Công cụ này làm gì
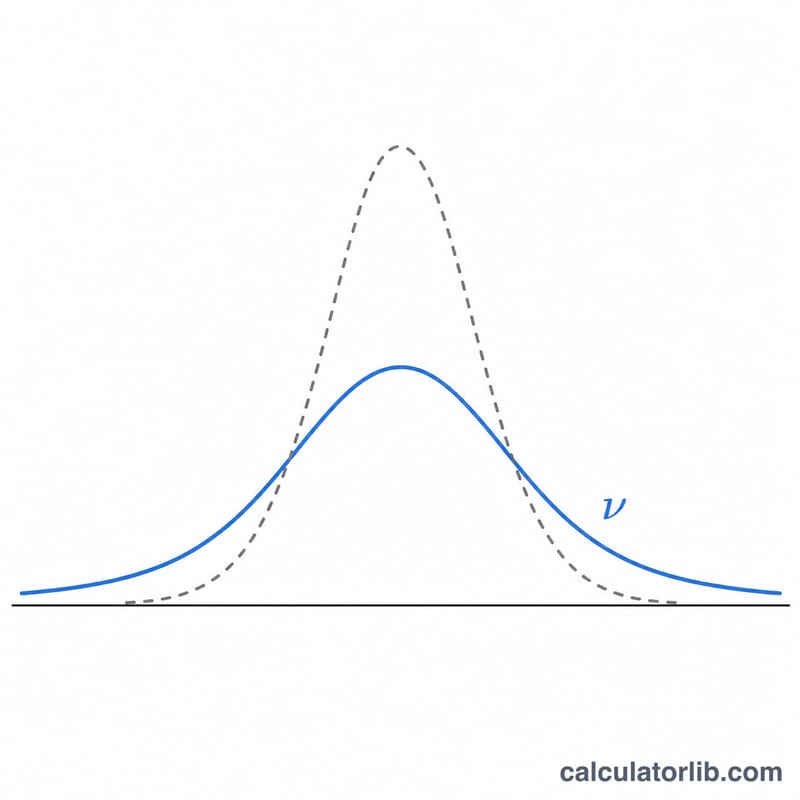
Trình tạo này sản sinh một danh sách số ngẫu nhiên giả lấy từ phân phối t-Student với số bậc tự do (v) do bạn chọn. Phân phối t có dạng hình chuông, đối xứng và có đuôi dày hơn so với phân phối chuẩn tắc. Nó xuất hiện một cách tự nhiên khi ta ước lượng trung bình của một tổng thể phân phối chuẩn dựa trên mẫu nhỏ với phương sai chưa biết, đồng thời là nền tảng của kiểm định t và khoảng tin cậy. Khi v càng lớn, phân phối t càng hội tụ về phân phối chuẩn tắc \(\mathcal{N}(0,1)\). Đây là công cụ toán học thuần túy, không gắn với giả định vùng miền nào.
Cách sử dụng
Nhập số bậc tự do v (bất kỳ số thực nào lớn hơn 0; mặc định là 2) và số lượng giá trị ngẫu nhiên bạn muốn (số nguyên từ 1 đến 1000; mặc định là 10). Nhấn tính toán và một danh sách giá trị mới tuân theo phân phối t sẽ được trả về. Vì các giá trị đều dựa trên số ngẫu nhiên cơ sở, mỗi lần chạy bạn sẽ nhận được những con số khác nhau, nhưng tất cả đều tuân theo cùng một phân phối mục tiêu.
