Что делает этот инструмент
Генератор создаёт список псевдослучайных чисел, подчиняющихся нормальному (гауссову) распределению с заданными вами средним и стандартным отклонением. В его основе лежит классическое преобразование Бокса–Мюллера — простой и точный способ превратить равномерно распределённые случайные числа в нормально распределённые. Главный результат работы — список значений через запятую, каждое из которых извлечено из распределения N(μ, σ²).
Как пользоваться
Укажите среднее (μ) — центр распределения — и стандартное отклонение (σ) — меру разброса значений. Задайте, сколько чисел нужно сгенерировать (от 1 до 1000), и выберите точность вывода в значащих цифрах. Каждый запуск случаен, поэтому при каждой отправке вы получите новый набор чисел.
Разбор формулы
Берутся два независимых равномерных числа U1 и U2 на открытом интервале (0,1). Преобразование Бокса–Мюллера превращает их в две независимые стандартные нормальные величины: Z1 = √(−2·ln U1)·cos(2πU2) и Z2 = √(−2·ln U1)·sin(2πU2). Таким образом, каждый проход сразу даёт два нормальных значения. Каждую стандартную нормальную величину масштабируем по формуле X = μ + σ·Z. Чтобы избежать ln(0) = −∞, на U1 ставится защита: оно никогда не равно ровно нулю.
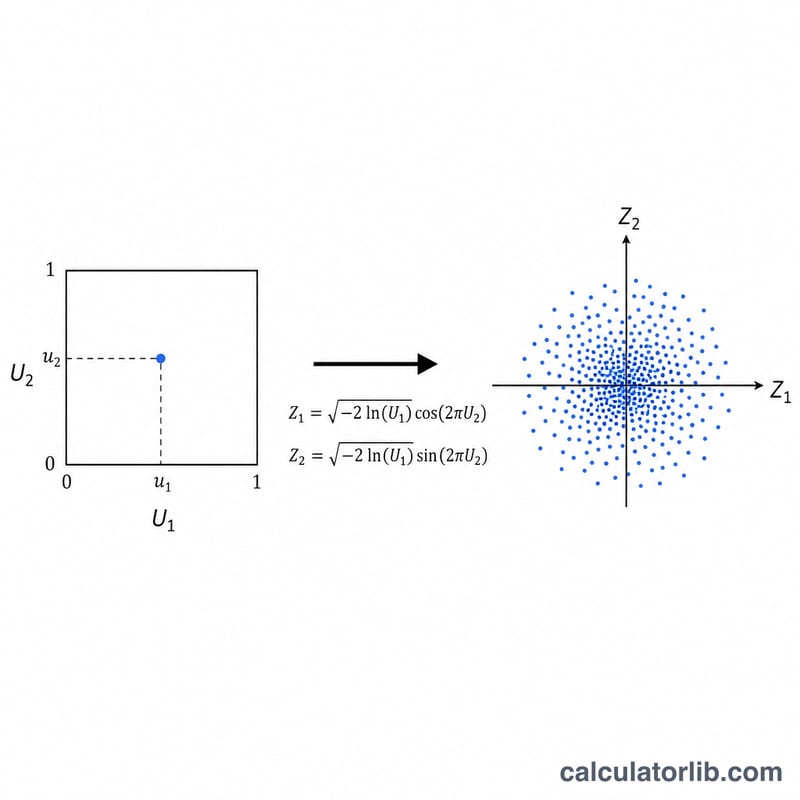
Пример с расчётом
Пусть μ = 100, σ = 15, а U1 = 0,5 и U2 = 0,25. Тогда √(−2·ln 0,5) = √1,386294 = 1,177410. Поскольку cos(π/2) = 0, а sin(π/2) = 1, получаем Z1 = 0 и Z2 = 1,177410. Значит, X1 = 100 + 15·0 = 100, а X2 = 100 + 15·1,177410 = 117,66115. При большом числе пар выборочное среднее набора стремится к 100, а выборочное стандартное отклонение — к 15.
Частые вопросы
Почему числа каждый раз меняются? Генератор использует новые равномерные значения без фиксированного зерна (seed), поэтому результат по своей природе случаен.
Что будет, если задать σ = 0? Распределение становится вырожденным, и каждое сгенерированное значение равно среднему.
Почему выборочное среднее не точно равно μ? Случайная выборка всегда даёт ошибку выборки; чем больше чисел вы генерируете, тем ближе выборочные среднее и стандартное отклонение к μ и σ.
