यह टूल क्या करता है
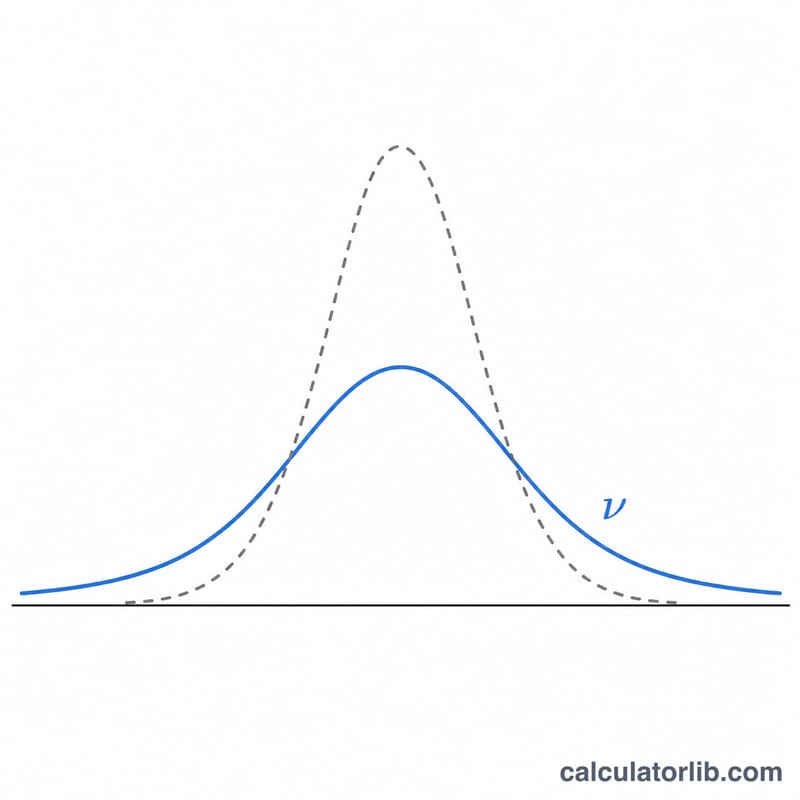
यह जनरेटर आपकी चुनी हुई स्वतंत्रता कोटि (\(v\)) के साथ स्टूडेंट t-वितरण से छद्म-यादृच्छिक (pseudo-random) संख्याओं की एक सूची तैयार करता है। t-वितरण एक घंटी के आकार का, सममित वितरण है, जिसकी पूँछें (tails) मानक सामान्य वितरण की तुलना में भारी होती हैं। यह वितरण तब स्वाभाविक रूप से सामने आता है जब किसी सामान्य रूप से वितरित समष्टि (population) के माध्य का अनुमान एक छोटे नमूने से लगाया जाता है, जहाँ प्रसरण (variance) अज्ञात होता है — और यही t-टेस्ट तथा विश्वास अंतराल (confidence interval) का आधार बनता है। जैसे-जैसे \(v\) बढ़ता है, t-वितरण मानक सामान्य वितरण \(\mathcal{N}(0,1)\) की ओर अभिसरित हो जाता है। यह एक शुद्ध गणितीय टूल है, इसमें किसी क्षेत्र या देश से जुड़ी कोई धारणा नहीं है।
इसका उपयोग कैसे करें
स्वतंत्रता कोटि \(v\) दर्ज करें (0 से बड़ी कोई भी वास्तविक संख्या; डिफ़ॉल्ट 2 है) और कितने यादृच्छिक मान चाहिए वह संख्या भरें (1 से 1000 तक का पूर्णांक; डिफ़ॉल्ट 10 है)। "Calculate" दबाते ही t-वितरित मानों की एक नई सूची मिल जाएगी। चूँकि अंतर्निहित एकसमान (uniform) नमूने यादृच्छिक होते हैं, इसलिए हर बार चलाने पर अलग संख्याएँ मिलती हैं, लेकिन वे हमेशा एक ही लक्ष्य वितरण का अनुसरण करती हैं।
सूत्र की व्याख्या
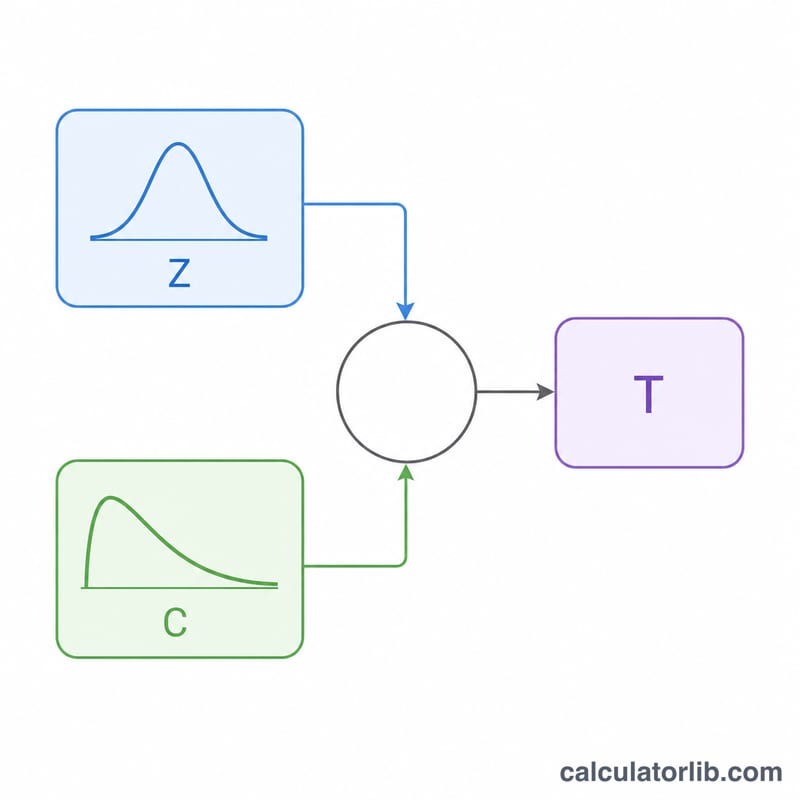
