Qu'est-ce que l'asymétrie ?
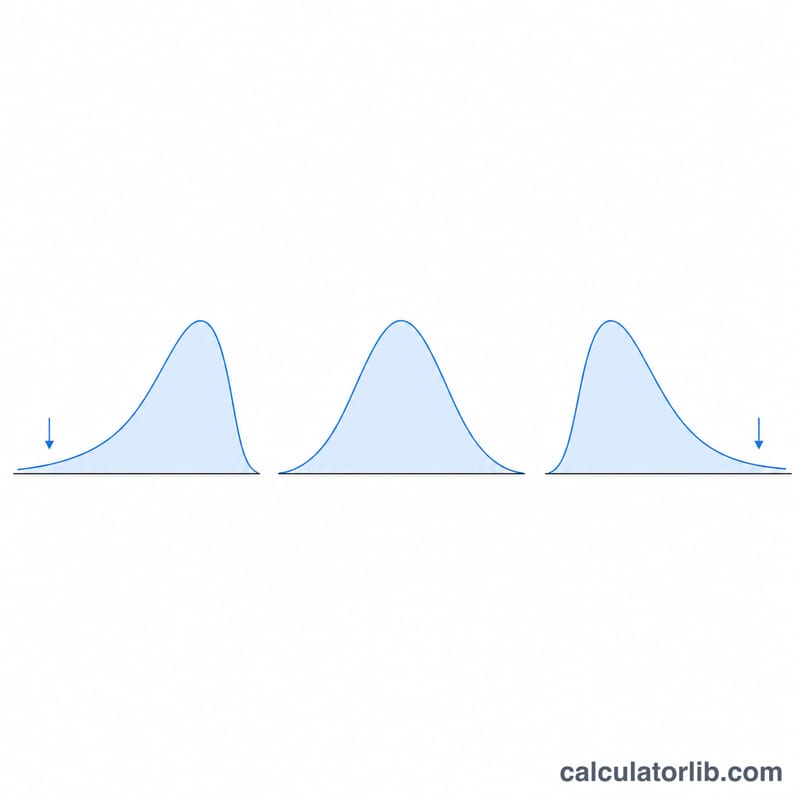
L'asymétrie (ou skewness) mesure le degré de dissymétrie d'une distribution de probabilité ou d'un jeu de données autour de sa moyenne. Une asymétrie nulle correspond à une distribution symétrique. Une asymétrie positive traduit une queue plus longue vers la droite (les grandes valeurs tirent la moyenne vers le haut), tandis qu'une asymétrie négative indique une queue plus longue vers la gauche. Ce calculateur fournit soit l'asymétrie de population, soit l'asymétrie d'échantillon corrigée du biais, accompagnées de la moyenne et de l'écart-type.
Comment l'utiliser
Saisissez vos valeurs séparées par des virgules ou des espaces, puis choisissez une méthode. Optez pour Population lorsque vos données représentent l'ensemble du groupe étudié, et pour Échantillon (l'estimateur de Fisher-Pearson ajusté, utilisé par la fonction SKEW d'Excel et par de nombreux logiciels de statistiques) lorsque vous disposez d'un échantillon issu d'une population plus large.
La formule expliquée
L'asymétrie de population est la moyenne des écarts standardisés au cube :
$$g_1 = \frac{1}{n} \sum_{i=1}^{n} \left( \frac{x_i - \bar{x}}{\sigma} \right)^{3}$$où \(\sigma\) est calculé en divisant par \(n\). La version échantillon applique un facteur de correction :
$$G_1 = \frac{n}{(n-1)(n-2)} \sum_{i=1}^{n} \left( \frac{x_i - \bar{x}}{s} \right)^{3}$$où \(s\) est calculé en divisant par \(n-1\). Cette correction supprime le biais à la baisse présent dans les petits échantillons.
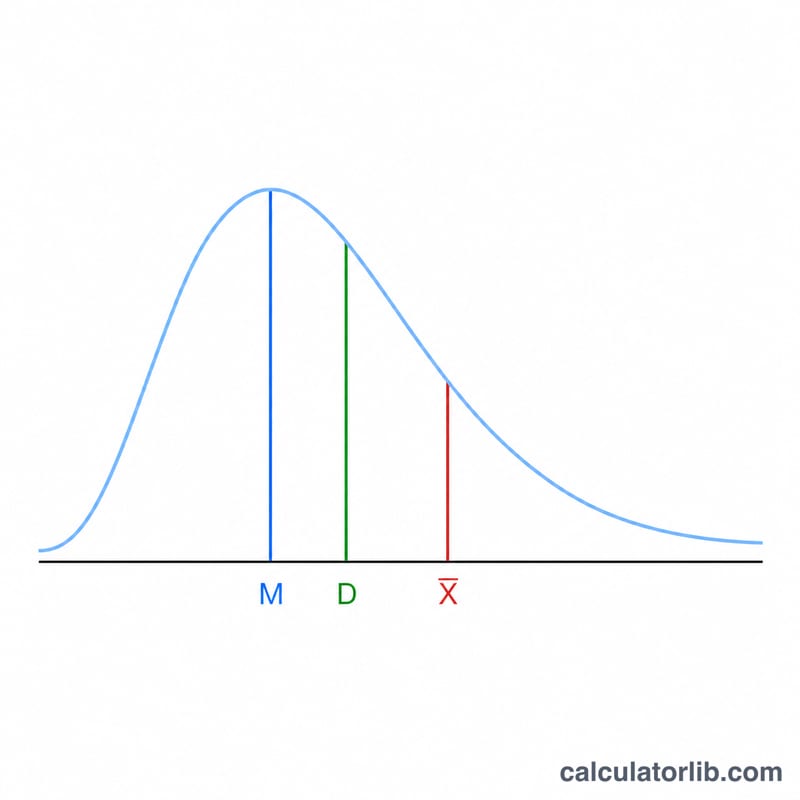
Exemple détaillé
Pour les données \(2, 4, 6, 8, 20\) : la moyenne vaut \(8\).
$$\sum (x_i-\bar{x})^3 = (-6)^3+(-4)^3+(-2)^3+(0)^3+(12)^3 = -216-64-8+0+1728 = 1440$$Pour la population, \(\sigma = \sqrt{160/5} = 6{,}3246\), donc
$$g_1 = \frac{1440/5}{6{,}3246^3} = \frac{288}{252{,}98} \approx \mathbf{1{,}1384}$$Pour la méthode échantillon, \(s = \sqrt{160/4} = 7{,}0711\), et
$$G_1 = \frac{5}{4\cdot 3}\cdot\frac{1440}{353{,}55} = 0{,}4167\cdot 4{,}0729 \approx \mathbf{1{,}6971}$$FAQ
Pourquoi les deux méthodes donnent-elles des résultats différents ? Elles s'appuient sur des écarts-types différents et la méthode échantillon ajoute un facteur de correction du biais : les valeurs diffèrent donc pour les petits jeux de données.
Que signifie une valeur proche de 0 ? La distribution est à peu près symétrique. Au-delà de \(\pm 1\), on considère généralement que l'asymétrie est marquée.
Laquelle faut-il indiquer ? Utilisez l'estimateur d'échantillon lorsque vous généralisez à partir d'un échantillon ; utilisez l'asymétrie de population lorsque vous disposez de l'ensemble complet des données.