这个工具能做什么
本生成器会按照你设定的均值和标准差,输出一组服从正态(高斯)分布的伪随机数。它采用经典的 Box-Muller 变换——一种把均匀分布随机数精确转换为正态分布随机数的简单方法。最终结果就是核心产出:一串以逗号分隔的数值,每一个都抽样自 N(μ, σ²)。
使用方法
先输入均值(μ),也就是分布的中心位置;再输入标准差(σ),用来控制数值的离散程度。然后设定要生成的随机数个数(1 到 1000),并选择显示精度(有效数字位数)。由于每次运算都是随机的,所以每次提交都会得到一组全新的数值。
公式详解
先在开区间 (0,1) 上抽取两个相互独立的均匀分布随机数 U1 和 U2。Box-Muller 变换会把它们转换成两个相互独立的标准正态变量:Z1 = √(−2·ln U1)·cos(2πU2),Z2 = √(−2·ln U1)·sin(2πU2)。因此每一次变换都能同时得到两个正态值。接着通过 X = μ + σ·Z 对每个标准正态值进行缩放和平移。为了避免出现 ln(0) = −∞,程序会做保护处理,确保 U1 永远不会恰好为零。
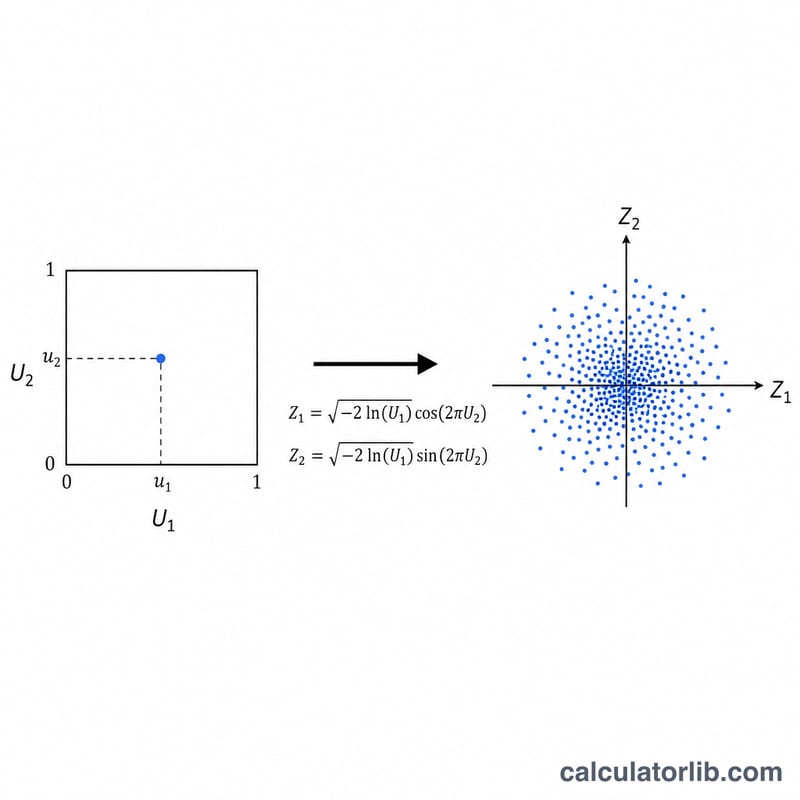
实例演算
设 μ = 100、σ = 15,并假设 U1 = 0.5、U2 = 0.25。则 √(−2·ln 0.5) = √1.386294 = 1.177410。由于 cos(π/2) = 0、sin(π/2) = 1,可得 Z1 = 0、Z2 = 1.177410。于是 X1 = 100 + 15·0 = 100,X2 = 100 + 15·1.177410 = 117.66115。当抽取的样本对足够多时,整组数据的样本均值会逐渐趋近 100,样本标准差会逐渐趋近 15。
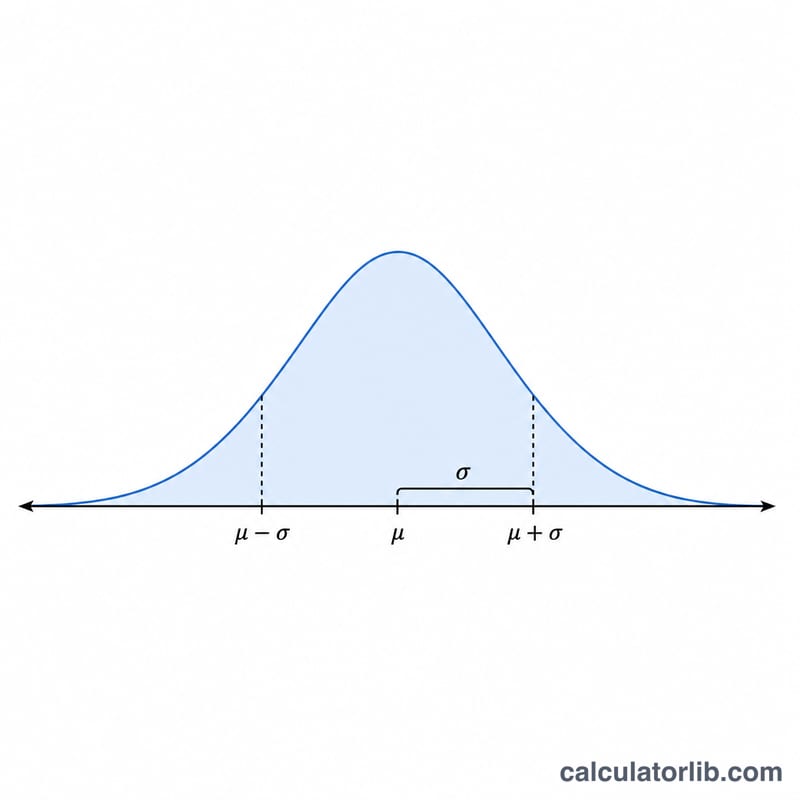
68-95-99.7 规则(经验规则)
对于任何正态分布 \(N(\mu, \sigma^2)\),有一个可预测的比例的数值落在均值的固定标准差数范围内。这就是经验规则,是对你生成的数字的有用健全性检查:对于足够大的样本,下面的比例应该自动出现。
| 区间 | 数值范围 | 内部比例 | 尾部比例 |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) 到 \(\mu + \sigma\) | 68.27% | 31.73% |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) 到 \(\mu + 2\sigma\) | 95.45% | 4.55% |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) 到 \(\mu + 3\sigma\) | 99.73% | 0.27% |
示例:如果你生成均值 \(\mu = 100\) 和标准差 \(\sigma = 15\) 的数字,那么约 68% 的数值应该落在 85 到 115 之间,约 95% 落在 70 到 130 之间,约 99.7% 落在 55 到 145 之间。落在 \(\pm 3\sigma\) 之外的数值(这里低于 55 或高于 145)预计在 1000 次抽取中只出现约 3 次。