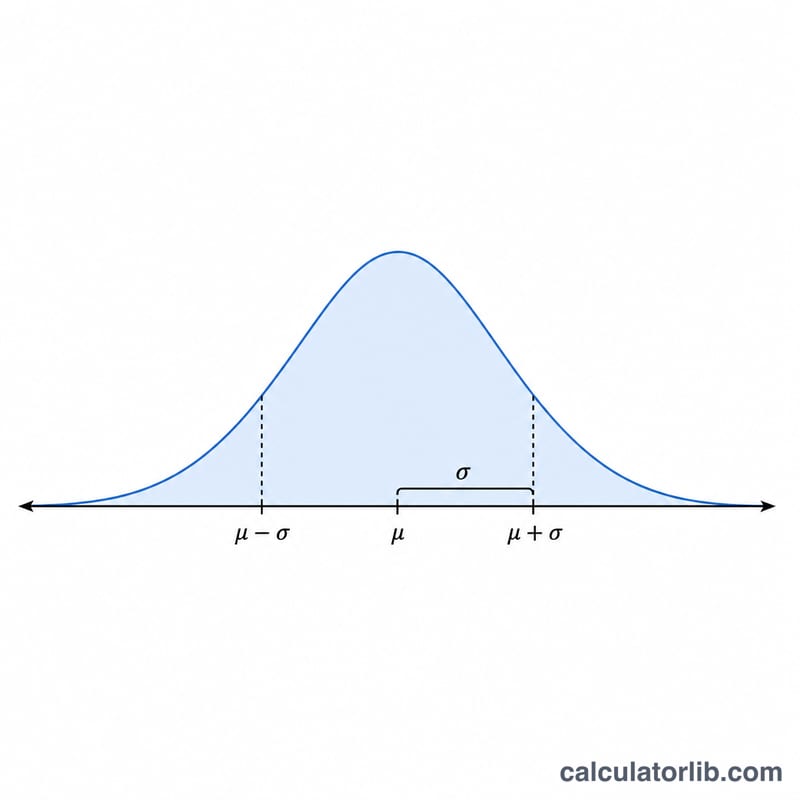
Правило 68-95-99,7 (Эмпирическое правило)
Для любого нормального распределения \(N(\mu, \sigma^2)\), предсказуемая доля значений попадает в пределы фиксированного количества стандартных отклонений от среднего. Это эмпирическое правило, и оно полезно как проверка разумности для чисел, которые вы генерируете: при достаточно большой выборке пропорции ниже должны появиться автоматически.
| Интервал | Диапазон значений | Доля внутри | Доля в хвостах |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) до \(\mu + \sigma\) | 68,27% | 31,73% |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) до \(\mu + 2\sigma\) | 95,45% | 4,55% |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) до \(\mu + 3\sigma\) | 99,73% | 0,27% |
Пример: если вы генерируете числа с \(\mu = 100\) и \(\sigma = 15\), то около 68% значений должны попасть между 85 и 115, около 95% между 70 и 130, и около 99,7% между 55 и 145. Значения вне диапазона \(\pm 3\sigma\) (ниже 55 или выше 145 в этом случае) ожидаются только около 3 раз в 1000 попыток.
Интерпретация ваших сгенерированных чисел
Преобразование Бокса-Мюллера производит значения, которые следуют нормальному (гауссовому) распределению, сосредоточенному вокруг вашего выбранного среднего \(\mu\) с разбросом, определённым вашим стандартным отклонением \(\sigma\). Читайте их, учитывая эти факты:
- Большинство значений группируются близко к среднему. Форма колокола наиболее плотна в точке \(\mu\), поэтому типичное значение близко к \(\mu\); примерно две трети значений попадают в пределы одного \(\sigma\) от него.
- Экстремальные значения редки, но возможны. Значение далеко в хвосте (скажем, за пределами \(3\sigma\)) необычно, но не невозможно — оно происходит примерно в 0,27% случаев. Появление случайного выброса является нормальным поведением, а не ошибкой.
- Выборочные статистики сходятся по мере увеличения \(n\). При небольшом количестве выборочное среднее и выборочное стандартное отклонение могут заметно отличаться от \(\mu\) и \(\sigma\) случайно. По мере того как вы увеличиваете
count, выборочное среднее приближается к \(\mu\) и выборочное стандартное отклонение приближается к \(\sigma\) (закон больших чисел). Вы можете вставить пакет в Калькулятор выборочного среднего или в Калькулятор стандартного отклонения совокупности, чтобы подтвердить, что значения смещаются к вашим целевым параметрам. - Это для моделирования и тестирования. Это псевдослучайные значения, предназначенные для экспериментов методом Монте-Карло, нагрузочного и стресс-тестирования, обучения и моделирования — не фактические измерения какой-либо реальной величины. Числа не несут эмпирического смысла помимо распределения, которое вы указали.
Определения и глоссарий
- Среднее (\(\mu\))
- Центр или математическое ожидание распределения — среднее значение, вокруг которого сбалансированы сгенерированные значения.
- Стандартное отклонение (\(\sigma\))
- Мера разброса в тех же единицах, что и данные. Большее \(\sigma\) производит значения, рассредоточенные более широко от среднего.
- Дисперсия (\(\sigma^2\))
- Квадрат стандартного отклонения, \(\sigma^2\). Она количественно определяет разброс в квадратных единицах и является параметром, который появляется в обозначении распределения \(N(\mu, \sigma^2)\).
- Стандартное нормальное распределение, \(N(0,1)\)
- Специальное нормальное распределение со средним 0 и стандартным отклонением 1. Любое значение \(Z\), полученное из него, переписывается в ваше распределение через \(X = \mu + \sigma Z\).
- Равномерное распределение
- Распределение, в котором каждое значение в интервале (здесь \((0,1)\)) равновероятно. Метод Бокса-Мюллера начинается с двух независимых равномерных значений \(U_1\) и \(U_2\).
- Z-оценка
- Знаковое число стандартных отклонений, на которое значение отстоит от среднего, \(Z = (X - \mu)/\sigma\). Z-оценка 0 находится точно на среднем; \(\pm 2\) отмечает край центральных 95,45%.
- Псевдослучайный
- Генерируется детерминированным алгоритмом, который производит последовательности со статистическими свойствами случайности. Выходные данные выглядят случайными и проходят статистические тесты, но полностью воспроизводимы из одного и того же начального значения.
- Преобразование Бокса-Мюллера
- Метод, который преобразует два независимых равномерных случайных числа \(U_1, U_2\) в стандартное нормальное значение с помощью \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\), которое затем сдвигается и масштабируется в соответствии с требуемым средним и стандартным отклонением.