Что делает этот калькулятор
Этот инструмент вычисляет правостороннюю вероятность \(P(X > x)\) для случайной величины с нормальным распределением. По заданному значению x, среднему значению генеральной совокупности μ и стандартному отклонению σ он покажет, насколько вероятно, что случайно взятое наблюдение окажется больше x. Дополнительно калькулятор выводит стандартизованную z-оценку и дополняющую левостороннюю вероятность \(P(X \le x)\). Это универсальный статистический инструмент, который применим где угодно: в контроле качества, при анализе результатов тестов, в финансах и при обработке лабораторных измерений.
Как пользоваться
Введите интересующее значение (x), среднее распределения (μ) и стандартное отклонение (σ — оно должно быть положительным). Калькулятор переведёт ваше значение в z-оценку и вычислит функцию распределения стандартного нормального закона Φ, чтобы найти обе «хвостовые» вероятности. В результате вы увидите вероятность того, что X превышает x — как в виде десятичной дроби, так и в процентах.
Разбор формулы
Сначала переводим x в z-оценку: \(z = (x - \mu) / \sigma\). Функция \(\Phi(z)\) даёт площадь под кривой стандартного нормального распределения слева от z, то есть \(P(X \le x)\). Поскольку суммарная площадь равна 1, правый хвост находится просто:
$$P(X > x) = 1 - \Phi\!\left( \frac{\text{Value }(x) - \text{Mean }(\mu)}{\text{Std Dev }(\sigma)} \right)$$Калькулятор вычисляет Φ через высокоточную аппроксимацию функции ошибок (Абрамовиц и Стиган, формула 7.1.26), точность которой составляет около 7 знаков после запятой.
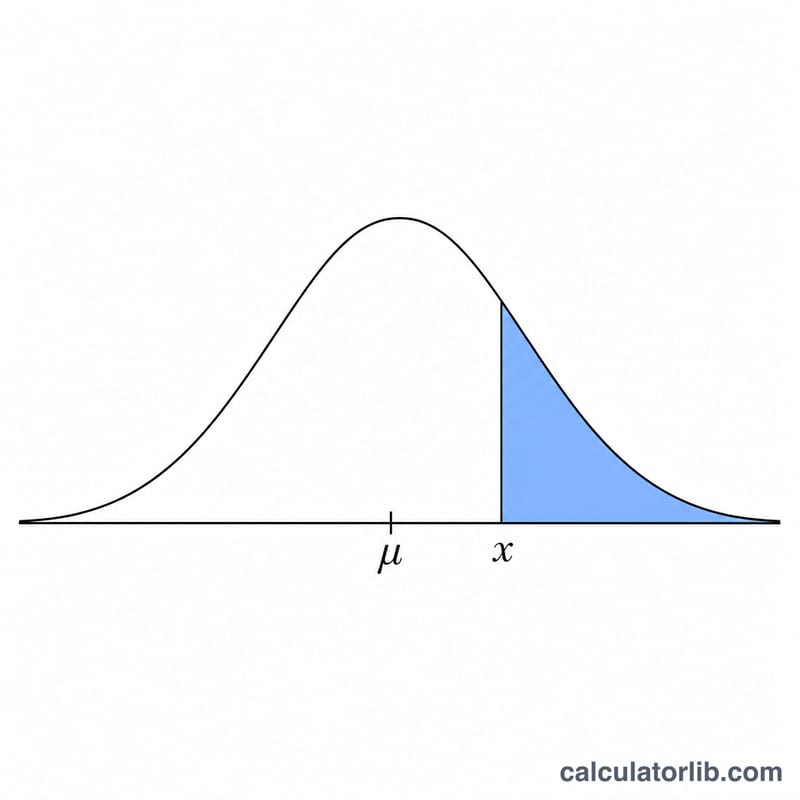
Пример расчёта
Допустим, рост взрослых людей распределён нормально со средним \(\mu = 170\) см и стандартным отклонением \(\sigma = 10\) см, и нужно найти \(P(\text{рост} > 185)\). Тогда
$$z = \frac{185 - 170}{10} = 1{,}5$$По таблице стандартного нормального распределения \(\Phi(1{,}5) \approx 0{,}93319\), поэтому
$$P(X > 185) = 1 - 0{,}93319 \approx 0{,}06681$$то есть примерно 6,68%.
Частые вопросы
А если мне нужна \(P(X < x)\)? Это левый хвост, он показан в таблице результатов как \(P(X \le x) = \Phi(z)\). Для непрерывного распределения \(P(X < x)\) совпадает с \(P(X \le x)\).
Почему σ должна быть положительной? Стандартное отклонение характеризует разброс значений и должно быть строго больше нуля; при значении ноль или меньше корректного нормального распределения не существует.
Насколько точен результат? Аппроксимация Φ точна примерно до семи знаков после запятой, чего с избытком хватает для большинства статистических задач.