解释你生成的数字
Box-Muller 变换生成遵循以你选择的均值 \(\mu\) 为中心、以你的标准差 \(\sigma\) 设定展度的正态(高斯)分布的数值。请记住以下事实来阅读它们:
- 大多数数值聚集在均值附近。钟形曲线在 \(\mu\) 处最密集,所以典型的抽取接近 \(\mu\);大约三分之二的数值落在它的一个 \(\sigma\) 范围内。
- 极端数值很少见但可能出现。一个远在尾部的数值(比如超过 \(3\sigma\))是不寻常的,但并非不可能 — 它约在 0.27% 的时间内出现。看到偶尔的异常值是正常行为,不是错误。
- 样本统计量随着 \(n\) 增长而收敛。对于较小的数量,样本均值和样本标准差可能由于偶然而与 \(\mu\) 和 \(\sigma\) 明显不同。当你增加
count时,样本均值趋近于 \(\mu\),样本标准差趋近于 \(\sigma\)(大数定律)。你可以将一批数据粘贴到样本均值计算器或总体标准差计算器中来确认这些数值是否趋向你的目标值。 - 这是用于模拟和测试的。这些是旨在用于蒙特卡罗实验、负载/压力测试、教学和建模的伪随机抽取 — 而不是任何真实数量的实际测量。这些数字除了你指定的分布外,没有任何经验意义。
定义及词汇表
- 均值 (\(\mu\))
- 分布的中心或期望值 — 生成的数值围绕其平衡的平均值。
- 标准差 (\(\sigma\))
- 与数据单位相同的展度的衡量。较大的 \(\sigma\) 会使数值从均值散布得更宽。
- 方差 (\(\sigma^2\))
- 标准差的平方,\(\sigma^2\)。它以平方单位量化展度,是出现在分布记号 \(N(\mu, \sigma^2)\) 中的参数。
- 标准正态,\(N(0,1)\)
- 均值为 0 且标准差为 1 的特殊正态分布。从它抽取的任何数值 \(Z\) 通过 \(X = \mu + \sigma Z\) 重新缩放到你的分布。
- 均匀分布
- 一个分布,其中区间内的每个数值(这里是 \((0,1)\))的可能性相等。Box-Muller 方法始于两个独立的均匀抽取 \(U_1\) 和 \(U_2\)。
- Z 分数
- 数值离均值的带符号标准差数,\(Z = (X - \mu)/\sigma\)。Z 分数为 0 表示正好在均值处;\(\pm 2\) 标记中心 95.45% 的边界。
- 伪随机
- 由一个确定性算法生成,该算法产生具有随机性统计性质的序列。输出看起来是随机的,通过统计测试,但从相同的种子完全可重现。
- Box-Muller 变换
- 一种方法,它使用 \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\) 将两个独立的均匀随机数 \(U_1, U_2\) 转换为标准正态值,然后将其平移和缩放到请求的均值和标准差。
常见问题
为什么每次生成的数字都不一样? 生成器每次都使用全新的均匀分布随机数,且没有固定的随机种子,所以输出本身就是随机的,这是有意为之。
如果把 σ 设为 0 会怎样? 此时分布退化,生成的每一个数值都等于均值。
为什么样本均值和 μ 不完全相等? 随机抽样必然带来抽样误差。生成的数字越多,样本均值和样本标准差就越接近 μ 和 σ。