À quoi sert cet outil
Ce générateur produit une liste de nombres pseudo-aléatoires qui suivent une loi normale (gaussienne) avec la moyenne et l'écart type que vous définissez. Il s'appuie sur la célèbre transformation de Box-Muller, une méthode simple et exacte pour convertir des nombres aléatoires uniformes en nombres distribués selon une loi normale. Le résultat essentiel est une liste de valeurs séparées par des virgules, chacune tirée de N(μ, σ²).
Mode d'emploi
Saisissez la moyenne (μ) — le centre de la distribution — et l'écart type (σ) — la dispersion souhaitée des valeurs. Indiquez le nombre de valeurs voulu (de 1 à 1000), puis choisissez la précision d'affichage en chiffres significatifs. Chaque exécution est stochastique : vous obtiendrez donc un nouveau jeu de nombres à chaque validation.
La formule expliquée
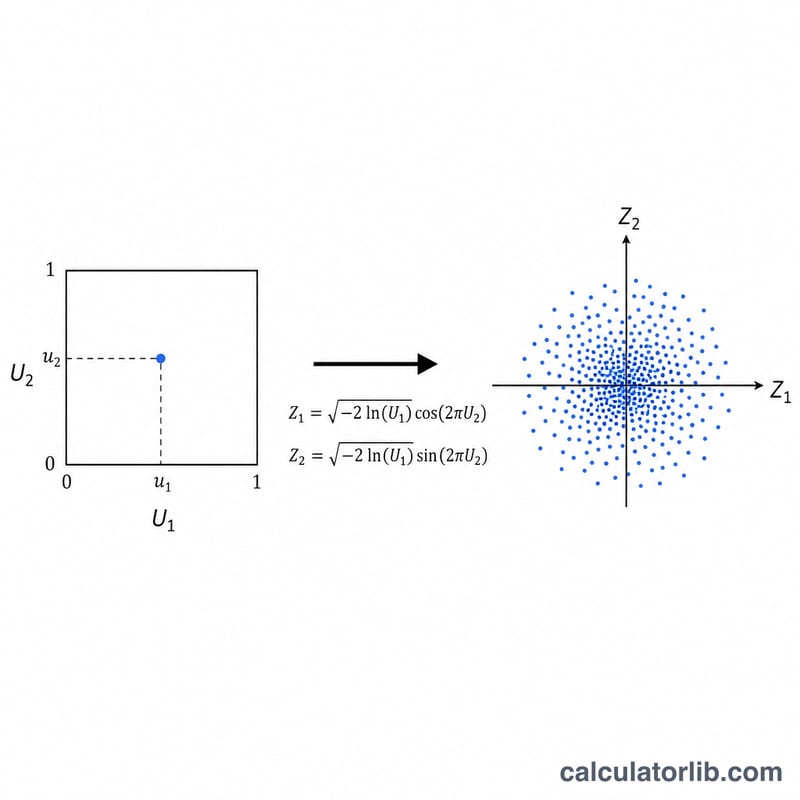
On tire deux nombres uniformes indépendants U1 et U2 sur l'intervalle ouvert (0,1). La transformation de Box-Muller les convertit en deux variables normales centrées réduites indépendantes : Z1 = √(−2·ln U1)·cos(2πU2) et Z2 = √(−2·ln U1)·sin(2πU2). Chaque passage fournit ainsi deux valeurs normales à la fois. On remet ensuite chaque valeur normale centrée réduite à l'échelle avec X = μ + σ·Z. Pour éviter ln(0) = −∞, U1 est protégé afin de ne jamais valoir exactement zéro.
Exemple concret
Prenons μ = 100, σ = 15, et supposons U1 = 0,5, U2 = 0,25. Alors √(−2·ln 0,5) = √1,386294 = 1,177410. Avec cos(π/2) = 0 et sin(π/2) = 1, on obtient Z1 = 0 et Z2 = 1,177410. Donc X1 = 100 + 15·0 = 100 et X2 = 100 + 15·1,177410 = 117,66115. Sur un grand nombre de paires, la moyenne empirique du jeu de valeurs se rapproche de 100 et son écart type empirique de 15.
