這個工具的用途
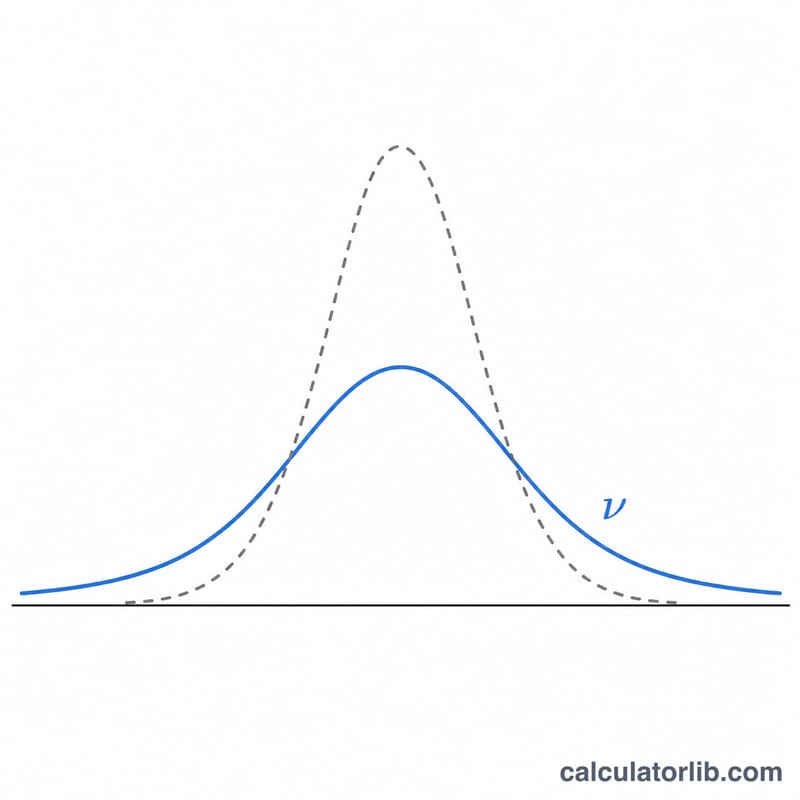
這個產生器會依你指定的自由度(v),從學生 t 分配中抽出一連串擬亂數。t 分配是一種鐘形、左右對稱的分配,比標準常態分配的尾端更厚(重尾)。當我們用小樣本去估計常態母體的平均數、而母體變異數又未知時,t 分配便自然登場,它同時也是 t 檢定與信賴區間的理論基礎。隨著自由度 v 越來越大,t 分配會逐漸收斂到標準常態分配 \(\mathcal{N}(0,1)\)。這是純數學工具,不涉及任何地區性的假設。
使用方法
輸入自由度 v(任何大於 0 的實數,預設為 2),再輸入想要產生的數值個數(1 到 1000 之間的整數,預設為 10)。按下計算,就會回傳一組全新的 t 分配抽樣結果。由於底層的均勻分配抽樣本身具有隨機性,每次執行得到的數字都不一樣,但它們始終服從同一個目標分配。
公式說明
機率密度函數為 $$f(x,v) = \frac{\left(1 + x^{2}/v\right)^{-(v+1)/2}}{\sqrt{v}\,B\!\left(\tfrac{1}{2},\,\tfrac{v}{2}\right)}$$ 其中 \(B\) 為 Beta 函數。為了有效率地抽樣,我們採用經典的表示法:先從標準常態分配抽出 \(Z\),再從自由度為 v 的卡方分配抽出 \(C\),則 $$T = Z \cdot \sqrt{\frac{v}{C}}$$ 就剛好服從 t 分配。在程式內部,\(Z\) 由 Box-Muller 轉換產生,\(C\) 則由 \(\text{Gamma}(v/2,\,2)\) 取樣器(Marsaglia-Tsang 演算法)產生,對任何實數 \(v > 0\) 皆適用。
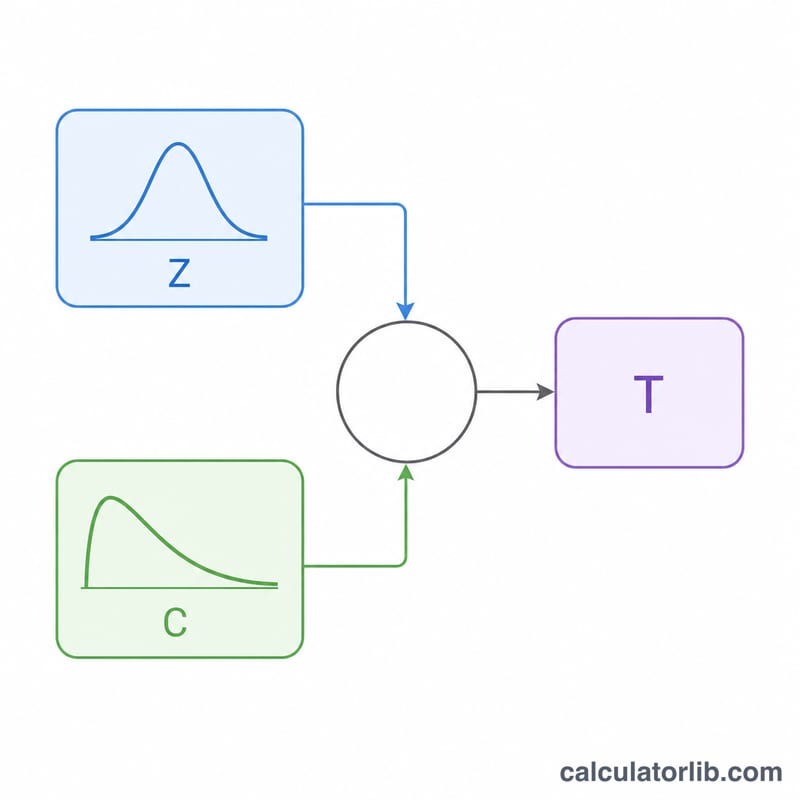
實際範例
以 \(v = 2\) 為例,假設某次執行得到 \(Z = 0.50\)、卡方抽樣值 \(C = 1.20\),那麼 $$T = 0.50 \cdot \sqrt{\frac{2}{1.20}} = 0.50 \cdot 1.29099 = 0.6455$$ 第二組 \(Z = -1.10\)、\(C = 3.00\),得到 \(T = -0.8982\);第三組 \(Z = 0.20\)、\(C = 0.40\),得到 \(T = 0.4472\)。這三個數值就是 \(\text{count} = 3\) 時的一組樣本示範。
常見問題
為什麼有些數值特別大?當 \(v \le 1\) 時平均數沒有定義,當 \(v \le 2\) 時變異數為無限大,因此出現絕對值很大的抽樣值是預期之中的現象,並不是錯誤。
為什麼每次結果都不一樣?每次抽樣都會使用全新的均勻亂數,所以列表每次都不同,但仍然服從相同的 t 分配。
如果 v 很大會怎樣?此時分配的表現幾乎與標準常態分配 \(\mathcal{N}(0,1)\) 一模一樣。