這個工具的用途
本產生器會依照您指定的平均數與標準差,輸出一串符合常態(高斯)分布的偽隨機數。它採用經典的 Box-Muller 轉換,這是一種既簡單又精確的方法,能將均勻分布的隨機數轉換成常態分布的隨機數。最終結果就是以逗號分隔的數值清單,每個數值都來自 N(μ, σ²)。
使用方式
請輸入 平均數(μ),也就是分布的中心;以及 標準差(σ),代表數值分散的程度。接著設定您想產生的數量(1 到 1000 個),並選擇顯示精度(有效位數)。由於每次運算都帶有隨機性,因此每次送出都會得到全新的一組數字。
公式說明
先在開區間 (0,1) 上抽取兩個互相獨立的均勻隨機數 U1 與 U2。Box-Muller 轉換會將它們轉換成兩個互相獨立的標準常態變數:Z1 = √(−2·ln U1)·cos(2πU2),以及 Z2 = √(−2·ln U1)·sin(2πU2)。因此每執行一次就能同時得到兩個常態值。最後再以 X = μ + σ·Z 將每個標準常態值重新縮放。為了避免出現 ln(0) = −∞ 的情況,程式會確保 U1 永遠不會剛好等於零。
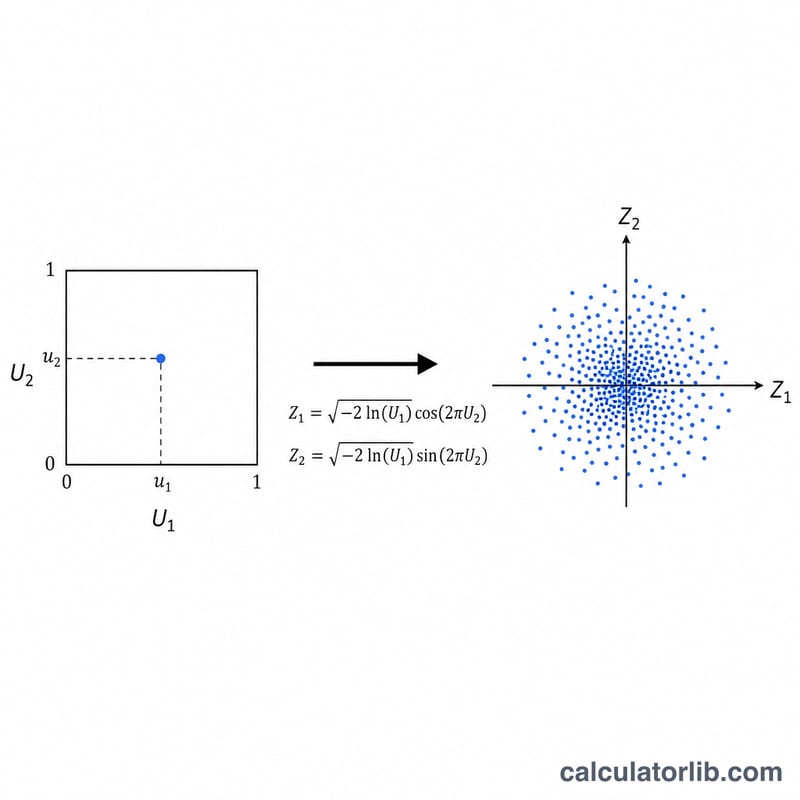
實際範例
假設 μ = 100、σ = 15,並設 U1 = 0.5、U2 = 0.25。則 √(−2·ln 0.5) = √1.386294 = 1.177410。由於 cos(π/2) = 0、sin(π/2) = 1,可得 Z1 = 0、Z2 = 1.177410。因此 X1 = 100 + 15·0 = 100,X2 = 100 + 15·1.177410 = 117.66115。當抽取的配對數量越多,整組數值的樣本平均數會越接近 100,樣本標準差也會越接近 15。
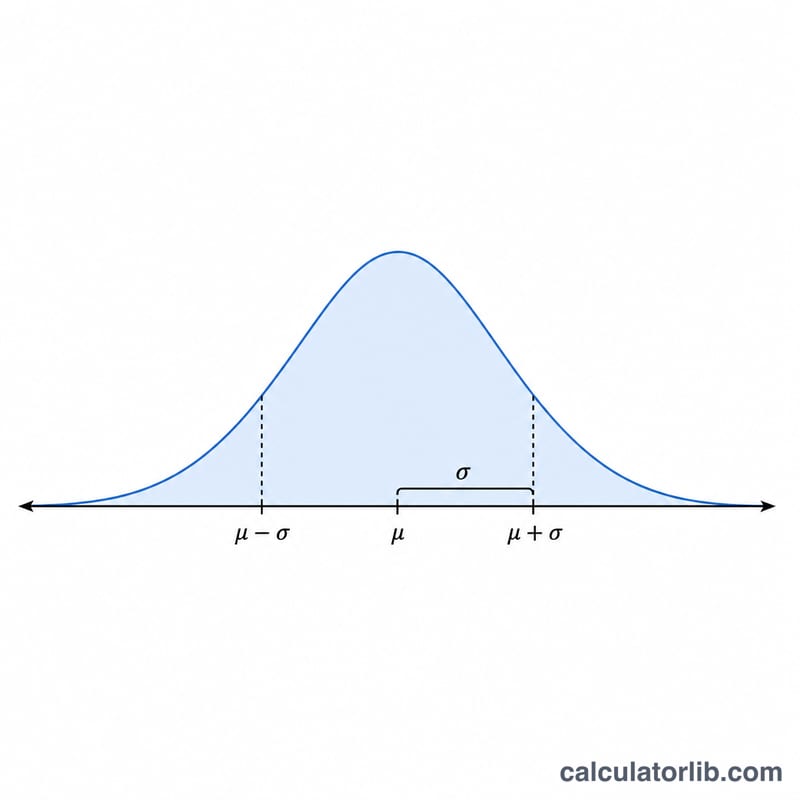
68-95-99.7 法則(經驗法則)
對於任何常態分佈 \(N(\mu, \sigma^2)\),值的可預測比例落在平均值的固定標準差數內。這就是經驗法則,對於你生成的數字是一個有用的合理性檢查:有足夠大的樣本時,以下比例應該會自動出現。
| 區間 | 數值範圍 | 區間內的比例 | 尾部的比例 |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) 至 \(\mu + \sigma\) | 68.27% | 31.73% |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) 至 \(\mu + 2\sigma\) | 95.45% | 4.55% |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) 至 \(\mu + 3\sigma\) | 99.73% | 0.27% |
範例:如果你生成的數字為 \(\mu = 100\) 和 \(\sigma = 15\),那麼約 68% 的值應該落在 85 到 115 之間,約 95% 落在 70 到 130 之間,約 99.7% 落在 55 到 145 之間。在 \(\pm 3\sigma\) 之外的值(此處低於 55 或高於 145)預期只在 1,000 次抽取中出現約 3 次。