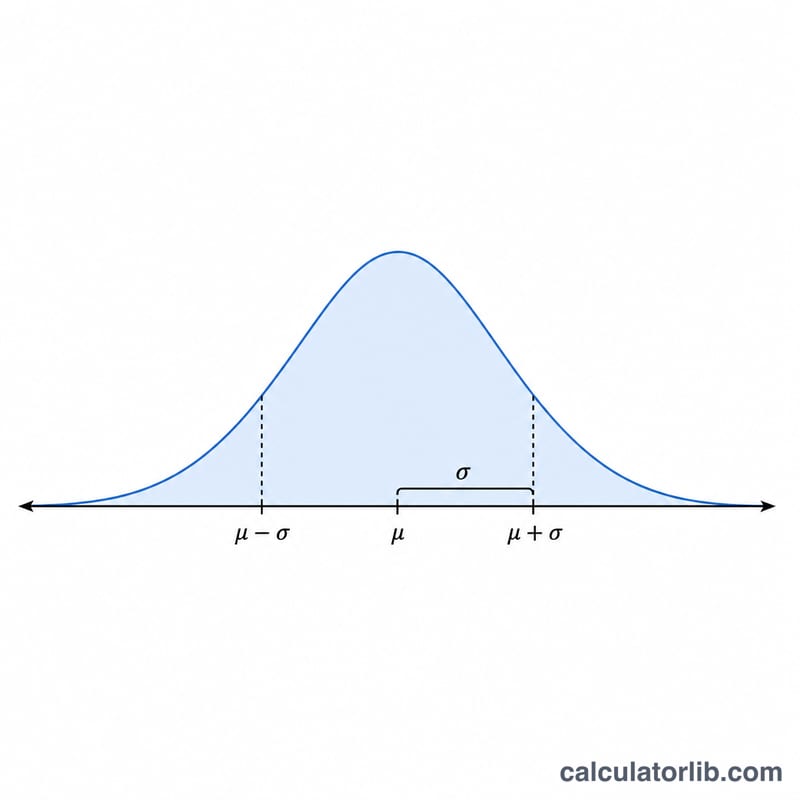
La règle 68-95-99,7 (règle empirique)
Pour toute distribution normale \(N(\mu, \sigma^2)\), une part prévisible de valeurs se situe dans un nombre fixe d'écarts-types de la moyenne. C'est la règle empirique, et elle constitue une vérification de cohérence utile pour les nombres que vous générez : avec un échantillon assez grand, les proportions ci-dessous devraient émerger automatiquement.
| Intervalle | Plage de valeurs | Proportion à l'intérieur | Proportion dans les queues |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) à \(\mu + \sigma\) | 68,27 % | 31,73 % |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) à \(\mu + 2\sigma\) | 95,45 % | 4,55 % |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) à \(\mu + 3\sigma\) | 99,73 % | 0,27 % |
Exemple : si vous générez des nombres avec \(\mu = 100\) et \(\sigma = 15\), environ 68 % des valeurs devraient se situer entre 85 et 115, environ 95 % entre 70 et 130, et environ 99,7 % entre 55 et 145. Les valeurs en dehors de \(\pm 3\sigma\) (en dessous de 55 ou au-dessus de 145 ici) sont attendues seulement environ 3 fois sur 1 000 tirages.
Interprétation de vos nombres générés
La transformation de Box-Muller produit des valeurs qui suivent une distribution normale (gaussienne) centrée sur votre moyenne choisie \(\mu\) avec une dispersion définie par votre écart-type \(\sigma\). Lisez-les en tenant compte de ces faits :
- La plupart des valeurs se regroupent près de la moyenne. La forme de cloche est la plus dense en \(\mu\), donc un tirage typique est proche de \(\mu\) ; environ deux tiers des valeurs se situent à moins d'un \(\sigma\) de celle-ci.
