Bu hesaplama aracı ne işe yarar?
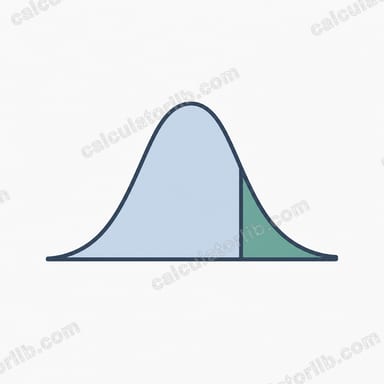
Bu araç, normal dağılıma sahip bir değişken için sağ kuyruk olasılığı olan \(P(X > x)\) değerini hesaplar. Bir x değeri, anakütle ortalaması μ ve standart sapma σ verildiğinde, rastgele seçilen bir gözlemin x'ten büyük olma şansını size söyler. Ayrıca standartlaştırılmış z-skorunu ve tamamlayıcı sol kuyruk olasılığı \(P(X \le x)\) değerini de gösterir. Bu, evrensel bir istatistik aracıdır ve her alanda kullanılabilir: kalite kontrol, sınav puanları, finans ve laboratuvar ölçümleri.
Nasıl kullanılır?
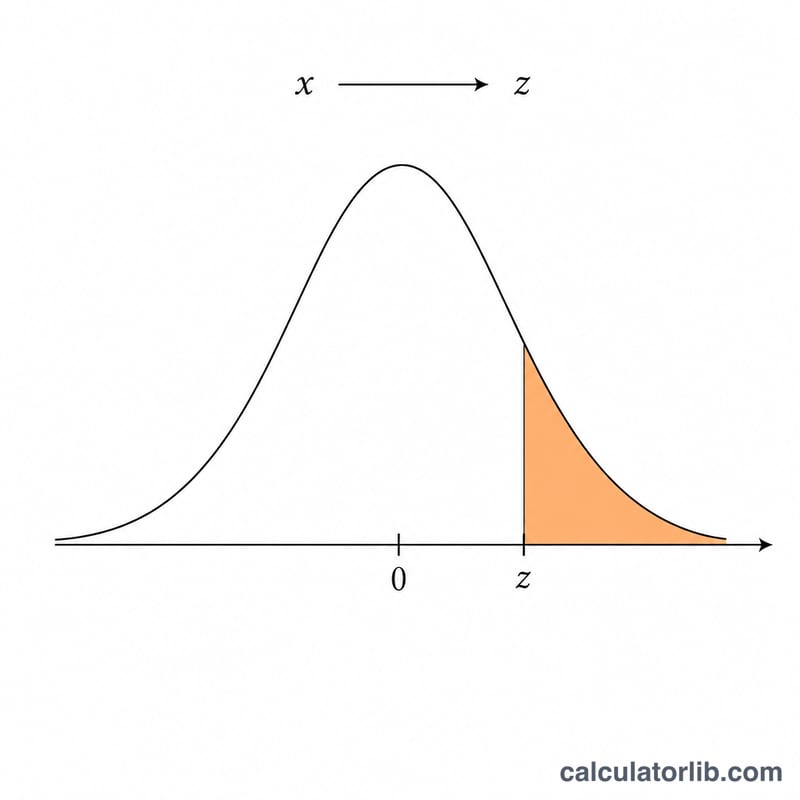
İlgilendiğiniz değeri (x), dağılımın ortalamasını (μ) ve standart sapmayı (σ; pozitif olmalıdır) girin. Hesaplayıcı, girdiğiniz değeri bir z-skoruna dönüştürür ve standart normal birikimli dağılım fonksiyonu Φ üzerinden her iki kuyruğu da değerlendirir. X'in x'i aşma olasılığını hem ondalık sayı hem de yüzde olarak görebilirsiniz.
