta A, B y el coeficiente de correlación r.
La fórmula explicada
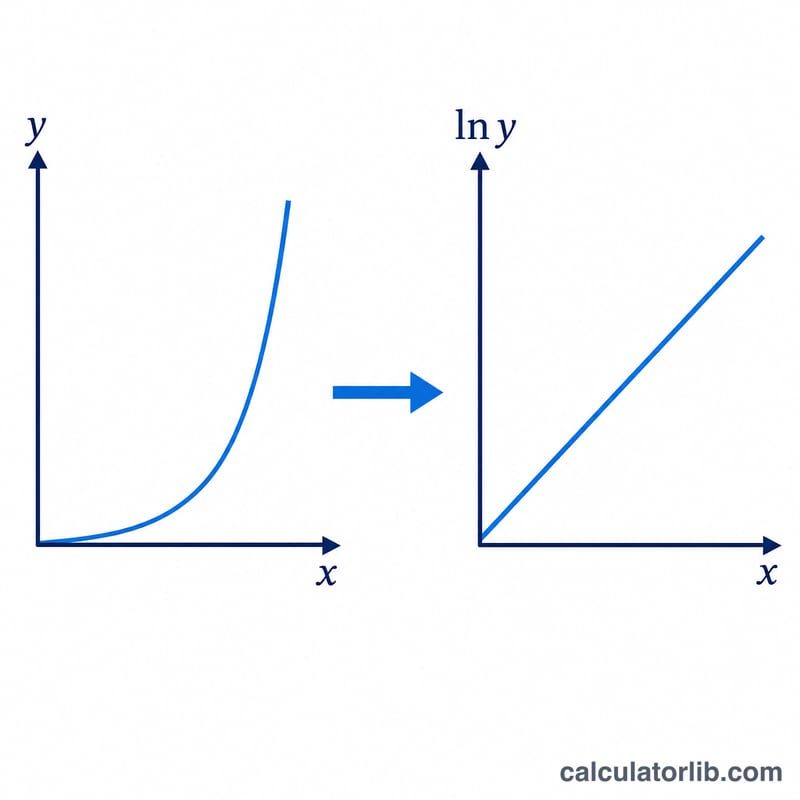
El truco consiste en linealizar el modelo: al tomar logaritmos en \(y = A\cdot B^{x}\) obtenemos \(\ln y = \ln A + x\cdot \ln B\), una recta en el espacio (x, ln y). Sobre ella aplicamos una regresión por mínimos cuadrados ponderada por la frecuencia de ln y respecto a x. Con \(n = \sum f\), las medias ponderadas \(\bar{x}\) y \(\overline{\ln y}\), y las sumas ponderadas \(S_{xx}\), \(S_{yy}\), \(S_{xy}\), la pendiente es \(S_{xy}/S_{xx}\) y la ordenada en el origen es \(\overline{\ln y} - \bar{x}\cdot\text{pendiente}\). Al aplicar la exponencial se obtiene \(B = e^{\text{pendiente}}\) y \(A = e^{\text{ordenada}}\).
$$y = A \cdot B^{x}, \qquad B = e^{\,S_{xy}/S_{xx}}, \quad A = e^{\,\overline{\ln y} - \bar{x}\,(S_{xy}/S_{xx})}$$El coeficiente de correlación \(r = S_{xy} / (\sqrt{S_{xx}} \cdot \sqrt{S_{yy}})\) indica lo bien que el modelo log-lineal se ajusta a los datos.
Ejemplo resuelto
Para los datos que duplican perfectamente (1, 2), (2, 4), (3, 8), (4, 16), todos con f = 1: \(n = 4\), \(\bar{x} = 2{,}5\), \(\overline{\ln y} = 1{,}732868\), \(S_{xx} = 5\), \(S_{xy} = 3{,}465735\), \(S_{yy} = 2{,}402224\). Entonces $$B = e^{3{,}465735/5} = e^{0{,}693147} = 2, \quad A = e^{0} = 1, \quad r = 1.$$ Así pues, la curva ajustada es \(y = 1\cdot 2^{x}\), exactamente como cabía esperar.
Preguntas frecuentes
¿Para qué sirve la columna de frecuencia? Pondera cada punto de datos según el número de veces que aparece, de modo que una fila con f = 5 equivale a cinco filas idénticas. Usa f = 1 en todas las filas para una regresión normal.
¿Cómo se interpreta r? |r| > 0,7 indica una correlación fuerte; entre 0,4 y 0,7, moderada; entre 0,2 y 0,4, débil; y por debajo de 0,2, prácticamente nula. La r se calcula en el espacio (x, ln y).
¿Por qué tiene que ser y positivo? El modelo toma el logaritmo natural de y, y ln y no está definido para y ≤ 0, por lo que las filas con valores no positivos se descartan.