- Les valeurs extrêmes sont rares mais possibles. Une valeur loin dans une queue (disons au-delà de \(3\sigma\)) est inhabituelle, pas impossible — elle se produit environ 0,27 % du temps. Voir une valeur aberrante occasionnelle est un comportement normal, pas un bug.
- Les statistiques d'échantillon convergent à mesure que \(n\) augmente. Pour un petit nombre, la moyenne d'échantillon et l'écart-type d'échantillon peuvent différer notablement de \(\mu\) et \(\sigma\) par hasard. À mesure que vous augmentez
count, la moyenne d'échantillon se rapproche de \(\mu\) et l'écart-type d'échantillon se rapproche de \(\sigma\) (loi des grands nombres). Vous pouvez coller un lot dans un calculateur de moyenne d'échantillon ou un calculateur d'écart-type de population pour confirmer que les valeurs se rapprochent de vos cibles. - C'est pour la simulation et les tests. Ce sont des tirages pseudo-aléatoires destinés aux expériences de Monte Carlo, aux tests de charge/stress, à l'enseignement et à la modélisation — pas des mesures réelles d'une quelconque quantité du monde réel. Les nombres n'ont aucune signification empirique au-delà de la distribution que vous avez spécifiée.
Définitions et glossaire
- Moyenne (\(\mu\))
- Le centre, ou la valeur attendue, de la distribution — la moyenne autour de laquelle les valeurs générées sont équilibrées.
- Écart-type (\(\sigma\))
- Une mesure de la dispersion dans les mêmes unités que les données. Un \(\sigma\) plus grand produit des valeurs dispersées plus largement autour de la moyenne.
- Variance (\(\sigma^2\))
- Le carré de l'écart-type, \(\sigma^2\). Il quantifie la dispersion en unités au carré et est le paramètre qui apparaît dans la notation de distribution \(N(\mu, \sigma^2)\).
- Loi normale standard, \(N(0,1)\)
- La distribution normale spéciale avec une moyenne de 0 et un écart-type de 1. Toute valeur \(Z\) tirée de celle-ci est redimensionnée à votre distribution via \(X = \mu + \sigma Z\).
- Distribution uniforme
- Une distribution dans laquelle chaque valeur d'un intervalle (ici, \((0,1)\)) est équiprobable. La méthode de Box-Muller commence par deux tirages uniformes indépendants \(U_1\) et \(U_2\).
- Score Z
- Le nombre signé d'écarts-types qu'une valeur écarte de la moyenne, \(Z = (X - \mu)/\sigma\). Un score Z de 0 est exactement à la moyenne ; \(\pm 2\) marque le bord des 95,45 % centraux.
- Pseudo-aléatoire
- Généré par un algorithme déterministe qui produit des séquences avec les propriétés statistiques du hasard. La sortie ressemble à du hasard et réussit les tests statistiques mais est entièrement reproductible à partir de la même graine.
- Transformation de Box-Muller
- Une méthode qui convertit deux nombres aléatoires uniformes indépendants \(U_1, U_2\) en une valeur normale standard en utilisant \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\), qui est ensuite décalée et mise à l'échelle selon la moyenne et l'écart-type demandés.
FAQ
Pourquoi les nombres changent-ils à chaque fois ? Le générateur utilise de nouveaux tirages uniformes sans graine fixe : le résultat est donc aléatoire par conception.
Que se passe-t-il si je fixe σ = 0 ? La distribution devient dégénérée et chaque valeur générée est égale à la moyenne.
Pourquoi ma moyenne empirique n'est-elle pas exactement égale à μ ? L'échantillonnage aléatoire introduit une erreur d'échantillonnage ; plus vous générez de nombres, plus la moyenne et l'écart type empiriques se rapprochent de μ et σ.