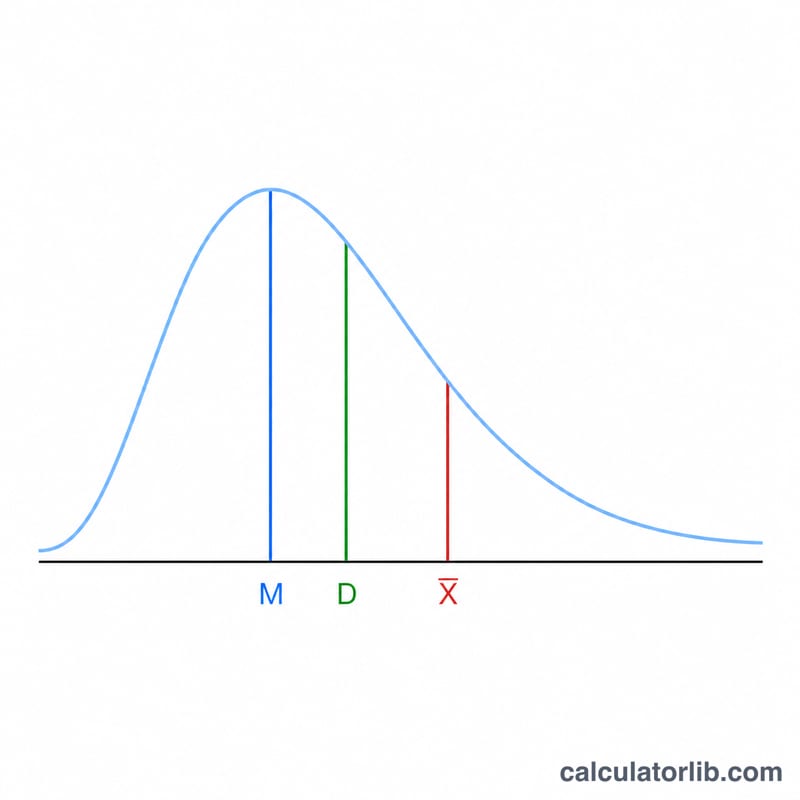
स्क्यूनेस (विषमता) क्या है?
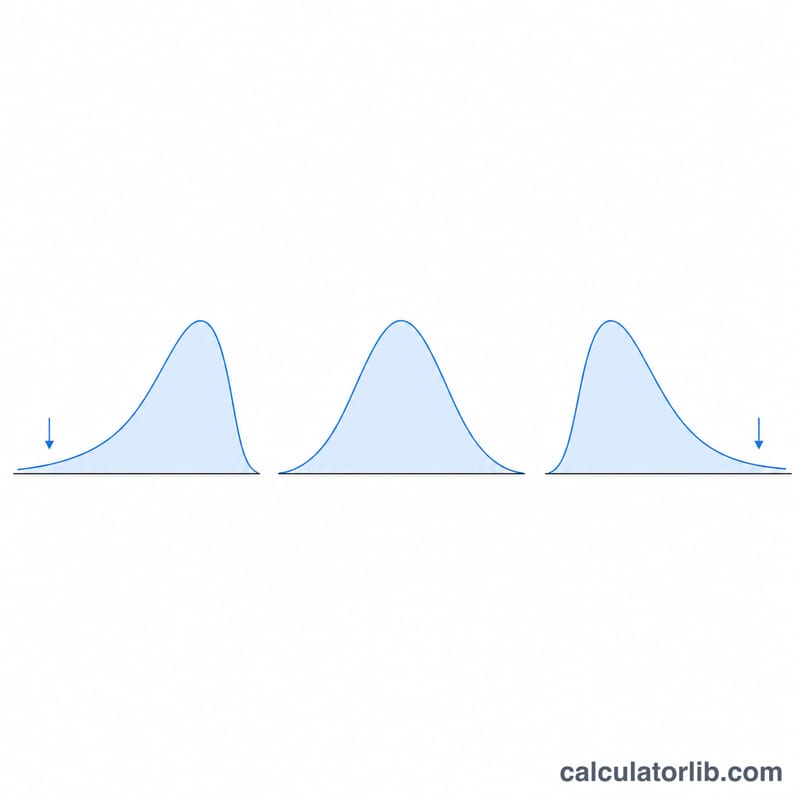
स्क्यूनेस किसी प्रायिकता वितरण या डेटा सेट की उसके माध्य के इर्द-गिर्द असमानता (asymmetry) को मापती है। स्क्यूनेस का मान शून्य होने का मतलब है कि वितरण सममित (symmetric) है। धनात्मक स्क्यूनेस यानी दाईं ओर लंबी पूँछ (बड़े मान माध्य को ऊपर खींच लेते हैं); ऋणात्मक स्क्यूनेस यानी बाईं ओर लंबी पूँछ। यह कैलकुलेटर आपको या तो पॉपुलेशन स्क्यूनेस देता है या बायस-सुधारित सैंपल स्क्यूनेस, साथ ही माध्य और मानक विचलन भी बताता है।
इसका उपयोग कैसे करें
अपने अंकों को कॉमा या स्पेस से अलग करके दर्ज करें और फिर एक विधि चुनें। जब आपका डेटा पूरे समूह का प्रतिनिधित्व करता हो तब Population चुनें, और जब आपके पास किसी बड़ी आबादी से लिया गया नमूना हो तब Sample चुनें (यह वही एडजस्टेड फिशर-पियर्सन एस्टीमेटर है जिसका उपयोग Excel का SKEW फ़ंक्शन और कई स्टैटिस्टिक्स सॉफ़्टवेयर करते हैं)।
फ़ॉर्मूला समझें
पॉपुलेशन स्क्यूनेस मानकीकृत विचलनों के घन (cube) का औसत है:
$$g_1 = \frac{1}{n} \sum_{i=1}^{n} \left( \frac{x_i - \bar{x}}{\sigma} \right)^{3}$$जहाँ \(\sigma\) में \(n\) से भाग दिया जाता है। सैंपल वाली विधि में एक सुधार कारक (correction factor) लगाया जाता है:
$$G_1 = \frac{n}{(n-1)(n-2)} \sum_{i=1}^{n} \left( \frac{x_i - \bar{x}}{s} \right)^{3}$$जहाँ \(s\) में \(n-1\) से भाग दिया जाता है। यह सुधार छोटे नमूनों में मौजूद नीचे की ओर के बायस को हटा देता है।
हल किया हुआ उदाहरण
डेटा 2, 4, 6, 8, 20 के लिए: माध्य 8 है। \(\sum(x_i-\bar{x})^3 = (-6)^3+(-4)^3+(-2)^3+(0)^3+(12)^3 = -216-64-8+0+1728 = 1440\)। पॉपुलेशन \(\sigma = \sqrt{160/5} = 6.3246\), इसलिए \(g_1 = (1440/5)/6.3246^3 = 288/252.98 \approx\) 1.1384। सैंपल विधि में, \(s = \sqrt{160/4} = 7.0711\), और \(G_1 = (5/(4\cdot 3))\cdot(1440/353.55) = 0.4167\cdot 4.0729 \approx\) 1.6971।
अक्सर पूछे जाने वाले सवाल
दोनों विधियाँ अलग-अलग संख्याएँ क्यों देती हैं? ये अलग-अलग मानक विचलन इस्तेमाल करती हैं और सैंपल विधि एक बायस-सुधार कारक जोड़ती है, इसलिए छोटे डेटा सेट में परिमाण अलग आते हैं।
0 के आसपास का मान क्या दर्शाता है? वितरण लगभग सममित है। ±1 से परे के मान आम तौर पर अत्यधिक स्क्यूड माने जाते हैं।
मुझे कौन-सा मान रिपोर्ट करना चाहिए? जब आप किसी नमूने से निष्कर्ष निकाल रहे हों तो सैंपल एस्टीमेटर का उपयोग करें; जब आपके पास पूरा डेटा सेट हो तो पॉपुलेशन स्क्यूनेस का उपयोग करें।