यह टूल क्या करता है
यह जनरेटर छद्म-यादृच्छिक (pseudo-random) नंबरों की एक सूची बनाता है, जो आपके द्वारा चुने गए माध्य और मानक विचलन वाले सामान्य (Gaussian) वितरण का अनुसरण करती है। यह क्लासिक Box-Muller रूपांतरण का उपयोग करता है — यह एक सरल और सटीक तरीका है जो समान रूप से वितरित (uniform) यादृच्छिक नंबरों को सामान्य वितरण वाले नंबरों में बदल देता है। इसका मुख्य परिणाम है: कॉमा से अलग किए गए मानों की एक सूची, जहाँ हर मान N(μ, σ²) से लिया गया होता है।
इसका उपयोग कैसे करें
माध्य (μ) दर्ज करें — यह वितरण का केंद्र है — और मानक विचलन (σ) दर्ज करें — यह बताता है कि मान कितने फैले हुए होंगे। तय करें कि आपको कितने नंबर चाहिए (1 से 1000 तक) और प्रदर्शन की परिशुद्धता को सार्थक अंकों (significant digits) में चुनें। हर बार चलाने पर परिणाम यादृच्छिक होता है, इसलिए हर बार सबमिट करने पर आपको नंबरों का एक नया सेट मिलेगा।
सूत्र की व्याख्या
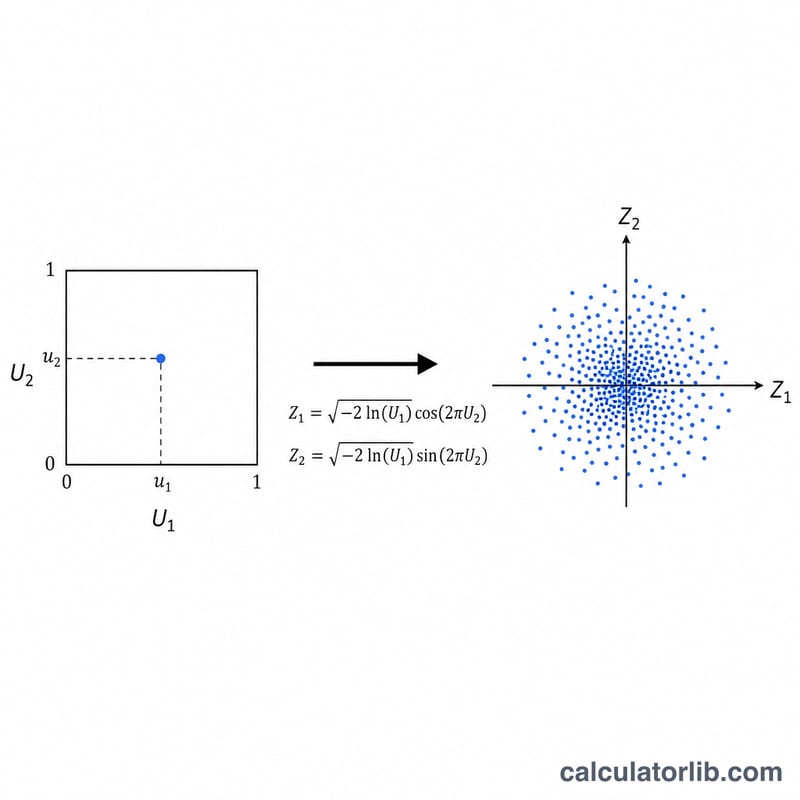
खुले अंतराल (0,1) पर दो स्वतंत्र समान संख्याएँ U1 और U2 निकालें। Box-Muller रूपांतरण इन्हें दो स्वतंत्र मानक-सामान्य (standard-normal) मानों में बदल देता है: Z1 = √(−2·ln U1)·cos(2πU2) और Z2 = √(−2·ln U1)·sin(2πU2)। इस प्रकार हर बार में एक साथ दो सामान्य मान मिलते हैं। हम हर मानक सामान्य मान को इस सूत्र से फिर से स्केल करते हैं: X = μ + σ·Z। ln(0) = −∞ से बचने के लिए, U1 को कभी भी ठीक शून्य नहीं होने दिया जाता।
हल किया हुआ उदाहरण
मान लें μ = 100, σ = 15, और U1 = 0.5, U2 = 0.25। तब √(−2·ln 0.5) = √1.386294 = 1.177410। चूँकि cos(π/2) = 0 और sin(π/2) = 1, इसलिए हमें Z1 = 0 और Z2 = 1.177410 मिलता है। तो X1 = 100 + 15·0 = 100 और X2 = 100 + 15·1.177410 = 117.66115। कई जोड़ों पर, सेट का नमूना माध्य 100 के करीब पहुँचता है और इसका नमूना मानक विचलन 15 के करीब पहुँचता है।
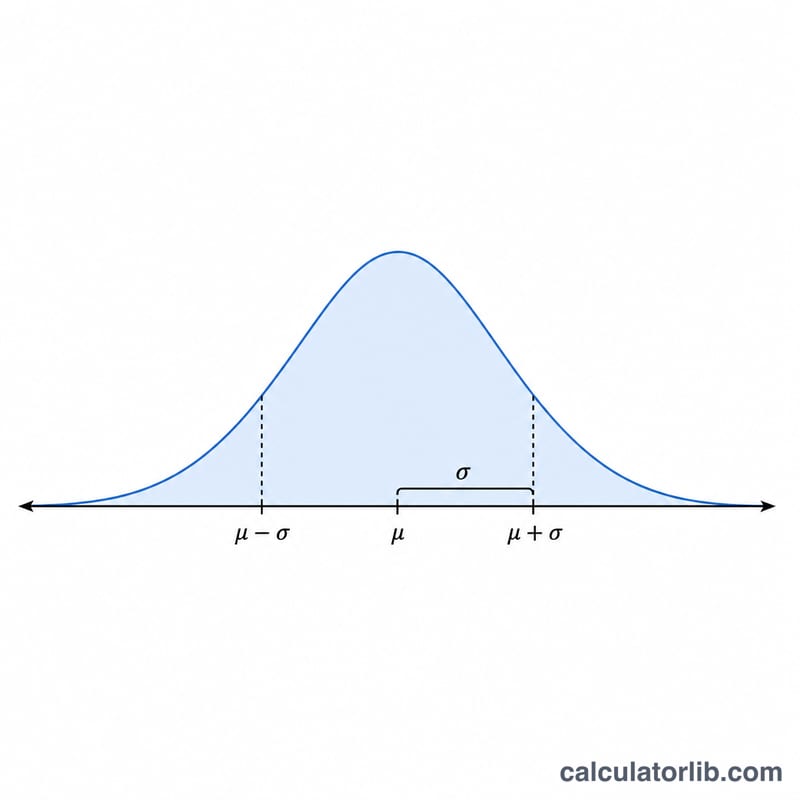
68-95-99.7 नियम (अनुभवजन्य नियम)
किसी भी सामान्य वितरण \(N(\mu, \sigma^2)\) के लिए, माध्य के मानक विचलन की एक निश्चित संख्या के भीतर मानों का एक पूर्वानुमानित हिस्सा गिरता है। यह अनुभवजन्य नियम है, और यह आपके द्वारा उत्पन्न संख्याओं के लिए एक उपयोगी विवेक जांच है: पर्याप्त बड़े नमूने के साथ, नीचे दिए गए अनुपात स्वचालित रूप से उभरेंगे।
