
什麼是 F1 分數?
F1 分數是一個將精確率(Precision)與召回率(Recall)整合成單一數值的指標,因此廣泛用於評估機器學習、資訊檢索與統計領域中的分類模型。它是精確率與召回率的調和平均數,所以會偏好兩者兼顧的模型,而不是只在單一面向表現突出的模型。
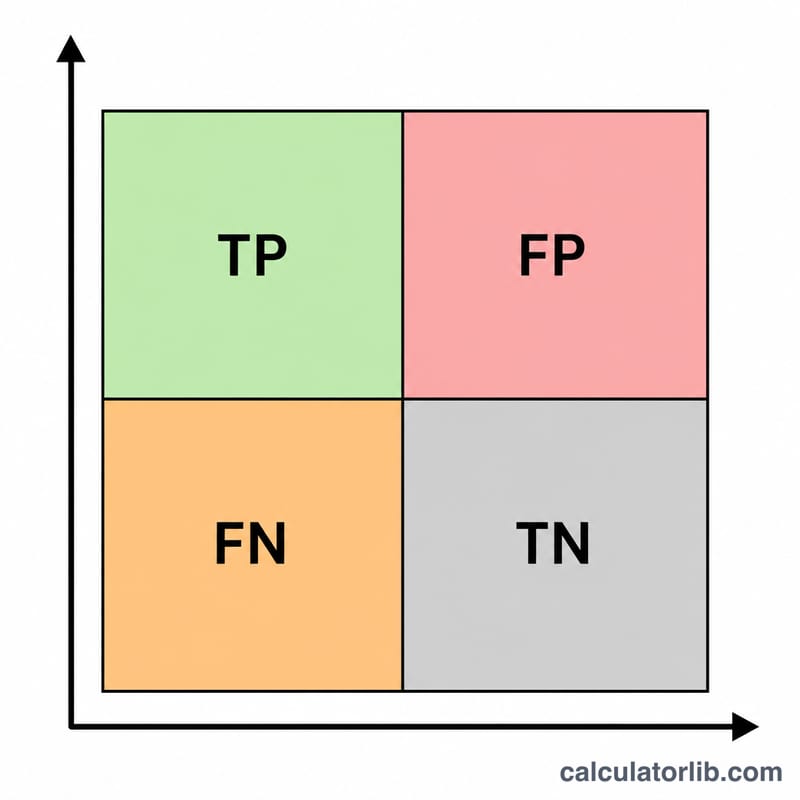
如何使用本計算器
請從你的混淆矩陣(Confusion Matrix)中輸入三個數值:真陽性(TP,正確預測為正類的數量)、偽陽性(FP,本為負類卻被誤判為正類的數量),以及偽陰性(FN,本為正類卻被漏掉的數量)。計算器會立即回傳精確率、召回率與最終的 F1 分數。
公式詳解
精確率 = \(\frac{\text{TP}}{\text{TP} + \text{FP}}\),衡量在所有被預測為正類的樣本中,有多少是真正正確的。召回率 = \(\frac{\text{TP}}{\text{TP} + \text{FN}}\),衡量在所有實際為正類的樣本中,有多少被成功找出。F1 分數則為
$$F_1 = \frac{2 \cdot (\text{精確率} \cdot \text{召回率})}{\text{精確率} + \text{召回率}}$$由於它是調和平均數,只要精確率或召回率任一方偏低,F1 分數就會被大幅拉低。
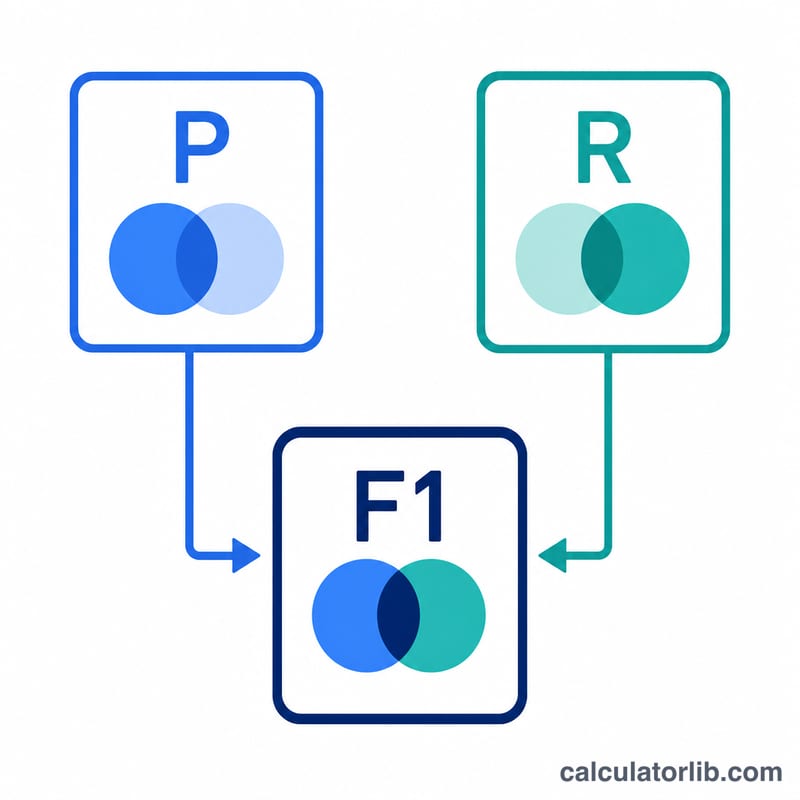
實例演算
假設 \(\text{TP} = 70\)、\(\text{FP} = 30\)、\(\text{FN} = 10\)。精確率 = \(\frac{70}{100} = 0.70\);召回率 = \(\frac{70}{80} = 0.875\)。
$$F_1 = \frac{2 \cdot (0.70 \cdot 0.875)}{0.70 + 0.875} = \frac{2 \cdot 0.6125}{1.575} \approx 0.7778$$約等於 77.78%。
常見問題
什麼時候該用 F1 而不是準確率(Accuracy)?當類別分布不平衡時,F1 更為適用;因為當某一類別佔絕大多數時,準確率可能會虛高而具誤導性。
多少的 F1 分數才算好?F1 的範圍是 0 到 1,越接近 1 越好。「好」的標準會因任務而異,但一般而言,數值高於 0.8 通常被視為相當不錯的表現。
為什麼要用調和平均數?相較於簡單的算術平均,調和平均數會對精確率與召回率之間的極端落差施加更重的懲罰,確保兩者都必須維持在合理的水準。