घनत्व फलन है $$f(x,v) = \frac{\left(1 + x^{2}/v\right)^{-(v+1)/2}}{\sqrt{v}\, B\!\left(\tfrac{1}{2}, \tfrac{v}{2}\right)}$$ जहाँ \(B\) बीटा फलन (Beta function) है। कुशलता से नमूने लेने के लिए हम एक शास्त्रीय निरूपण का उपयोग करते हैं: मानक सामान्य वितरण से \(Z\) और \(v\) स्वतंत्रता कोटियों वाले काई-वर्ग (chi-square) वितरण से \(C\) निकालें, फिर $$T = Z \cdot \sqrt{\frac{v}{C}}$$ बिल्कुल t-वितरित होता है। आंतरिक रूप से \(Z\) बॉक्स-मुलर रूपांतरण (Box-Muller transform) से आता है और \(C\) गामा\(\left(\tfrac{v}{2}, 2\right)\) सैम्पलर (Marsaglia-Tsang) से, जो किसी भी वास्तविक \(v > 0\) के लिए मान्य है।
हल किया हुआ उदाहरण
मान लीजिए \(v = 2\) है और एक बार चलाने पर \(Z = 0.50\) तथा काई-वर्ग मान \(C = 1.20\) मिलता है। तब $$T = 0.50 \cdot \sqrt{\frac{2}{1.20}} = 0.50 \cdot 1.29099 = 0.6455$$ दूसरे जोड़े \(Z = -1.10\), \(C = 3.00\) से \(T = -0.8982\) मिलता है, और तीसरे \(Z = 0.20\), \(C = 0.40\) से \(T = 0.4472\) मिलता है। ये तीन मान \(\text{count} = 3\) के लिए एक नमूने को दर्शाते हैं।
अक्सर पूछे जाने वाले प्रश्न
कुछ मान इतने बड़े क्यों होते हैं? \(v \le 1\) के लिए माध्य अपरिभाषित होता है और \(v \le 2\) के लिए प्रसरण अनंत होता है, इसलिए बहुत बड़े परिमाण वाले मान आना अपेक्षित है — ये त्रुटियाँ नहीं हैं।
हर बार परिणाम क्यों बदल जाते हैं? हर नमूना नए यादृच्छिक एकसमान मानों का उपयोग करता है, इसलिए सूची हर बार अलग होती है, फिर भी वह t-वितरण का ही पालन करती है।
अगर \(v\) बहुत बड़ा हो तो? तब वितरण लगभग बिल्कुल मानक सामान्य वितरण \(\mathcal{N}(0,1)\) जैसा व्यवहार करता है।