このツールでできること
このツールは、お好みの平均と標準偏差に従う正規分布(ガウス分布)の擬似乱数をまとめて生成します。計算には古典的な手法として知られるBox-Muller法(ボックス=ミュラー変換)を採用しており、一様分布の乱数を正規分布の乱数へ厳密に変換できるシンプルな方式です。出力結果は N(μ, σ²) から得られた値をカンマ区切りで並べた一覧となり、これが本ツールの中心的な成果物です。
使い方
まず分布の中心となる平均(μ)と、値の散らばり具合を表す標準偏差(σ)を入力します。次に生成したい乱数の個数(1〜1000)を指定し、表示する有効桁数を選びます。生成は確率的に行われるため、実行のたびに異なる乱数の組が得られます。
計算式の解説
まず開区間 (0,1) 上で互いに独立な一様乱数 U1 と U2 を取り出します。Box-Muller法では、これらを次の式で互いに独立な標準正規乱数 2 つに変換します。
Z1 = √(−2·ln U1)·cos(2πU2)
Z2 = √(−2·ln U1)·sin(2πU2)
つまり 1 回の処理で正規乱数を 2 つ同時に得られます。得られた標準正規乱数は X = μ + σ·Z によって任意の平均・標準偏差にスケール変換します。なお ln(0) = −∞ となるのを避けるため、U1 がちょうど 0 にならないように処理しています。
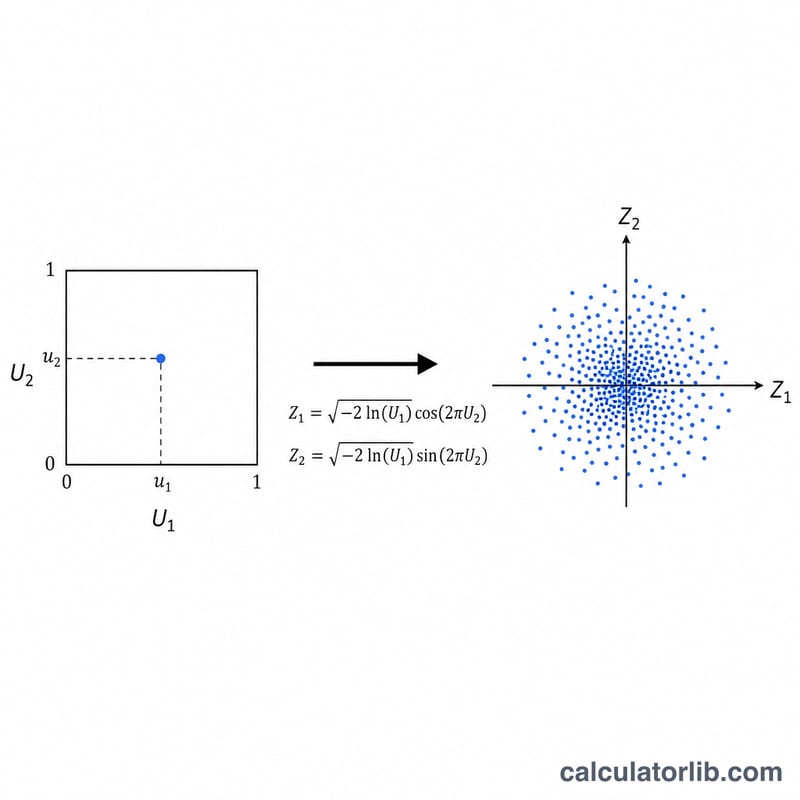
計算例
μ = 100、σ = 15 とし、U1 = 0.5、U2 = 0.25 だったとします。このとき √(−2·ln 0.5) = √1.386294 = 1.177410 です。cos(π/2) = 0、sin(π/2) = 1 なので、Z1 = 0、Z2 = 1.177410 となります。したがって X1 = 100 + 15·0 = 100、X2 = 100 + 15·1.177410 = 117.66115 が得られます。多くのペアを生成すると、その集合の標本平均は 100 に、標本標準偏差は 15 に近づいていきます。
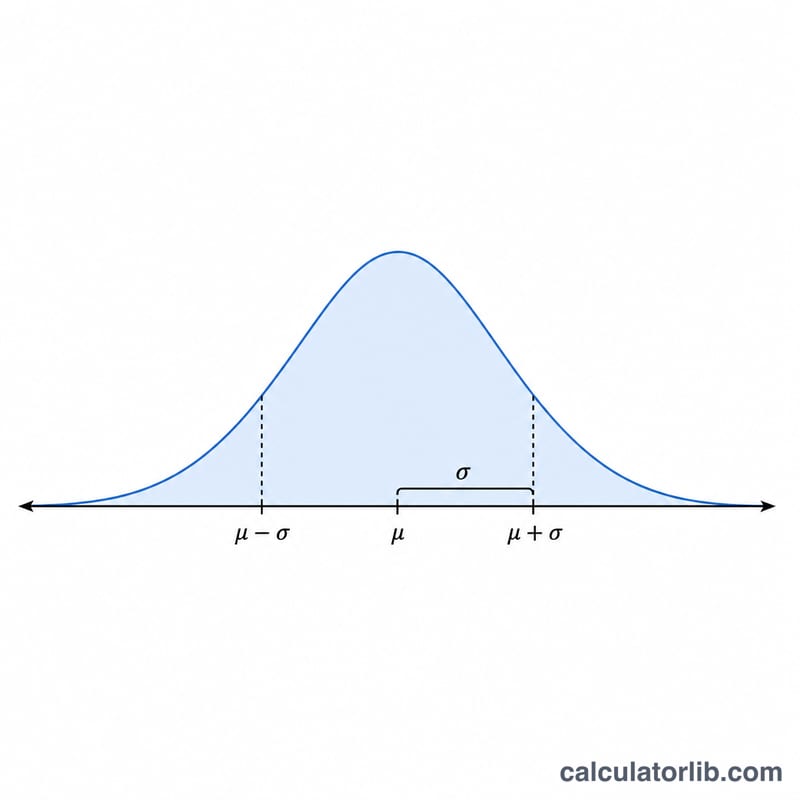
68-95-99.7ルール(経験則)
任意の正規分布 \(N(\mu, \sigma^2)\) について、平均からの標準偏差の固定倍数以内に落ちる値の割合は予測可能です。これが経験則であり、生成する数値の妥当性チェックとして有用です。十分に大きなサンプルがあれば、以下の比率は自動的に現れるはずです。
| 区間 | 値の範囲 | 内側の割合 | 裾部の割合 |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) から \(\mu + \sigma\) | 68.27% | 31.73% |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) から \(\mu + 2\sigma\) | 95.45% | 4.55% |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) から \(\mu + 3\sigma\) | 99.73% | 0.27% |
例:\(\mu = 100\) および \(\sigma = 15\) で数値を生成する場合、値の約68%は85から115の間に、約95%は70から130の間に、約99.7%は55から145の間に落ちるはずです。\(\pm 3\sigma\) の外側の値(ここでは55未満または145より大きい)は、1000回の抽出のうち約3回だけ現れることが予想されます。
生成された数値の解釈