解釋你生成的數字
Box-Muller 變換產生遵循以你選擇的平均值 \(\mu\) 為中心、由標準差 \(\sigma\) 設定分散的常態(高斯)分佈的值。請記住這些事實來閱讀它們:
- 大多數值聚集在平均值附近。鐘形曲線在 \(\mu\) 處最密集,因此典型的抽取接近 \(\mu\);約三分之二的值落在它的一個 \(\sigma\) 內。
- 極端值很罕見但可能。一個遠在尾部的值(例如超過 \(3\sigma\))是不尋常的,不是不可能的——它大約在 0.27% 的時間出現。看到偶爾的離群值是正常行為,不是錯誤。
- 樣本統計量隨著 \(n\) 增長而收斂。對於小的計數,樣本平均值和樣本標準差可能會因巧合而明顯偏離 \(\mu\) 和 \(\sigma\)。隨著你增加
count,樣本平均值接近 \(\mu\) 和樣本標準差接近 \(\sigma\)(大數法則)。你可以將一批數據粘貼到樣本平均值計算機或母群標準差計算機來確認值朝著你的目標漂移。 - 這是用於模擬和測試。這些是為蒙地卡羅實驗、負載/壓力測試、教學和建模而設計的虛擬隨機抽取——不是任何真實世界數量的實際測量。這些數字除了你指定的分佈外沒有經驗意義。
定義與詞彙表
- 平均值(\(\mu\))
- 分佈的中心或期望值——生成值平衡其周圍的平均值。
- 標準差(\(\sigma\))
- 分散的度量,單位與數據相同。較大的 \(\sigma\) 產生從平均值散佈更廣泛的值。
- 變異數(\(\sigma^2\))
- 標準差的平方,\(\sigma^2\)。它以平方單位量化分散,並且是出現在分佈記號 \(N(\mu, \sigma^2)\) 中的參數。
- 標準常態分佈,\(N(0,1)\)
- 特殊的常態分佈,平均值為 0,標準差為 1。從中抽取的任何值 \(Z\) 通過 \(X = \mu + \sigma Z\) 重新縮放到你的分佈。
- 均勻分佈
- 一個分佈,其中區間內的每個值(此處為 \((0,1)\))的可能性相同。Box-Muller 方法從兩個獨立的均勻抽取 \(U_1\) 和 \(U_2\) 開始。
- Z 分數
- 一個值距離平均值的帶符號標準差數,\(Z = (X - \mu)/\sigma\)。Z 分數為 0 表示正好在平均值;\(\pm 2\) 標記中央 95.45% 的邊界。
- 虛擬隨機
- 由確定性演算法生成,產生具有隨機性統計特性的序列。輸出看起來是隨機的並通過統計測試,但從相同的種子完全可重現。
- Box-Muller 變換
- 一種方法,使用 \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\) 將兩個獨立的均勻隨機數 \(U_1, U_2\) 轉換為標準常態值,然後將其移動和縮放到請求的平均值和標準差。
常見問題
為什麼每次的數字都不一樣?本產生器每次都會抽取全新的均勻隨機數,且不固定亂數種子(seed),因此輸出本來就是隨機的。
如果我把 σ 設為 0 會怎樣?此時分布會退化,所有產生的數值都會等於平均數。
為什麼樣本平均數沒有剛好等於 μ?隨機抽樣本身會產生抽樣誤差;產生的數字越多,樣本平均數與樣本標準差就會越接近 μ 與 σ。