Giải thích công thức
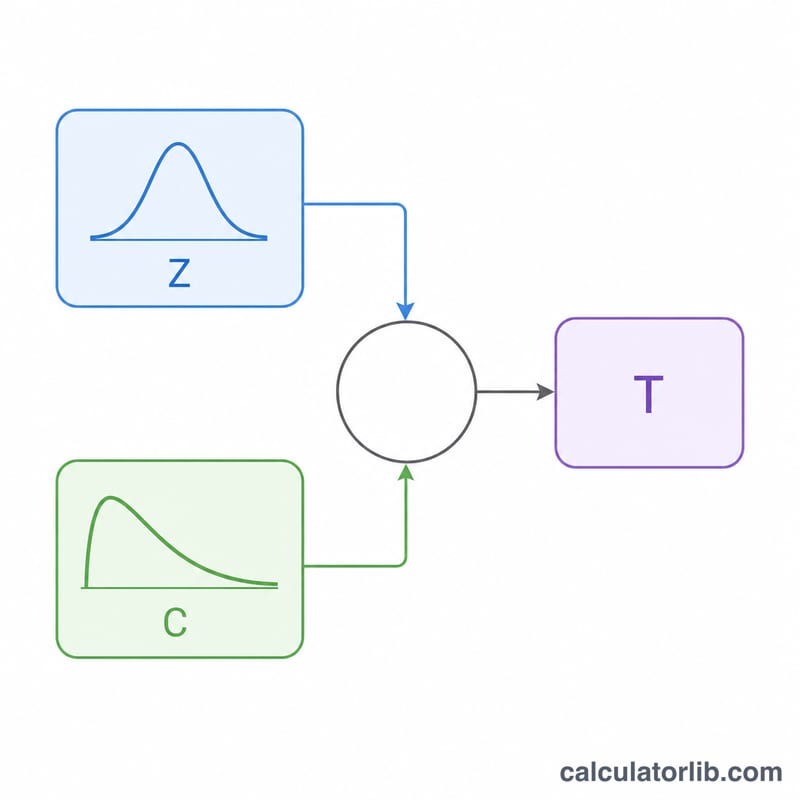
Hàm mật độ là \(f(x,\text{v}) = \dfrac{(1 + x^{2}/\text{v})^{-(\text{v}+1)/2}}{\sqrt{\text{v}} \cdot B\left(\tfrac{1}{2}, \tfrac{\text{v}}{2}\right)}\), trong đó \(B\) là hàm Beta. Để lấy mẫu hiệu quả, ta dùng cách biểu diễn kinh điển: lấy \(Z\) từ phân phối chuẩn tắc và \(C\) từ phân phối chi bình phương với v bậc tự do, khi đó
$$T = Z \cdot \sqrt{\dfrac{\text{v}}{C}}$$chính xác tuân theo phân phối t. Bên trong, \(Z\) được tạo bằng phép biến đổi Box-Muller và \(C\) được tạo bằng bộ lấy mẫu \(\text{Gamma}(\text{v}/2,\, 2)\) (Marsaglia-Tsang), hợp lệ với mọi số thực \(\text{v} > 0\).
Ví dụ minh họa
Với \(\text{v} = 2\), giả sử một lần chạy cho \(Z = 0{,}50\) và giá trị chi bình phương \(C = 1{,}20\). Khi đó
$$T = 0{,}50 \cdot \sqrt{\dfrac{2}{1{,}20}} = 0{,}50 \cdot 1{,}29099 = 0{,}6455$$Cặp thứ hai \(Z = -1{,}10\), \(C = 3{,}00\) cho \(T = -0{,}8982\), và cặp thứ ba \(Z = 0{,}20\), \(C = 0{,}40\) cho \(T = 0{,}4472\). Ba giá trị này minh họa một mẫu với count = 3.
Câu hỏi thường gặp
Vì sao một số giá trị lại rất lớn? Với \(\text{v} \le 1\) thì trung bình không xác định, và với \(\text{v} \le 2\) thì phương sai là vô hạn, nên việc xuất hiện những giá trị có độ lớn cao là điều dự kiến, không phải lỗi.
Vì sao kết quả thay đổi mỗi lần chạy? Mỗi lần lấy mẫu dùng các số ngẫu nhiên đều mới, nên danh sách luôn khác nhau nhưng vẫn tuân theo phân phối t.
Nếu v rất lớn thì sao? Phân phối khi đó gần như trùng khít với phân phối chuẩn tắc \(\mathcal{N}(0,1)\).