Что делает этот инструмент
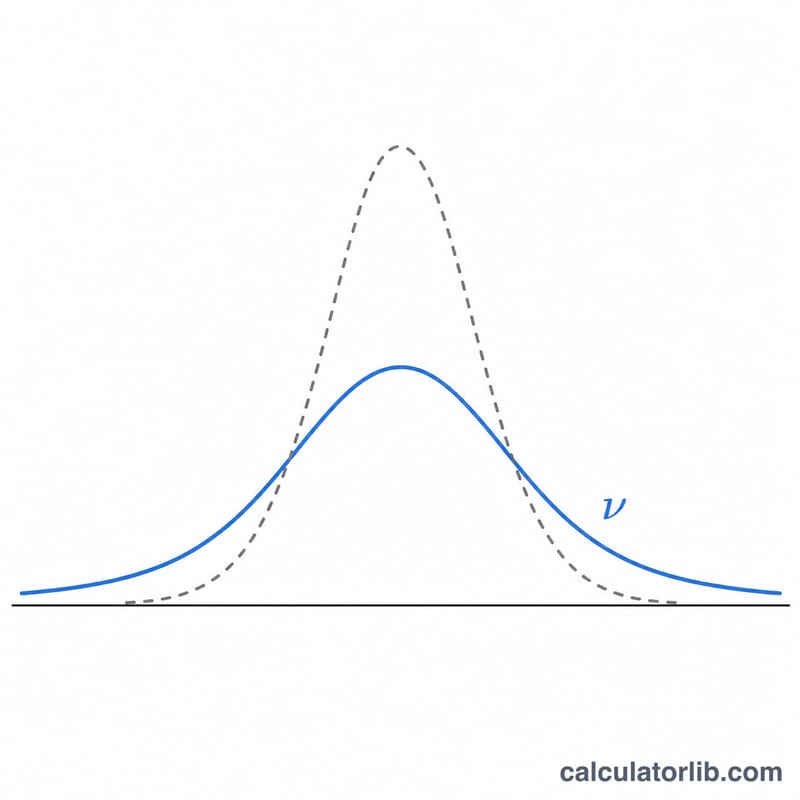
Этот генератор выдаёт список псевдослучайных чисел, взятых из t-распределения Стьюдента с заданным числом степеней свободы (\(v\)). Распределение Стьюдента — это симметричная колоколообразная кривая с более «тяжёлыми хвостами», чем у стандартного нормального распределения. Оно естественным образом появляется при оценке среднего нормально распределённой совокупности по небольшой выборке с неизвестной дисперсией и лежит в основе t-критерия и доверительных интервалов. По мере роста \(v\) t-распределение сходится к стандартному нормальному \(\mathcal{N}(0,1)\). Это чисто математический инструмент без каких-либо региональных привязок.
Как пользоваться
Укажите число степеней свободы \(v\) (любое вещественное число больше 0; по умолчанию 2) и нужное количество случайных значений (целое число от 1 до 1000; по умолчанию 10). Нажмите «Рассчитать» — и вы получите свежий список значений, распределённых по Стьюденту. Поскольку базовые равномерные числа случайны, при каждом запуске вы получаете разные значения, но все они подчиняются одному и тому же целевому распределению.
Разбор формулы
Плотность задаётся выражением \(f(x,v) = (1 + x^{2}/v)^{-(v+1)/2}\), делённым на \(\sqrt{v}\), умноженное на \(B(1/2, v/2)\), где \(B\) — бета-функция. Для эффективной выборки применяется классическое представление: берём \(Z\) из стандартного нормального распределения и \(C\) из распределения хи-квадрат с \(v\) степенями свободы, тогда величина $$ T = Z \cdot \sqrt{\dfrac{v}{C}} $$ в точности следует распределению Стьюдента. Внутри \(Z\) получается с помощью преобразования Бокса — Мюллера, а \(C\) — из генератора \(\text{Gamma}(v/2, 2)\) (метод Марсальи — Цанга), что справедливо для любого вещественного \(v > 0\).
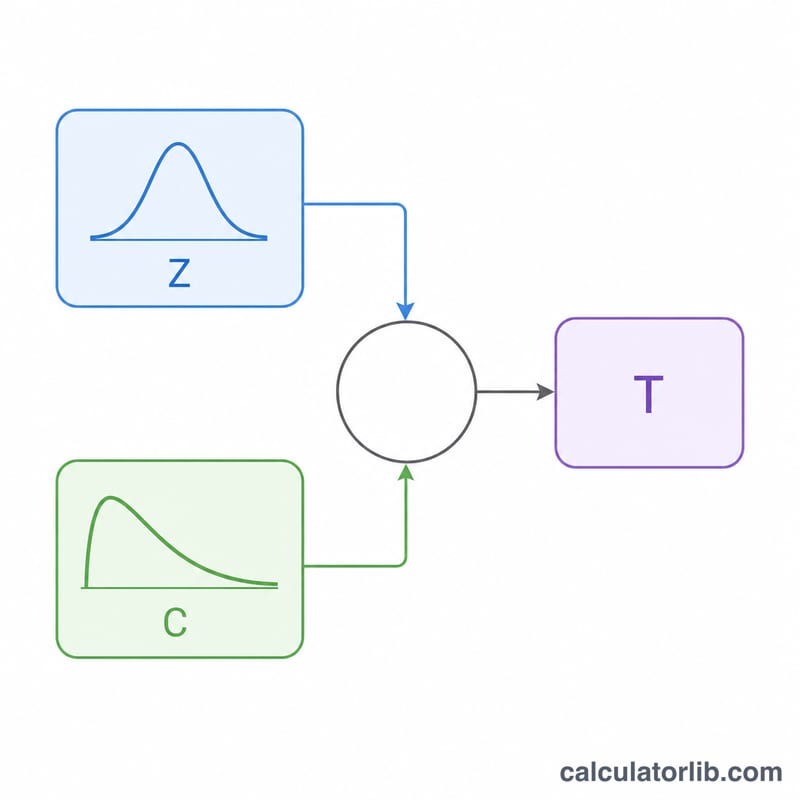
Разбор примера
Пусть \(v = 2\) и один запуск даёт \(Z = 0{,}50\) и значение хи-квадрат \(C = 1{,}20\). Тогда $$ T = 0{,}50 \cdot \sqrt{\dfrac{2}{1{,}20}} = 0{,}50 \cdot 1{,}29099 = 0{,}6455 $$ Вторая пара \(Z = -1{,}10\), \(C = 3{,}00\) даёт \(T = -0{,}8982\), а третья \(Z = 0{,}20\), \(C = 0{,}40\) даёт \(T = 0{,}4472\). Эти три значения иллюстрируют выборку при \(\text{count} = 3\).
Частые вопросы
Почему некоторые значения такие большие? При \(v \le 1\) среднее не определено, а при \(v \le 2\) дисперсия бесконечна, поэтому значения большой величины — это ожидаемое поведение, а не ошибка.
Почему результаты меняются при каждом запуске? Каждое значение использует новые случайные равномерные числа, поэтому список каждый раз отличается, оставаясь при этом верным распределению Стьюдента.
А если \(v\) очень велико? Тогда распределение ведёт себя практически так же, как стандартное нормальное \(\mathcal{N}(0,1)\).