Box-Muller変換は、選択した平均 \(\mu\) を中心に、標準偏差 \(\sigma\) で設定された広がりに従う正規(ガウス)分布に従う値を生成します。これらを以下の事実に留意して読んでください:
- ほとんどの値は平均付近に集中します。 ベル形は \(\mu\) で最も密になるため、典型的な抽出は \(\mu\) に近いものです。値の約3分の2は \(\sigma\) の1倍以内に落ちます。
- 極値は稀ですが可能です。 裾部のはるか遠くにある値(例えば \(3\sigma\) を超える)は珍しいものですが、不可能ではありません。このような値は約0.27%の時間で発生します。時々外れ値を見かけることは、通常の動作であり、バグではありません。
- サンプル統計量は \(n\) の増加に伴い収束します。 小さいカウントの場合、偶然によってサンプル平均およびサンプル標準偏差が \(\mu\) および \(\sigma\) から目立つほど異なることがあります。
countを増やすと、サンプル平均が \(\mu\) に接近し、サンプル標準偏差が \(\sigma\) に接近します(大数の法則)。バッチを サンプル平均計算機 または 母標準偏差計算機 に貼り付けて、値が目標値に向かってドリフトしていることを確認できます。 - これはシミュレーションとテスト用です。 これらは、モンテカルロ実験、負荷・ストレステスト、教育、およびモデリング用に意図された疑似乱数抽出です。実際の量の実測定ではありません。数値は、指定した分布を超えて経験的な意味を持ちません。
定義と用語集
- 平均(\(\mu\))
- 分布の中心、または期待値です。生成された値が均衡する平均です。
- 標準偏差(\(\sigma\))
- データと同じ単位での広がりの尺度です。より大きい \(\sigma\) は、平均からより広く散在した値を生成します。
- 分散(\(\sigma^2\))
- 標準偏差の二乗、\(\sigma^2\) です。二乗単位での広がりを定量化し、分布表記 \(N(\mu, \sigma^2)\) に現れるパラメータです。
- 標準正規分布、\(N(0,1)\)
- 平均0、標準偏差1の特殊な正規分布です。そこから抽出されたあらゆる値 \(Z\) は、\(X = \mu + \sigma Z\) を介してあなたの分布に再スケーリングされます。
- 一様分布
- 区間内のあらゆる値(ここでは \((0,1)\))が等しく起こりやすい分布です。Box-Muller法は2つの独立した一様抽出 \(U_1\) および \(U_2\) から始まります。
- Z値
- 値が平均から離れている符号付き標準偏差の数、\(Z = (X - \mu)/\sigma\) です。Z値0は正確に平均です。\(\pm 2\) は中央95.45%の端をマークしています。
- 疑似乱数
- 乱数の統計特性を持つシーケンスを生成する決定論的アルゴリズムによって生成されます。出力は乱数に見え、統計テストに合格しますが、同じシードから完全に再現可能です。
- Box-Muller変換
- 2つの独立した一様乱数 \(U_1, U_2\) を標準正規値 \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\) に変換するメソッドであり、その後、要求された平均と標準偏差にシフトおよびスケーリングされます。
よくある質問
実行するたびに値が変わるのはなぜですか? 本ツールは固定のシードを使わず、毎回新しい一様乱数を取り出して計算します。そのため出力が変わるのは仕様によるものです。
σ = 0 にするとどうなりますか? 分布が退化し、生成されるすべての値が平均と等しくなります。
標本平均が μ とぴったり一致しないのはなぜですか? 無作為抽出には標本誤差がつきものです。生成する個数を増やすほど、標本平均と標本標準偏差はそれぞれ μ・σ に近づいていきます。