| अंतराल | मान सीमा | अंदर का अनुपात | पूंछ में अनुपात |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) से \(\mu + \sigma\) | 68.27% | 31.73% |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) से \(\mu + 2\sigma\) | 95.45% | 4.55% |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) से \(\mu + 3\sigma\) | 99.73% | 0.27% |
उदाहरण: यदि आप \(\mu = 100\) और \(\sigma = 15\) के साथ संख्याएं उत्पन्न करते हैं, तो लगभग 68% मान 85 और 115 के बीच आना चाहिए, लगभग 95% 70 और 130 के बीच, और लगभग 99.7% 55 और 145 के बीच। \(\pm 3\sigma\) के बाहर के मान (यहाँ 55 से नीचे या 145 से ऊपर) 1,000 ड्रॉ में केवल लगभग 3 बार अपेक्षित हैं।
अपनी उत्पन्न संख्याओं की व्याख्या
बॉक्स-मुलर रूपांतर ऐसे मान उत्पन्न करता है जो आपके चुने हुए माध्य \(\mu\) पर केंद्रित एक सामान्य (गाऊसी) वितरण का पालन करते हैं और आपके मानक विचलन \(\sigma\) द्वारा निर्धारित प्रसार के साथ। इन तथ्यों को ध्यान में रखते हुए उन्हें पढ़ें:
- अधिकांश मान माध्य के पास क्लस्टर करते हैं। घंटी आकार \(\mu\) पर सबसे घना होता है, इसलिए एक विशिष्ट ड्रॉ \(\mu\) के करीब होता है; लगभग दो-तिहाई मान इसके एक \(\sigma\) के भीतर गिरते हैं।
- चरम मान दुर्लभ लेकिन संभव हैं। एक पूंछ में दूर का मान (मान लीजिए \(3\sigma\) से परे) असामान्य है, असंभव नहीं — यह लगभग 0.27% समय में होता है। कभी-कभी बाहरी मान देखना सामान्य व्यवहार है, कोई बग नहीं।
- नमूना सांख्यिकी \(n\) बढ़ने पर अभिसरित होती है। एक छोटी गणना के लिए नमूना माध्य और नमूना मानक विचलन संयोग से \(\mu\) और \(\sigma\) से ध्यान देने योग्य रूप से भिन्न हो सकते हैं। जैसे-जैसे आप
countबढ़ाते हैं, नमूना माध्य \(\mu\) के निकट आता है और नमूना SD \(\sigma\) के निकट आता है (बड़ी संख्याओं का नियम)। आप एक बैच को एक नमूना माध्य कैलकुलेटर या एक जनसंख्या मानक विचलन कैलकुलेटर में पेस्ट कर सकते हैं ताकि मानों को अपने लक्ष्यों की ओर बढ़ते देख सकें। - यह सिमुलेशन और परीक्षण के लिए है। ये मोंटे कार्लो प्रयोगों, लोड/स्ट्रेस परीक्षण, शिक्षण और मॉडलिंग के लिए अभिप्रेत छद्म-यादृच्छिक ड्रॉ हैं — किसी वास्तविक दुनिया की मात्रा के वास्तविक माप नहीं। संख्याओं का आपके द्वारा निर्दिष्ट वितरण से परे कोई अनुभवजन्य अर्थ नहीं है।