Formülün açıklaması
Önce x değerini bir z-skoruna çevirin: \(z = (x - \mu) / \sigma\). Φ(z) fonksiyonu, standart normal eğrinin z'nin solunda kalan alanını, yani \(P(X \le x)\) değerini verir. Toplam alan 1'e eşit olduğundan, sağ kuyruk basitçe
$$P(X > x) = 1 - \Phi\!\left( \frac{\text{Value }(x) - \text{Mean }(\mu)}{\text{Std Dev }(\sigma)} \right)$$olur. Bu hesaplayıcı, Φ değerini yüksek doğruluklu bir hata fonksiyonu yaklaşımıyla (Abramowitz & Stegun 7.1.26) hesaplar; bu yaklaşım yaklaşık 7 ondalık basamağa kadar doğrudur.
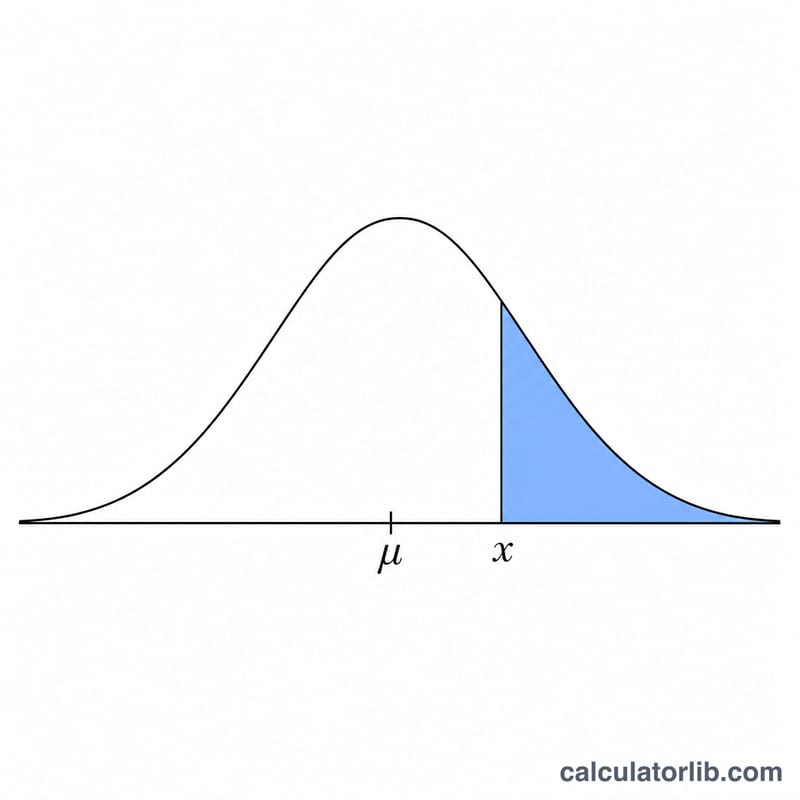
Çözümlü örnek
Diyelim ki yetişkin boyları μ = 170 cm ve σ = 10 cm ile normal dağılıyor ve \(P(\text{boy} > 185)\) değerini merak ediyorsunuz. Bu durumda
$$z = \frac{185 - 170}{10} = 1{,}5$$olur. Standart normal tablodan \(\Phi(1{,}5) \approx 0{,}93319\) olduğu görülür; dolayısıyla
$$P(X > 185) = 1 - 0{,}93319 \approx 0{,}06681$$yani yaklaşık %6,68 olur.
Sıkça sorulan sorular
Bunun yerine \(P(X < x)\) istersem ne olur? Bu, sol kuyruktur ve sonuç tablosunda \(P(X \le x) = \Phi(z)\) olarak gösterilir. Sürekli bir dağılımda \(P(X < x)\), \(P(X \le x)\) değerine eşittir.
σ neden pozitif olmalı? Standart sapma yayılımı ölçer ve sıfırdan büyük olmalıdır; sıfır veya negatif bir değerin geçerli bir normal dağılımı yoktur.
Sonuç ne kadar doğru? Φ yaklaşımı yaklaşık yedi ondalık basamağa kadar doğrudur; bu da tipik istatistiksel çalışmalar için fazlasıyla yeterlidir.