परिभाषाएँ और शब्दावली
- माध्य (\(\mu\))
- वितरण का केंद्र, या अपेक्षित मान — वह औसत जिसके चारों ओर उत्पन्न मान संतुलित हैं।
- मानक विचलन (\(\sigma\))
- डेटा के समान इकाइयों में प्रसार का एक माप। बड़ा \(\sigma\) माध्य से अधिक व्यापक रूप से बिखरे हुए मान उत्पन्न करता है।
- विचरण (\(\sigma^2\))
- मानक विचलन का वर्ग, \(\sigma^2\)। यह वर्ग की गई इकाइयों में प्रसार को परिमाणित करता है और वह पैरामीटर है जो वितरण संकेतन \(N(\mu, \sigma^2)\) में दिखाई देता है।
- मानक सामान्य, \(N(0,1)\)
- विशेष सामान्य वितरण जिसमें माध्य 0 और मानक विचलन 1 है। इससे खींचा गया कोई भी मान \(Z\) \(X = \mu + \sigma Z\) के माध्यम से आपके वितरण में पुनर्मापित किया जाता है।
- समान वितरण
- एक वितरण जिसमें एक अंतराल (यहाँ, \((0,1)\)) में प्रत्येक मान समान रूप से संभावित है। बॉक्स-मुलर विधि दो स्वतंत्र समान ड्रॉ \(U_1\) और \(U_2\) से शुरू होती है।
- Z-स्कोर
- हस्ताक्षरित संख्या में मानक विचलन एक मान माध्य से दूर है, \(Z = (X - \mu)/\sigma\)। 0 का Z-स्कोर बिल्कुल माध्य पर है; \(\pm 2\) केंद्रीय 95.45% के किनारे को चिह्नित करता है।
- छद्म-यादृच्छिक
- एक नियतात्मक एल्गोरिदम द्वारा उत्पन्न जो यादृच्छिकता के सांख्यिकीय गुणों के साथ अनुक्रम उत्पन्न करता है। आउटपुट यादृच्छिक लगता है और सांख्यिकीय परीक्षण पास करता है लेकिन एक ही बीज से पूरी तरह प्रजनक्षम है।
- बॉक्स-मुलर रूपांतर
- एक विधि जो दो स्वतंत्र समान यादृच्छिक संख्याओं \(U_1, U_2\) को \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\) का उपयोग करके एक मानक सामान्य मान में परिवर्तित करती है, जिसे तब अनुरोधित माध्य और मानक विचलन में स्थानांतरित और मापित किया जाता है।
अक्सर पूछे जाने वाले प्रश्न
हर बार नंबर क्यों बदल जाते हैं? जनरेटर बिना किसी निश्चित सीड (seed) के हर बार नई समान संख्याएँ निकालता है, इसलिए परिणाम डिज़ाइन के अनुसार यादृच्छिक होता है।
अगर मैं σ = 0 रखूँ तो क्या होगा? वितरण अपभ्रष्ट (degenerate) हो जाता है और हर जनरेट किया गया मान माध्य के बराबर होता है।
मेरा नमूना माध्य ठीक μ के बराबर क्यों नहीं होता? यादृच्छिक नमूनाकरण में नमूना त्रुटि (sampling error) होती है; आप जितने अधिक नंबर जनरेट करेंगे, नमूना माध्य और मानक विचलन उतने ही μ और σ के करीब पहुँचेंगे।